 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference
Paper and Code
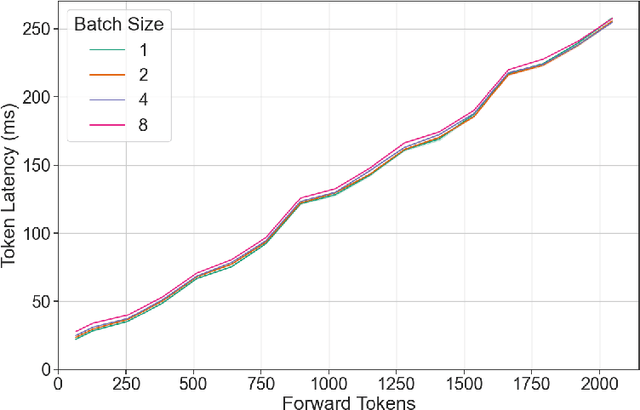
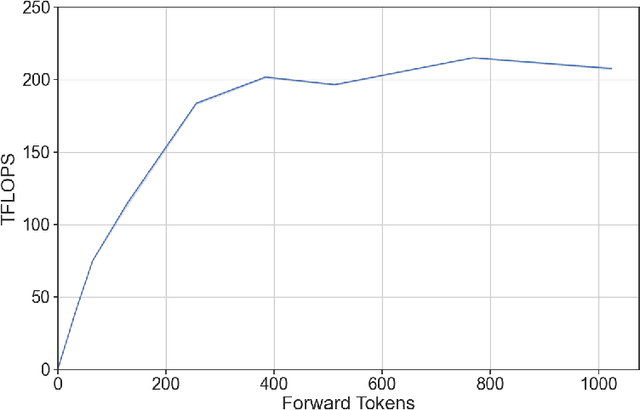
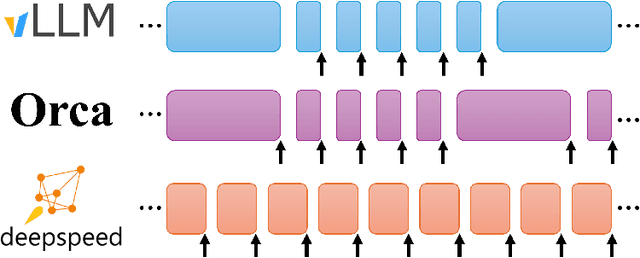
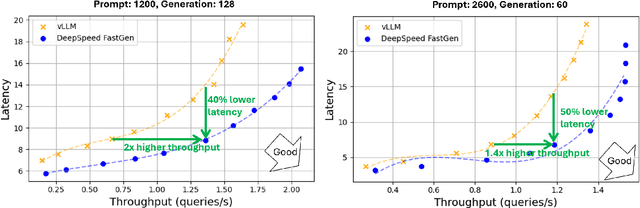
The deployment and scaling of large language models (LLMs) have become critical as they permeate various applications, demanding high-throughput and low-latency serving systems. Existing frameworks struggle to balance these requirements, especially for workloads with long prompts. This paper introduces DeepSpeed-FastGen, a system that employs Dynamic SplitFuse, a novel prompt and generation composition strategy, to deliver up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower (token-level) tail latency, compared to state-of-the-art systems like vLLM. We leverage a synergistic combination of DeepSpeed-MII and DeepSpeed-Inference to provide an efficient and easy-to-use serving system for LLMs. DeepSpeed-FastGen's advanced implementation supports a range of models and offers both non-persistent and persistent deployment options, catering to diverse user scenarios from interactive sessions to long-running applications. We present a detailed benchmarking methodology, analyze the performance through latency-throughput curves, and investigate scalability via load balancing. Our evaluations demonstrate substantial improvements in throughput and latency across various models and hardware configurations. We discuss our roadmap for future enhancements, including broader model support and new hardware backends. The DeepSpeed-FastGen code is readily available for community engagement and contribution.