 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Adaptive Kernelization for Nonlinear Max-margin Multi-view Learning
Oct 11, 2019



Existing multi-view learning methods based on kernel function either require the user to select and tune a single predefined kernel or have to compute and store many Gram matrices to perform multiple kernel learning. Apart from the huge consumption of manpower, computation and memory resources, most of these models seek point estimation of their parameters, and are prone to overfitting to small training data. This paper presents an adaptive kernel nonlinear max-margin multi-view learning model under the Bayesian framework. Specifically, we regularize the posterior of an efficient multi-view latent variable model by explicitly mapping the latent representations extracted from multiple data views to a random Fourier feature space where max-margin classification constraints are imposed. Assuming these random features are drawn from Dirichlet process Gaussian mixtures, we can adaptively learn shift-invariant kernels from data according to Bochners theorem. For inference, we employ the data augmentation idea for hinge loss, and design an efficient gradient-based MCMC sampler in the augmented space. Having no need to compute the Gram matrix, our algorithm scales linearly with the size of training set. Extensive experiments on real-world datasets demonstrate that our method has superior performance.
Learning beyond Predefined Label Space via Bayesian Nonparametric Topic Modelling
Oct 10, 2019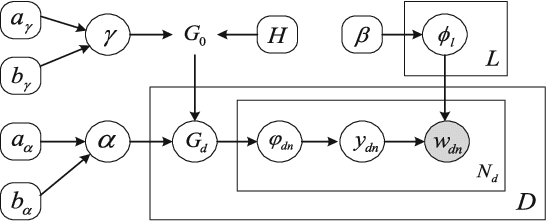

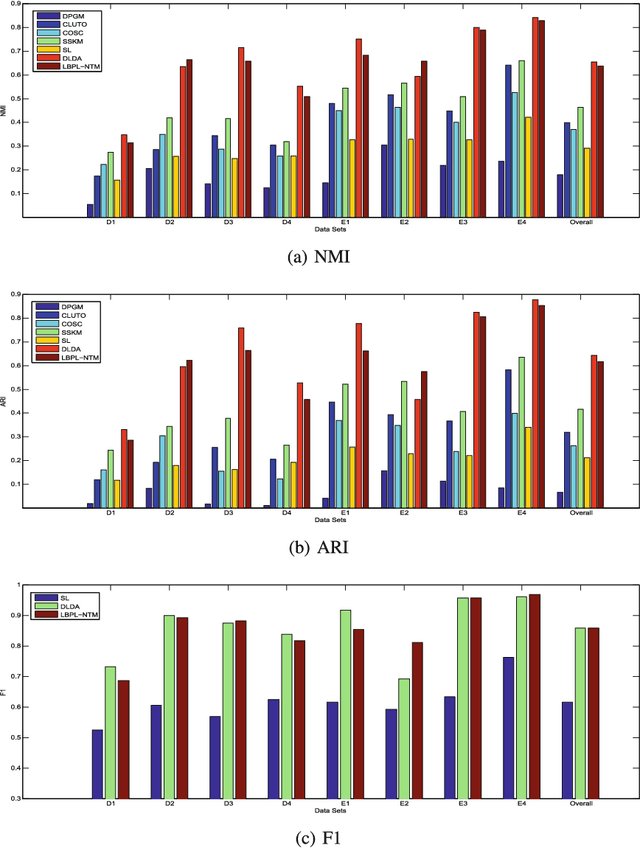
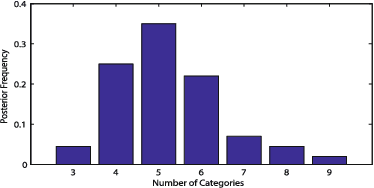
In real world machine learning applications, testing data may contain some meaningful new categories that have not been seen in labeled training data. To simultaneously recognize new data categories and assign most appropriate category labels to the data actually from known categories, existing models assume the number of unknown new categories is pre-specified, though it is difficult to determine in advance. In this paper, we propose a Bayesian nonparametric topic model to automatically infer this number, based on the hierarchical Dirichlet process and the notion of latent Dirichlet allocation. Exact inference in our model is intractable, so we provide an efficient collapsed Gibbs sampling algorithm for approximate posterior inference. Extensive experiments on various text data sets show that: (a) compared with parametric approaches that use pre-specified true number of new categories, the proposed nonparametric approach can yield comparable performance; and (b) when the exact number of new categories is unavailable, i.e. the parametric approaches only have a rough idea about the new categories, our approach has evident performance advantages.
Semi-supervised Deep Generative Modelling of Incomplete Multi-Modality Emotional Data
Jul 27, 2018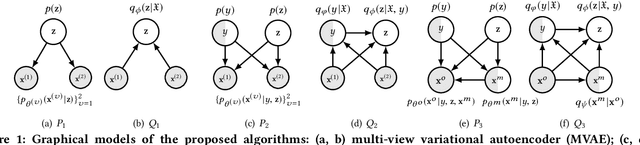

