 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Chordal Sparsity for Globally Optimal Estimation with Factor Graphs
May 28, 2026Robust and efficient state estimation is crucial for perception, navigation, and control in robotics. State estimation problems are conveniently modeled using the factor-graph framework as enabled by modern software packages such as GTSAM or g2o. However, the standard solvers included in such frameworks are local and may converge to poor local minima, posing significant safety concerns. Conversely, techniques based on convex relaxations have been shown to provide a means of globally solving or certifying many state estimation problems. However, these relaxations 1) often require substantial effort to formulate, and 2) may incur significantly higher cost compared to efficient local solvers, as they require solving a large semidefinite program (SDP). In this work, we address both shortcomings by 1) creating a new procedure within the GTSAM framework for automatically constructing convex SDP relaxations for any factor graphs with common factor and variable types, and by 2) exploiting the Bayes tree constructions native to GTSAM to decompose the SDP problem, leading to significant speedup in solver time for chordally sparse problems. We demonstrate the favorable scaling of this structure-exploiting global estimator compared to standard local solvers for two case studies: A 3D pose-graph SLAM problem with a ring factor graph and a 2D localization problem with a chain factor graph. The software framework is available at https://github.com/borglab/gtsam.
Exploiting Chordal Sparsity for Fast Global Optimality with Application to Localization
Jun 04, 2024In recent years, many estimation problems in robotics have been shown to be solvable to global optimality using their semidefinite relaxations. However, the runtime complexity of off-the-shelve semidefinite programming solvers is up to cubic in problem size, which inhibits real-time solutions of problems involving large state dimensions. We show that for a large class of problems, namely those with chordal sparsity, we can reduce the complexity of these solvers to linear in problem size. In particular, we show how to replace the large positive-semidefinite variable by a number of smaller interconnected ones using the well-known chordal decomposition. This formulation also allows for the straightforward application of the alternating direction method of multipliers (ADMM), which can exploit parallelism for increased scalability. We show in simulation that the algorithms provide a significant speed up for two example problems: matrix-weighted and range-only localization.
SDPRLayers: Certifiable Backpropagation Through Polynomial Optimization Problems in Robotics
May 29, 2024Differentiable optimization is a powerful new paradigm capable of reconciling model-based and learning-based approaches in robotics. However, the majority of robotics optimization problems are non-convex and current differentiable optimization techniques are therefore prone to convergence to local minima. When this occurs, the gradients provided by these existing solvers can be wildly inaccurate and will ultimately corrupt the training process. On the other hand, any non-convex robotics problems can be framed as polynomial optimization problems and, in turn, admit convex relaxations that can be used to recover a global solution via so-called certifiably correct methods. We present SDPRLayers, an approach that leverages these methods as well as state-of-the-art convex implicit differentiation techniques to provide certifiably correct gradients throughout the training process. We introduce this approach and showcase theoretical results that provide conditions under which correctness of the gradients is guaranteed. We demonstrate our approach on two simple-but-demonstrative simulated examples, which expose the potential pitfalls of existing, state-of-the-art, differentiable optimization methods. We apply our method in a real-world application: we train a deep neural network to detect image keypoints for robot localization in challenging lighting conditions. An open-source, PyTorch implementation of SDPRLayers will be made available upon paper acceptance.
DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference
Jan 09, 2024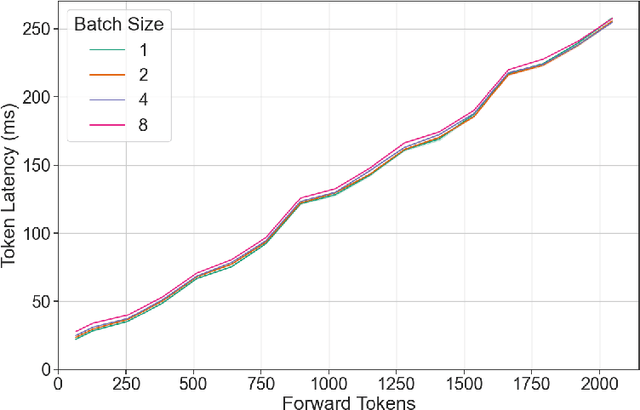
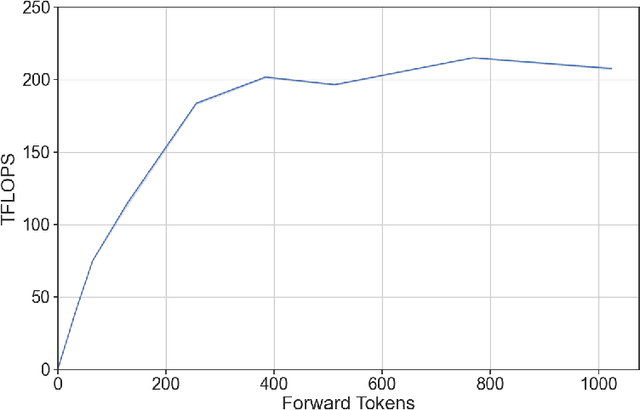
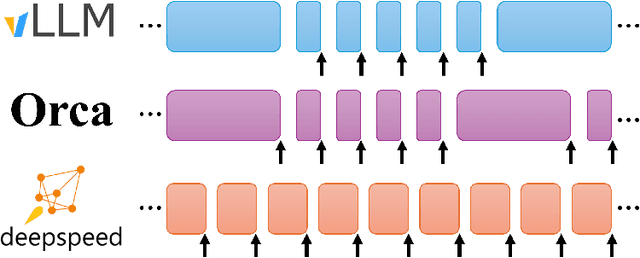
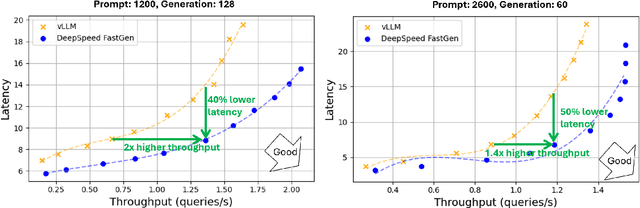
The deployment and scaling of large language models (LLMs) have become critical as they permeate various applications, demanding high-throughput and low-latency serving systems. Existing frameworks struggle to balance these requirements, especially for workloads with long prompts. This paper introduces DeepSpeed-FastGen, a system that employs Dynamic SplitFuse, a novel prompt and generation composition strategy, to deliver up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower (token-level) tail latency, compared to state-of-the-art systems like vLLM. We leverage a synergistic combination of DeepSpeed-MII and DeepSpeed-Inference to provide an efficient and easy-to-use serving system for LLMs. DeepSpeed-FastGen's advanced implementation supports a range of models and offers both non-persistent and persistent deployment options, catering to diverse user scenarios from interactive sessions to long-running applications. We present a detailed benchmarking methodology, analyze the performance through latency-throughput curves, and investigate scalability via load balancing. Our evaluations demonstrate substantial improvements in throughput and latency across various models and hardware configurations. We discuss our roadmap for future enhancements, including broader model support and new hardware backends. The DeepSpeed-FastGen code is readily available for community engagement and contribution.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
STAR-loc: Dataset for STereo And Range-based localization
Sep 11, 2023


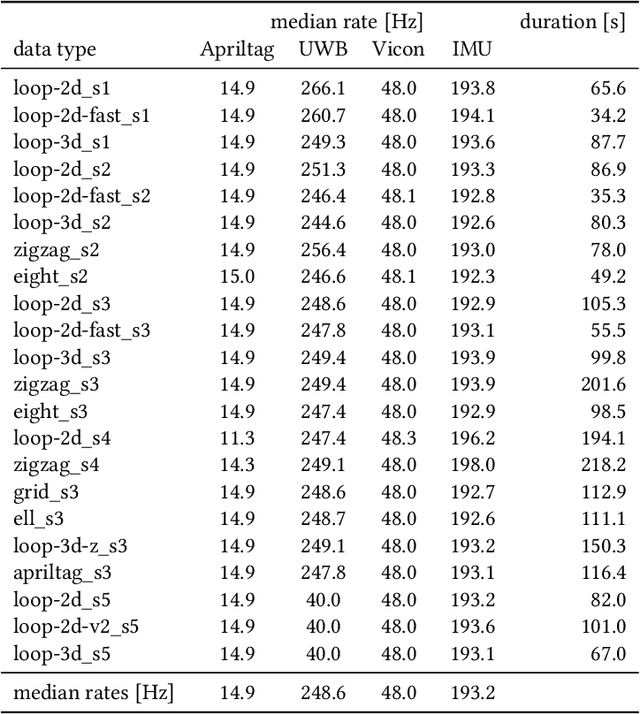
This document contains a detailed description of the STAR-loc dataset. For a quick starting guide please refer to the associated Github repository (https://github.com/utiasASRL/starloc). The dataset consists of stereo camera data (rectified/raw images and inertial measurement unit measurements) and ultra-wideband (UWB) data (range measurements) collected on a sensor rig in a Vicon motion capture arena. The UWB anchors and visual landmarks (Apriltags) are of known position, so the dataset can be used for both localization and Simultaneous Localization and Mapping (SLAM).
