 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimits of KV Cache Compression for Tensor Attention based Autoregressive Transformers
Paper and Code
Mar 14, 2025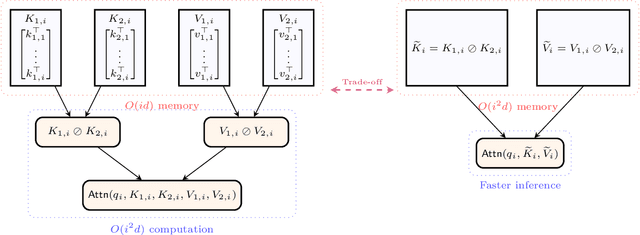
The key-value (KV) cache in autoregressive transformers presents a significant bottleneck during inference, which restricts the context length capabilities of large language models (LLMs). While previous work analyzes the fundamental space complexity barriers in standard attention mechanism [Haris and Onak, 2025], our work generalizes the space complexity barriers result to tensor attention version. Our theoretical contributions rely on a novel reduction from communication complexity and deduce the memory lower bound for tensor-structured attention mechanisms when $d = \Omega(\log n)$. In the low dimensional regime where $d = o(\log n)$, we analyze the theoretical bounds of the space complexity as well. Overall, our work provides a theoretical foundation for us to understand the compression-expressivity tradeoff in tensor attention mechanisms and offers more perspectives in developing more memory-efficient transformer architectures.