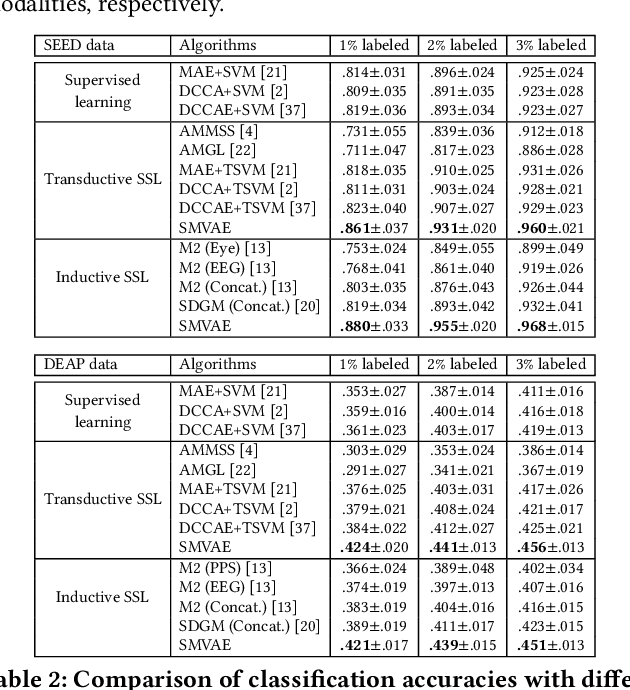
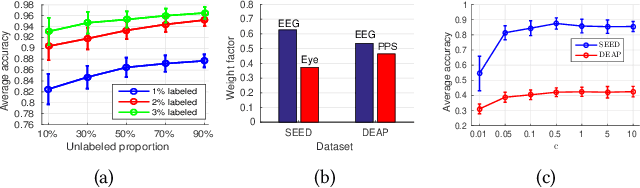
There are threefold challenges in emotion recognition. First, it is difficult to recognize human's emotional states only considering a single modality. Second, it is expensive to manually annotate the emotional data. Third, emotional data often suffers from missing modalities due to unforeseeable sensor malfunction or configuration issues. In this paper, we address all these problems under a novel multi-view deep generative framework. Specifically, we propose to model the statistical relationships of multi-modality emotional data using multiple modality-specific generative networks with a shared latent space. By imposing a Gaussian mixture assumption on the posterior approximation of the shared latent variables, our framework can learn the joint deep representation from multiple modalities and evaluate the importance of each modality simultaneously. To solve the labeled-data-scarcity problem, we extend our multi-view model to semi-supervised learning scenario by casting the semi-supervised classification problem as a specialized missing data imputation task. To address the missing-modality problem, we further extend our semi-supervised multi-view model to deal with incomplete data, where a missing view is treated as a latent variable and integrated out during inference. This way, the proposed overall framework can utilize all available (both labeled and unlabeled, as well as both complete and incomplete) data to improve its generalization ability. The experiments conducted on two real multi-modal emotion datasets demonstrated the superiority of our framework.
Sharing deep generative representation for perceived image reconstruction from human brain activity
Jul 11, 2017



