 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-Based Conditional Flow Models for MIMO Receiver Design with Superimposed Pilots
Feb 25, 2026Accurate channel state information (CSI) is vital for multiple-input multiple-output (MIMO) systems. However, superimposed pilots (SIP), which reduce overhead, introduce severe pilot contamination and data interference, complicating joint channel estimation and data detection. This paper proposes a conditional flow matching receiver (CFM-Rx), an unsupervised generative framework that learns directly from received signals, eliminating the need for labeled data and improving adaptability across diverse system settings. By leveraging flow-based generative modeling, CFM-Rx enables deterministic, low-latency inference and exploits model invertibility to capture the bidirectional nature of signal propagation. This framework unifies flow matching with score-based diffusion modeling via a moment-consistent ordinary differential equation (ODE), replacing stochastic differential equation (SDE) sampling with a deterministic and efficient process. Furthermore, it integrates receiver-side priors to ensure stable, data-consistent inference. Extensive simulation results across various MIMO configurations demonstrate that CFM-Rx consistently outperforms conventional estimators and state-of-the-art data-driven receivers, achieving notable gains in channel estimation accuracy and symbol detection robustness, particularly under severe pilot contamination.
KuaiSearch: A Large-Scale E-Commerce Search Dataset for Recall, Ranking, and Relevance
Feb 12, 2026E-commerce search serves as a central interface, connecting user demands with massive product inventories and plays a vital role in our daily lives. However, in real-world applications, it faces challenges, including highly ambiguous queries, noisy product texts with weak semantic order, and diverse user preferences, all of which make it difficult to accurately capture user intent and fine-grained product semantics. In recent years, significant advances in large language models (LLMs) for semantic representation and contextual reasoning have created new opportunities to address these challenges. Nevertheless, existing e-commerce search datasets still suffer from notable limitations: queries are often heuristically constructed, cold-start users and long-tail products are filtered out, query and product texts are anonymized, and most datasets cover only a single stage of the search pipeline. Collectively, these issues constrain research on LLM-based e-commerce search. To address these challenges, we construct and release KuaiSearch. To the best of our knowledge, it is the largest e-commerce search dataset currently available. KuaiSearch is built upon real user search interactions from the Kuaishou platform, preserving authentic user queries and natural-language product texts, covering cold-start users and long-tail products, and systematically spanning three key stages of the search pipeline: recall, ranking, and relevance judgment. We conduct a comprehensive analysis of KuaiSearch from multiple perspectives, including products, users, and queries, and establish benchmark experiments across several representative search tasks. Experimental results demonstrate that KuaiSearch provides a valuable foundation for research on real-world e-commerce search.
BLADE: A Behavior-Level Data Augmentation Framework with Dual Fusion Modeling for Multi-Behavior Sequential Recommendation
Dec 15, 2025Multi-behavior sequential recommendation aims to capture users' dynamic interests by modeling diverse types of user interactions over time. Although several studies have explored this setting, the recommendation performance remains suboptimal, mainly due to two fundamental challenges: the heterogeneity of user behaviors and data sparsity. To address these challenges, we propose BLADE, a framework that enhances multi-behavior modeling while mitigating data sparsity. Specifically, to handle behavior heterogeneity, we introduce a dual item-behavior fusion architecture that incorporates behavior information at both the input and intermediate levels, enabling preference modeling from multiple perspectives. To mitigate data sparsity, we design three behavior-level data augmentation methods that operate directly on behavior sequences rather than core item sequences. These methods generate diverse augmented views while preserving the semantic consistency of item sequences. These augmented views further enhance representation learning and generalization via contrastive learning. Experiments on three real-world datasets demonstrate the effectiveness of our approach.
Benchmarking Multimodal LLMs on Recognition and Understanding over Chemical Tables
Jun 13, 2025Chemical tables encode complex experimental knowledge through symbolic expressions, structured variables, and embedded molecular graphics. Existing benchmarks largely overlook this multimodal and domain-specific complexity, limiting the ability of multimodal large language models to support scientific understanding in chemistry. In this work, we introduce ChemTable, a large-scale benchmark of real-world chemical tables curated from the experimental sections of literature. ChemTable includes expert-annotated cell polygons, logical layouts, and domain-specific labels, including reagents, catalysts, yields, and graphical components and supports two core tasks: (1) Table Recognition, covering structure parsing and content extraction; and (2) Table Understanding, encompassing both descriptive and reasoning-oriented question answering grounded in table structure and domain semantics. We evaluated a range of representative multimodal models, including both open-source and closed-source models, on ChemTable and reported a series of findings with practical and conceptual insights. Although models show reasonable performance on basic layout parsing, they exhibit substantial limitations on both descriptive and inferential QA tasks compared to human performance, and we observe significant performance gaps between open-source and closed-source models across multiple dimensions. These results underscore the challenges of chemistry-aware table understanding and position ChemTable as a rigorous and realistic benchmark for advancing scientific reasoning.
