 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecast-Then-Optimize Deep Learning Methods
Jun 16, 2025Time series forecasting underpins vital decision-making across various sectors, yet raw predictions from sophisticated models often harbor systematic errors and biases. We examine the Forecast-Then-Optimize (FTO) framework, pioneering its systematic synopsis. Unlike conventional Predict-Then-Optimize (PTO) methods, FTO explicitly refines forecasts through optimization techniques such as ensemble methods, meta-learners, and uncertainty adjustments. Furthermore, deep learning and large language models have established superiority over traditional parametric forecasting models for most enterprise applications. This paper surveys significant advancements from 2016 to 2025, analyzing mainstream deep learning FTO architectures. Focusing on real-world applications in operations management, we demonstrate FTO's crucial role in enhancing predictive accuracy, robustness, and decision efficacy. Our study establishes foundational guidelines for future forecasting methodologies, bridging theory and operational practicality.
BatchLLM: Optimizing Large Batched LLM Inference with Global Prefix Sharing and Throughput-oriented Token Batching
Nov 29, 2024Many LLM tasks are performed in large batches or even offline, and the performance indictor for which is throughput. These tasks usually show the characteristic of prefix sharing, where different prompt input can partially show the common prefix. However, the existing LLM inference engines tend to optimize the streaming requests and show limitations of supporting the large batched tasks with the prefix sharing characteristic. The existing solutions use the LRU-based cache to reuse the KV context of common prefix. The KV context that is about to be reused may prematurely be evicted with the implicit cache management. Even if not evicted, the lifetime of the shared KV context is extended since requests sharing the same context are not scheduled together, resulting in larger memory usage. These streaming oriented systems schedule the requests in the first-come-first-serve or similar order. As a result, the requests with larger ratio of decoding steps may be scheduled too late to be able to mix with the prefill chunks to increase the hardware utilization. Besides, the token and request number based batching can limit the size of token-batch, which keeps the GPU from saturating for the iterations dominated by decoding tokens. We propose BatchLLM to address the above problems. BatchLLM explicitly identifies the common prefixes globally. The requests sharing the same prefix will be scheduled together to reuse the KV context the best, which also shrinks the lifetime of common KV memory. BatchLLM reorders the requests and schedules the requests with larger ratio of decoding first to better mix the decoding tokens with the latter prefill chunks and applies memory-centric token batching to enlarge the token-batch sizes, which helps to increase the GPU utilization. Extensive evaluation shows that BatchLLM outperforms vLLM by 1.1x to 2x on a set of microbenchmarks and two typical industry workloads.
Cross-Domain Image Retrieval with Attention Modeling
Sep 06, 2017


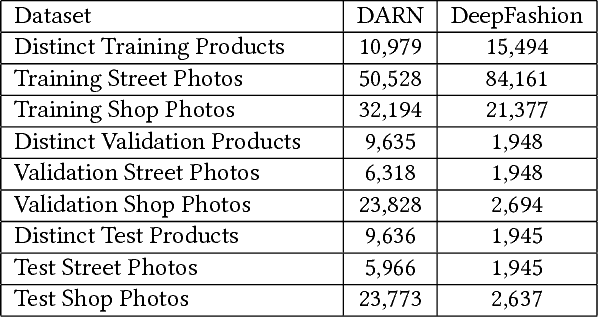
With the proliferation of e-commerce websites and the ubiquitousness of smart phones, cross-domain image retrieval using images taken by smart phones as queries to search products on e-commerce websites is emerging as a popular application. One challenge of this task is to locate the attention of both the query and database images. In particular, database images, e.g. of fashion products, on e-commerce websites are typically displayed with other accessories, and the images taken by users contain noisy background and large variations in orientation and lighting. Consequently, their attention is difficult to locate. In this paper, we exploit the rich tag information available on the e-commerce websites to locate the attention of database images. For query images, we use each candidate image in the database as the context to locate the query attention. Novel deep convolutional neural network architectures, namely TagYNet and CtxYNet, are proposed to learn the attention weights and then extract effective representations of the images. Experimental results on public datasets confirm that our approaches have significant improvement over the existing methods in terms of the retrieval accuracy and efficiency.
* 8 pages with an extra reference page