 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabClaw: An Interactive and Self-Evolving Agent for Spreadsheet Manipulation and Table Reasoning
Jun 09, 2026Spreadsheets and tables are widely used representations for structured data analysis, but effective analysis still requires substantial manual effort and domain expertise. Recent large language model (LLM) agents can automate parts of this process, but they often provide limited transparency into intermediate decisions, rely on implicit assumptions, struggle with multi-table comparison, and repeat similar workflows without adapting to a user's preferences. This paper presents TabClaw, an open-source interactive AI agent for spreadsheet manipulation and table reasoning. Users upload CSV or Excel files and issue natural-language requests; TabClaw clarifies ambiguous intent, exposes an editable execution plan, streams a ReAct-style tool-using analysis loop, dispatches specialist agents for parallel multi-table reasoning, and synthesizes findings with explicit consensus and uncertainty markers. Beyond one-off analysis, TabClaw records completed workflows, extracts persistent user memory, distills reusable skills from repeated tool-use patterns, supports package-style skill import, and upgrades skills from negative feedback. Experiments on spreadsheet manipulation and table reasoning benchmarks show that TabClaw improves executable task completion and reasoning performance while preserving an inspectable user workflow. This paper shows how TabClaw turns spreadsheets and tables into inspectable analytical workflows while gradually personalizing itself to recurring data-analysis tasks. Our code is available.
GeoDecider: A Coarse-to-Fine Agentic Workflow for Explainable Lithology Classification
May 05, 2026Lithology classification aims to infer subsurface rock types from well-logging signals, supporting downstream applications like reservoir characterization. Despite substantial progress, most existing methods still treat lithology classification as a single-pass classification task. In contrast, practical experts incorporate geological principles, external knowledge, and tool-use capabilities to perform accurate classification. In this work, we propose GeoDecider, a coarse-to-fine agentic workflow that enables accurate and explainable lithology classification through training-free use of large language models (LLMs). GeoDecider reformulates lithology classification as an expert-like structured process and organizes it into a multi-stage workflow involving coarse-to-fine reasoning. Specifically, GeoDecider includes the following stages: (1) base classifier-guided coarse classification, which uses a pre-trained classifier to provide a rough reference for downstream tasks, thus reducing the overall cost of downstream reasoning, (2) tool-augmented reasoning, which utilizes several tools such as contextual analysis and neighbor retrieval to achieve finer and more precise classifications, (3) geological refinement, which post-processes the final results to enforce geological consistency. Experiments on four benchmarks show that GeoDecider outperforms representative baselines. Further analysis demonstrates that the proposed framework produces geologically interpretable predictions while achieving a better trade-off between classification performance and inference efficiency.
GeoMind: An Agentic Workflow for Lithology Classification with Reasoned Tool Invocation
Apr 23, 2026Lithology classification in well logs is a fundamental geoscience data mining task that aims to infer rock types from multi dimensional geophysical sequences. Despite recent progress, existing approaches typically formulate the problem as a static, single-step discriminative mapping. This static paradigm limits evidence-based diagnostic reasoning against geological standards, often yielding predictions that are detached from geological reality due to a lack of domain priors. In this work, we propose GeoMind, a tool-augmented agentic framework that models lithology classification as a sequential reasoning process. GeoMind organizes its toolkit into perception, reasoning, and analysis modules, which respectively translate raw logs into semantic trends, infer lithology hypotheses from multi-source evidence, and verify predictions against stratigraphic constraints. A global planner adaptively coordinates these modules based on input characteristics, enabling geologically plausible and evidence-grounded decisions. To guarantee the logical consistency of GeoMind, we introduce a fine-grained process supervision strategy. Unlike standard methods that focus solely on final outcomes, our approach optimizes intermediate reasoning steps, ensuring the validity of decision trajectories and alignment to geological constraints. Experiments on four benchmark well-log datasets demonstrate that GeoMind consistently outperforms strong baselines in classification performance while providing transparent and traceable decision-making processes.
BLADE: A Behavior-Level Data Augmentation Framework with Dual Fusion Modeling for Multi-Behavior Sequential Recommendation
Dec 15, 2025Multi-behavior sequential recommendation aims to capture users' dynamic interests by modeling diverse types of user interactions over time. Although several studies have explored this setting, the recommendation performance remains suboptimal, mainly due to two fundamental challenges: the heterogeneity of user behaviors and data sparsity. To address these challenges, we propose BLADE, a framework that enhances multi-behavior modeling while mitigating data sparsity. Specifically, to handle behavior heterogeneity, we introduce a dual item-behavior fusion architecture that incorporates behavior information at both the input and intermediate levels, enabling preference modeling from multiple perspectives. To mitigate data sparsity, we design three behavior-level data augmentation methods that operate directly on behavior sequences rather than core item sequences. These methods generate diverse augmented views while preserving the semantic consistency of item sequences. These augmented views further enhance representation learning and generalization via contrastive learning. Experiments on three real-world datasets demonstrate the effectiveness of our approach.
Benchmarking Multimodal LLMs on Recognition and Understanding over Chemical Tables
Jun 13, 2025Chemical tables encode complex experimental knowledge through symbolic expressions, structured variables, and embedded molecular graphics. Existing benchmarks largely overlook this multimodal and domain-specific complexity, limiting the ability of multimodal large language models to support scientific understanding in chemistry. In this work, we introduce ChemTable, a large-scale benchmark of real-world chemical tables curated from the experimental sections of literature. ChemTable includes expert-annotated cell polygons, logical layouts, and domain-specific labels, including reagents, catalysts, yields, and graphical components and supports two core tasks: (1) Table Recognition, covering structure parsing and content extraction; and (2) Table Understanding, encompassing both descriptive and reasoning-oriented question answering grounded in table structure and domain semantics. We evaluated a range of representative multimodal models, including both open-source and closed-source models, on ChemTable and reported a series of findings with practical and conceptual insights. Although models show reasonable performance on basic layout parsing, they exhibit substantial limitations on both descriptive and inferential QA tasks compared to human performance, and we observe significant performance gaps between open-source and closed-source models across multiple dimensions. These results underscore the challenges of chemistry-aware table understanding and position ChemTable as a rigorous and realistic benchmark for advancing scientific reasoning.
The Other Side of the Coin: Exploring Fairness in Retrieval-Augmented Generation
Apr 19, 2025Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by retrieving relevant document from external knowledge sources. By referencing this external knowledge, RAG effectively reduces the generation of factually incorrect content and addresses hallucination issues within LLMs. Recently, there has been growing attention to improving the performance and efficiency of RAG systems from various perspectives. While these advancements have yielded significant results, the application of RAG in domains with considerable societal implications raises a critical question about fairness: What impact does the introduction of the RAG paradigm have on the fairness of LLMs? To address this question, we conduct extensive experiments by varying the LLMs, retrievers, and retrieval sources. Our experimental analysis reveals that the scale of the LLMs plays a significant role in influencing fairness outcomes within the RAG framework. When the model scale is smaller than 8B, the integration of retrieval mechanisms often exacerbates unfairness in small-scale LLMs (e.g., LLaMA3.2-1B, Mistral-7B, and LLaMA3-8B). To mitigate the fairness issues introduced by RAG for small-scale LLMs, we propose two approaches, FairFT and FairFilter. Specifically, in FairFT, we align the retriever with the LLM in terms of fairness, enabling it to retrieve documents that facilitate fairer model outputs. In FairFilter, we propose a fairness filtering mechanism to filter out biased content after retrieval. Finally, we validate our proposed approaches on real-world datasets, demonstrating their effectiveness in improving fairness while maintaining performance.
Enhancing Table Recognition with Vision LLMs: A Benchmark and Neighbor-Guided Toolchain Reasoner
Dec 30, 2024