Mixture of Attention Yields Accurate Results for Tabular Data
Feb 18, 2025



Tabular data inherently exhibits significant feature heterogeneity, but existing transformer-based methods lack specialized mechanisms to handle this property. To bridge the gap, we propose MAYA, an encoder-decoder transformer-based framework. In the encoder, we design a Mixture of Attention (MOA) that constructs multiple parallel attention branches and averages the features at each branch, effectively fusing heterogeneous features while limiting parameter growth. Additionally, we employ collaborative learning with a dynamic consistency weight constraint to produce more robust representations. In the decoder stage, cross-attention is utilized to seamlessly integrate tabular data with corresponding label features. This dual-attention mechanism effectively captures both intra-instance and inter-instance interactions. We evaluate the proposed method on a wide range of datasets and compare it with other state-of-the-art transformer-based methods. Extensive experiments demonstrate that our model achieves superior performance among transformer-based methods in both tabular classification and regression tasks.
Augmenting Channel Simulator and Semi- Supervised Learning for Efficient Indoor Positioning
Aug 01, 2024



This work aims to tackle the labor-intensive and resource-consuming task of indoor positioning by proposing an efficient approach. The proposed approach involves the introduction of a semi-supervised learning (SSL) with a biased teacher (SSLB) algorithm, which effectively utilizes both labeled and unlabeled channel data. To reduce measurement expenses, unlabeled data is generated using an updated channel simulator (UCHS), and then weighted by adaptive confidence values to simplify the tuning of hyperparameters. Simulation results demonstrate that the proposed strategy achieves superior performance while minimizing measurement overhead and training expense compared to existing benchmarks, offering a valuable and practical solution for indoor positioning.
Channel Modeling Aided Dataset Generation for AI-Enabled CSI Feedback: Advances, Challenges, and Solutions
Jul 01, 2024



The AI-enabled autoencoder has demonstrated great potential in channel state information (CSI) feedback in frequency division duplex (FDD) multiple input multiple output (MIMO) systems. However, this method completely changes the existing feedback strategies, making it impractical to deploy in recent years. To address this issue, this paper proposes a channel modeling aided data augmentation method based on a limited number of field channel data. Specifically, the user equipment (UE) extracts the primary stochastic parameters of the field channel data and transmits them to the base station (BS). The BS then updates the typical TR 38.901 model parameters with the extracted parameters. In this way, the updated channel model is used to generate the dataset. This strategy comprehensively considers the dataset collection, model generalization, model monitoring, and so on. Simulations verify that our proposed strategy can significantly improve performance compared to the benchmarks.