Decoding human brain activities via functional magnetic resonance imaging (fMRI) has gained increasing attention in recent years. While encouraging results have been reported in brain states classification tasks, reconstructing the details of human visual experience still remains difficult. Two main challenges that hinder the development of effective models are the perplexing fMRI measurement noise and the high dimensionality of limited data instances. Existing methods generally suffer from one or both of these issues and yield dissatisfactory results. In this paper, we tackle this problem by casting the reconstruction of visual stimulus as the Bayesian inference of missing view in a multiview latent variable model. Sharing a common latent representation, our joint generative model of external stimulus and brain response is not only "deep" in extracting nonlinear features from visual images, but also powerful in capturing correlations among voxel activities of fMRI recordings. The nonlinearity and deep structure endow our model with strong representation ability, while the correlations of voxel activities are critical for suppressing noise and improving prediction. We devise an efficient variational Bayesian method to infer the latent variables and the model parameters. To further improve the reconstruction accuracy, the latent representations of testing instances are enforced to be close to that of their neighbours from the training set via posterior regularization. Experiments on three fMRI recording datasets demonstrate that our approach can more accurately reconstruct visual stimuli.
Semi-supervised Bayesian Deep Multi-modal Emotion Recognition
Apr 25, 2017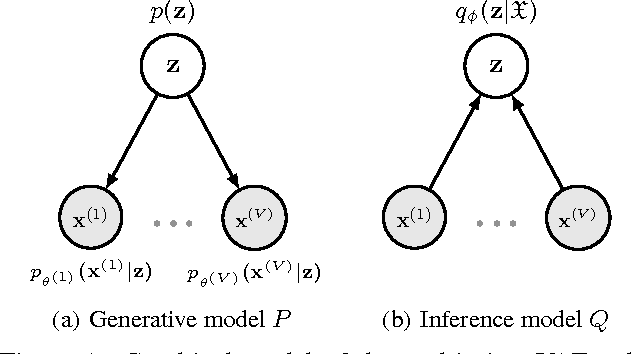


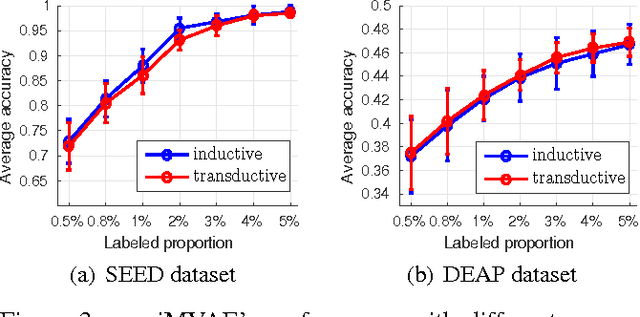
In emotion recognition, it is difficult to recognize human's emotional states using just a single modality. Besides, the annotation of physiological emotional data is particularly expensive. These two aspects make the building of effective emotion recognition model challenging. In this paper, we first build a multi-view deep generative model to simulate the generative process of multi-modality emotional data. By imposing a mixture of Gaussians assumption on the posterior approximation of the latent variables, our model can learn the shared deep representation from multiple modalities. To solve the labeled-data-scarcity problem, we further extend our multi-view model to semi-supervised learning scenario by casting the semi-supervised classification problem as a specialized missing data imputation task. Our semi-supervised multi-view deep generative framework can leverage both labeled and unlabeled data from multiple modalities, where the weight factor for each modality can be learned automatically. Compared with previous emotion recognition methods, our method is more robust and flexible. The experiments conducted on two real multi-modal emotion datasets have demonstrated the superiority of our framework over a number of competitors.