 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAD: On-line Anomaly Detection for Highly Unreliable Data
Paper and Code
Nov 11, 2019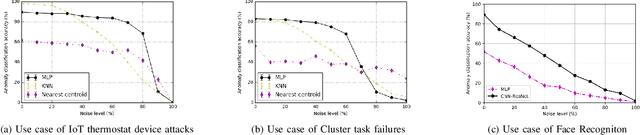
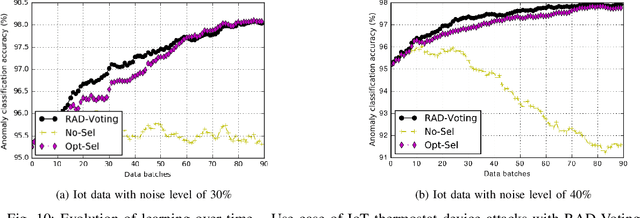
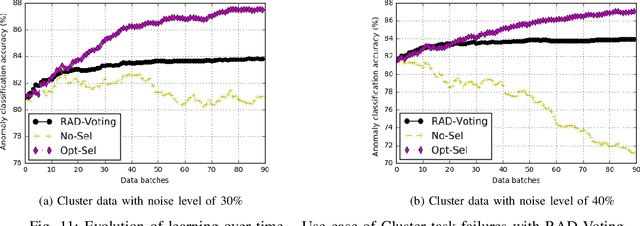
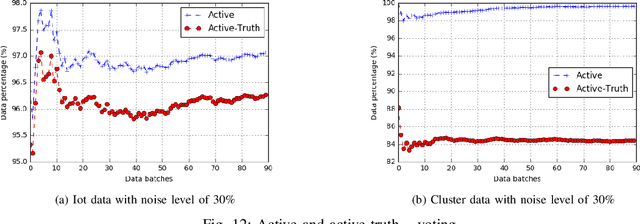
Classification algorithms have been widely adopted to detect anomalies for various systems, e.g., IoT, cloud and face recognition, under the common assumption that the data source is clean, i.e., features and labels are correctly set. However, data collected from the wild can be unreliable due to careless annotations or malicious data transformation for incorrect anomaly detection. In this paper, we present a two-layer on-line learning framework for robust anomaly detection (RAD) in the presence of unreliable anomaly labels, where the first layer is to filter out the suspicious data, and the second layer detects the anomaly patterns from the remaining data. To adapt to the on-line nature of anomaly detection, we extend RAD with additional features of repetitively cleaning, conflicting opinions of classifiers, and oracle knowledge. We on-line learn from the incoming data streams and continuously cleanse the data, so as to adapt to the increasing learning capacity from the larger accumulated data set. Moreover, we explore the concept of oracle learning that provides additional information of true labels for difficult data points. We specifically focus on three use cases, (i) detecting 10 classes of IoT attacks, (ii) predicting 4 classes of task failures of big data jobs, (iii) recognising 20 celebrities faces. Our evaluation results show that RAD can robustly improve the accuracy of anomaly detection, to reach up to 98% for IoT device attacks (i.e., +11%), up to 84% for cloud task failures (i.e., +20%) under 40% noise, and up to 74% for face recognition (i.e., +28%) under 30% noisy labels. The proposed RAD is general and can be applied to different anomaly detection algorithms.