MCFEND: A Multi-source Benchmark Dataset for Chinese Fake News Detection
Mar 14, 2024
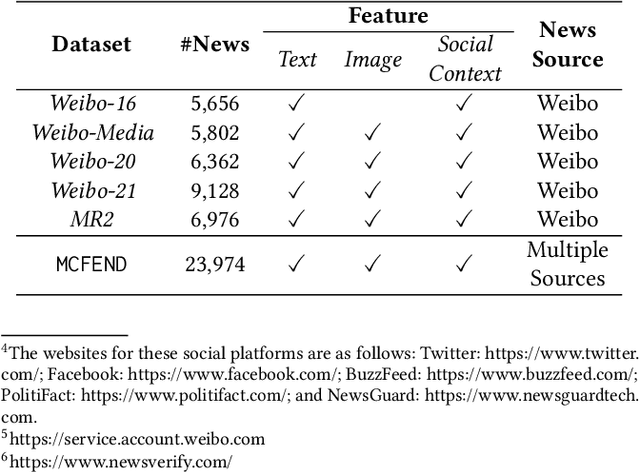
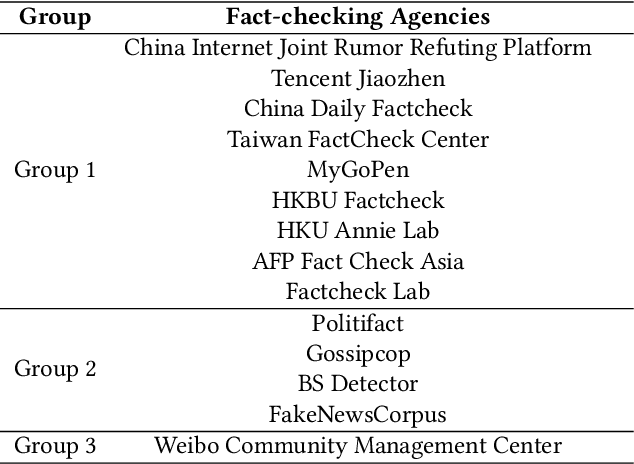
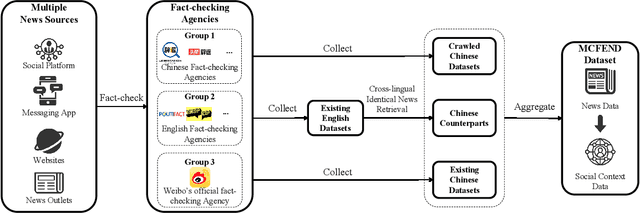
The prevalence of fake news across various online sources has had a significant influence on the public. Existing Chinese fake news detection datasets are limited to news sourced solely from Weibo. However, fake news originating from multiple sources exhibits diversity in various aspects, including its content and social context. Methods trained on purely one single news source can hardly be applicable to real-world scenarios. Our pilot experiment demonstrates that the F1 score of the state-of-the-art method that learns from a large Chinese fake news detection dataset, Weibo-21, drops significantly from 0.943 to 0.470 when the test data is changed to multi-source news data, failing to identify more than one-third of the multi-source fake news. To address this limitation, we constructed the first multi-source benchmark dataset for Chinese fake news detection, termed MCFEND, which is composed of news we collected from diverse sources such as social platforms, messaging apps, and traditional online news outlets. Notably, such news has been fact-checked by 14 authoritative fact-checking agencies worldwide. In addition, various existing Chinese fake news detection methods are thoroughly evaluated on our proposed dataset in cross-source, multi-source, and unseen source ways. MCFEND, as a benchmark dataset, aims to advance Chinese fake news detection approaches in real-world scenarios.
A 5' UTR Language Model for Decoding Untranslated Regions of mRNA and Function Predictions
Oct 06, 2023The 5' UTR, a regulatory region at the beginning of an mRNA molecule, plays a crucial role in regulating the translation process and impacts the protein expression level. Language models have showcased their effectiveness in decoding the functions of protein and genome sequences. Here, we introduced a language model for 5' UTR, which we refer to as the UTR-LM. The UTR-LM is pre-trained on endogenous 5' UTRs from multiple species and is further augmented with supervised information including secondary structure and minimum free energy. We fine-tuned the UTR-LM in a variety of downstream tasks. The model outperformed the best-known benchmark by up to 42% for predicting the Mean Ribosome Loading, and by up to 60% for predicting the Translation Efficiency and the mRNA Expression Level. The model also applies to identifying unannotated Internal Ribosome Entry Sites within the untranslated region and improves the AUPR from 0.37 to 0.52 compared to the best baseline. Further, we designed a library of 211 novel 5' UTRs with high predicted values of translation efficiency and evaluated them via a wet-lab assay. Experiment results confirmed that our top designs achieved a 32.5% increase in protein production level relative to well-established 5' UTR optimized for therapeutics.