RenAIssance: A Survey into AI Text-to-Image Generation in the Era of Large Model
Sep 02, 2023



Text-to-image generation (TTI) refers to the usage of models that could process text input and generate high fidelity images based on text descriptions. Text-to-image generation using neural networks could be traced back to the emergence of Generative Adversial Network (GAN), followed by the autoregressive Transformer. Diffusion models are one prominent type of generative model used for the generation of images through the systematic introduction of noises with repeating steps. As an effect of the impressive results of diffusion models on image synthesis, it has been cemented as the major image decoder used by text-to-image models and brought text-to-image generation to the forefront of machine-learning (ML) research. In the era of large models, scaling up model size and the integration with large language models have further improved the performance of TTI models, resulting the generation result nearly indistinguishable from real-world images, revolutionizing the way we retrieval images. Our explorative study has incentivised us to think that there are further ways of scaling text-to-image models with the combination of innovative model architectures and prediction enhancement techniques. We have divided the work of this survey into five main sections wherein we detail the frameworks of major literature in order to delve into the different types of text-to-image generation methods. Following this we provide a detailed comparison and critique of these methods and offer possible pathways of improvement for future work. In the future work, we argue that TTI development could yield impressive productivity improvements for creation, particularly in the context of the AIGC era, and could be extended to more complex tasks such as video generation and 3D generation.
Certifiably Optimal Rotation and Pose Estimation Based on the Cayley Map
Aug 23, 2023We present novel, tight, convex relaxations for rotation and pose estimation problems that can guarantee global optimality via strong Lagrangian duality. Some such relaxations exist in the literature for specific problem setups that assume the matrix von Mises-Fisher distribution (a.k.a., matrix Langevin distribution or chordal distance) for isotropic rotational uncertainty. However, another common way to represent uncertainty for rotations and poses is to define anisotropic noise in the associated Lie algebra. Starting from a noise model based on the Cayley map, we define our estimation problems, convert them to Quadratically Constrained Quadratic Programs (QCQPs), then relax them to Semidefinite Programs (SDPs), which can be solved using standard interior-point optimization methods. We first show how to carry out basic rotation and pose averaging. We then turn to the more complex problem of trajectory estimation, which involves many pose variables with both individual and inter-pose measurements (or motion priors). Our contribution is to formulate SDP relaxations for all these problems, including the identification of sufficient redundant constraints to make them tight. We hope our results can add to the catalogue of useful estimation problems whose global optimality can be guaranteed.
On Semidefinite Relaxations for Matrix-Weighted State-Estimation Problems in Robotics
Aug 14, 2023



In recent years, there has been remarkable progress in the development of so-called certifiable perception methods, which leverage semidefinite, convex relaxations to find global optima of perception problems in robotics. However, many of these relaxations rely on simplifying assumptions that facilitate the problem formulation, such as an isotropic measurement noise distribution. In this paper, we explore the tightness of the semidefinite relaxations of matrix-weighted (anisotropic) state-estimation problems and reveal the limitations lurking therein: matrix-weighted factors can cause convex relaxations to lose tightness. In particular, we show that the semidefinite relaxations of localization problems with matrix weights may be tight only for low noise levels. We empirically explore the factors that contribute to this loss of tightness and demonstrate that redundant constraints can be used to regain tightness, albeit at the expense of real-time performance. As a second technical contribution of this paper, we show that the state-of-the-art relaxation of scalar-weighted SLAM cannot be used when matrix weights are considered. We provide an alternate formulation and show that its SDP relaxation is not tight (even for very low noise levels) unless specific redundant constraints are used. We demonstrate the tightness of our formulations on both simulated and real-world data.
Toward Globally Optimal State Estimation Using Automatically Tightened Semidefinite Relaxations
Aug 10, 2023In recent years, semidefinite relaxations of common optimization problems in robotics have attracted growing attention due to their ability to provide globally optimal solutions. In many cases, specific handcrafted redundant constraints are added to the relaxation in order to improve its tightness, which is usually a requirement for obtaining or certifying globally optimal solutions. These constraints are formulation-dependent and typically require a lengthy manual process to find. Instead, the present paper suggests an automatic method to find a set of sufficient redundant constraints to obtain tightness, if they exist. We first propose an efficient feasibility check to determine if a given set of variables can lead to a tight formulation. Secondly, we show how to scale the method to problems of bigger size. At no point of the entire process do we have to manually find redundant constraints. We showcase the effectiveness of the approach by providing new insights on two classical robotics problems: range-based localization and stereo-based pose estimation. Finally, we reproduce semidefinite relaxations presented in recent literature and show that our automatic method finds a smaller set of constraints sufficient for tightness than previously considered.