 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-MAP: A DQN Framework for Exploring Distributed Execution Plans for DNN Workloads
Jul 08, 2020



The last decade has witnessed growth in the computational requirements for training deep neural networks. Current approaches (e.g., data/model parallelism, pipeline parallelism) parallelize training tasks onto multiple devices. However, these approaches always rely on specific deep learning frameworks and requires elaborate manual design, which make it difficult to maintain and share between different type of models. In this paper, we propose Auto-MAP, a framework for exploring distributed execution plans for DNN workloads, which can automatically discovering fast parallelization strategies through reinforcement learning on IR level of deep learning models. Efficient exploration remains a major challenge for reinforcement learning. We leverage DQN with task-specific pruning strategies to help efficiently explore the search space including optimized strategies. Our evaluation shows that Auto-MAP can find the optimal solution in two hours, while achieving better throughput on several NLP and convolution models.
DaSGD: Squeezing SGD Parallelization Performance in Distributed Training Using Delayed Averaging
May 31, 2020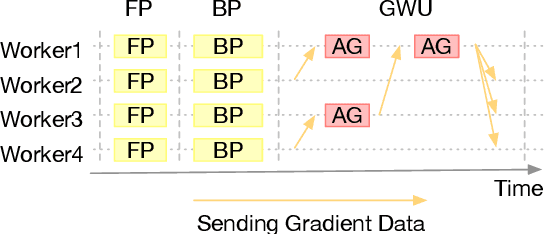
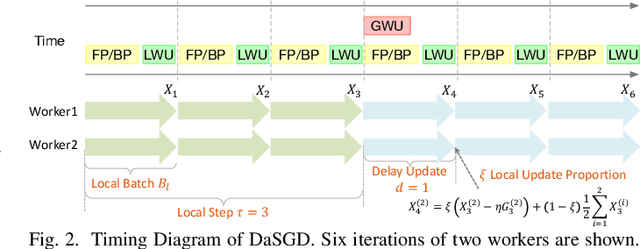
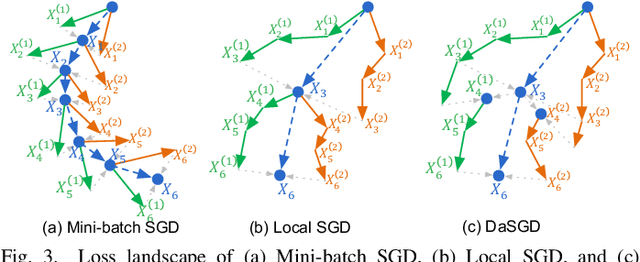
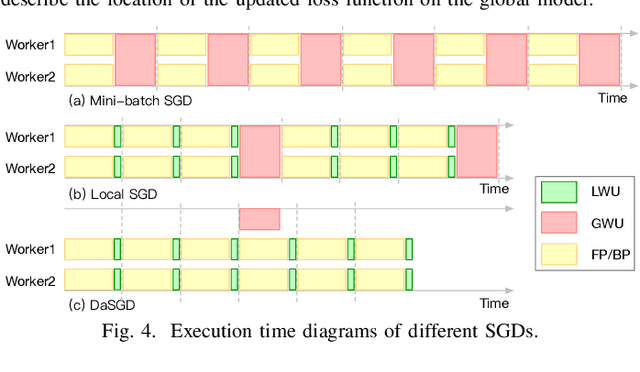
The state-of-the-art deep learning algorithms rely on distributed training systems to tackle the increasing sizes of models and training data sets. Minibatch stochastic gradient descent (SGD) algorithm requires workers to halt forward/back propagations, to wait for gradients aggregated from all workers, and to receive weight updates before the next batch of tasks. This synchronous execution model exposes the overheads of gradient/weight communication among a large number of workers in a distributed training system. We propose a new SGD algorithm, DaSGD (Local SGD with Delayed Averaging), which parallelizes SGD and forward/back propagations to hide 100% of the communication overhead. By adjusting the gradient update scheme, this algorithm uses hardware resources more efficiently and reduces the reliance on the low-latency and high-throughput inter-connects. The theoretical analysis and the experimental results show its convergence rate O(1/sqrt(K)), the same as SGD. The performance evaluation demonstrates it enables a linear performance scale-up with the cluster size.