A Survey of Machine Learning-Based Ride-Hailing Planning
Mar 26, 2023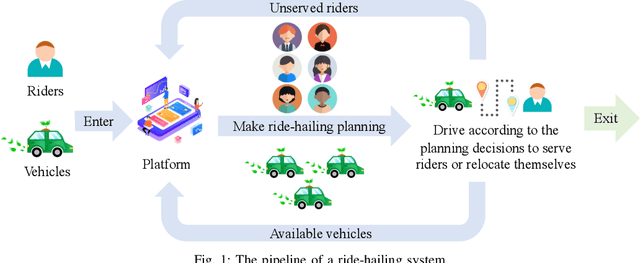
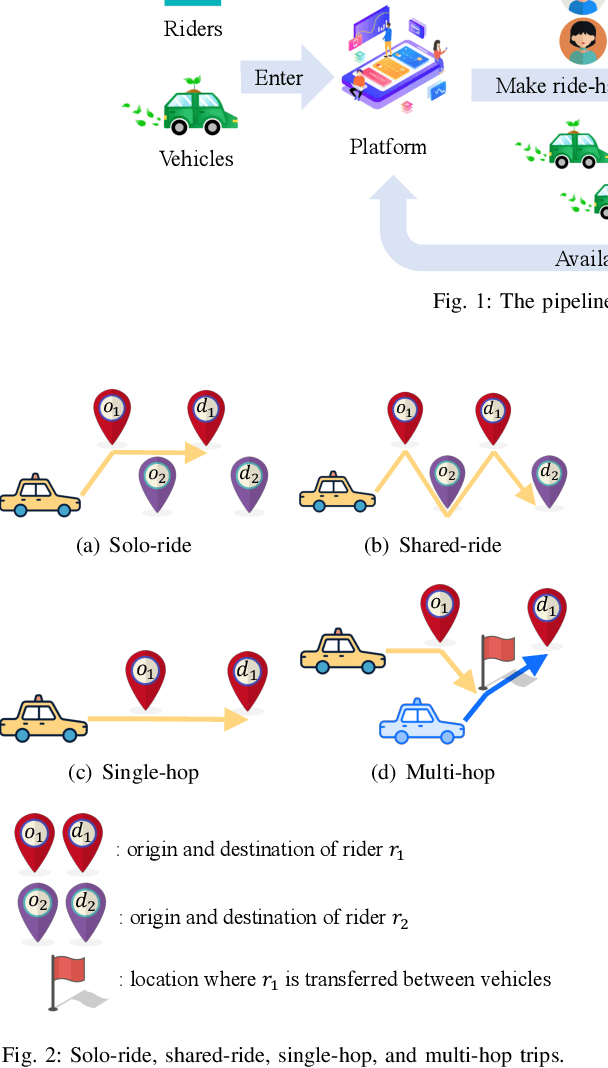
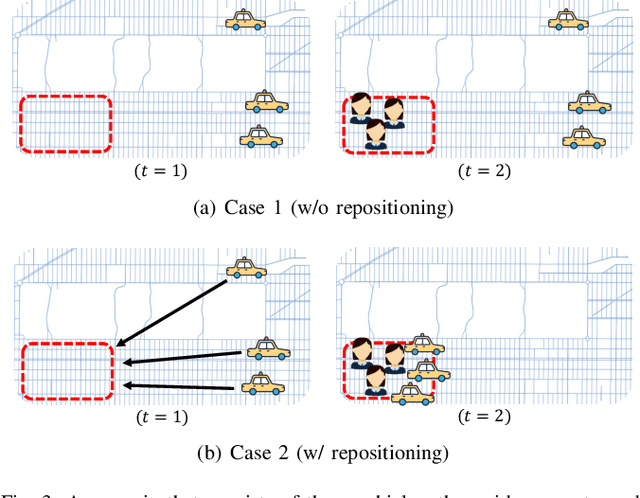
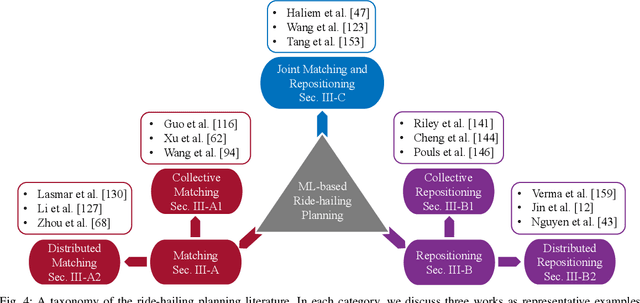
Ride-hailing is a sustainable transportation paradigm where riders access door-to-door traveling services through a mobile phone application, which has attracted a colossal amount of usage. There are two major planning tasks in a ride-hailing system: (1) matching, i.e., assigning available vehicles to pick up the riders, and (2) repositioning, i.e., proactively relocating vehicles to certain locations to balance the supply and demand of ride-hailing services. Recently, many studies of ride-hailing planning that leverage machine learning techniques have emerged. In this article, we present a comprehensive overview on latest developments of machine learning-based ride-hailing planning. To offer a clear and structured review, we introduce a taxonomy into which we carefully fit the different categories of related works according to the types of their planning tasks and solution schemes, which include collective matching, distributed matching, collective repositioning, distributed repositioning, and joint matching and repositioning. We further shed light on many real-world datasets and simulators that are indispensable for empirical studies on machine learning-based ride-hailing planning strategies. At last, we propose several promising research directions for this rapidly growing research and practical field.