Pre-trained foundation models have recently significantly progressed in structured table understanding and reasoning. However, despite advancements in areas such as table semantic understanding and table question answering, recognizing the structure and content of unstructured tables using Vision Large Language Models (VLLMs) remains under-explored. In this work, we address this research gap by employing VLLMs in a training-free reasoning paradigm. First, we design a benchmark with various hierarchical dimensions relevant to table recognition. Subsequently, we conduct in-depth evaluations using pre-trained VLLMs, finding that low-quality image input is a significant bottleneck in the recognition process. Drawing inspiration from these findings, we propose the Neighbor-Guided Toolchain Reasoner (NGTR) framework, which is characterized by integrating multiple lightweight models for low-level visual processing operations aimed at mitigating issues with low-quality input images. Specifically, we utilize a neighbor retrieval mechanism to guide the generation of multiple tool invocation plans, transferring tool selection experiences from similar neighbors to the given input, thereby facilitating suitable tool selection. Additionally, we introduce a reflection module to supervise the tool invocation process. Extensive experiments on public table recognition datasets demonstrate that our approach significantly enhances the recognition capabilities of the vanilla VLLMs. We believe that the designed benchmark and the proposed NGTR framework could provide an alternative solution in table recognition.
PoTable: Programming Standardly on Table-based Reasoning Like a Human Analyst
Dec 05, 2024



Table-based reasoning has garnered substantial research interest, particularly in its integration with Large Language Model (LLM) which has revolutionized the general reasoning paradigm. Numerous LLM-based studies introduce symbolic tools (e.g., databases, Python) as assistants to extend human-like abilities in structured table understanding and complex arithmetic computations. However, these studies can be improved better in simulating human cognitive behavior when using symbolic tools, as they still suffer from limitations of non-standard logical splits and constrained operation pools. In this study, we propose PoTable as a novel table-based reasoning method that simulates a human tabular analyst, which integrates a Python interpreter as the real-time executor accompanied by an LLM-based operation planner and code generator. Specifically, PoTable follows a human-like logical stage split and extends the operation pool into an open-world space without any constraints. Through planning and executing in each distinct stage, PoTable standardly completes the entire reasoning process and produces superior reasoning results along with highly accurate, steply commented and completely executable programs. Accordingly, the effectiveness and explainability of PoTable are fully demonstrated. Extensive experiments over three evaluation datasets from two public benchmarks on two backbones show the outstanding performance of our approach. In particular, GPT-based PoTable achieves over 4% higher absolute accuracy than runner-ups on all evaluation datasets.
TableTime: Reformulating Time Series Classification as Zero-Shot Table Understanding via Large Language Models
Nov 24, 2024



Large language models (LLMs) have demonstrated their effectiveness in multivariate time series classification (MTSC). Effective adaptation of LLMs for MTSC necessitates informative data representations. Existing LLM-based methods directly encode embeddings for time series within the latent space of LLMs from scratch to align with semantic space of LLMs. Despite their effectiveness, we reveal that these methods conceal three inherent bottlenecks: (1) they struggle to encode temporal and channel-specific information in a lossless manner, both of which are critical components of multivariate time series; (2) it is much difficult to align the learned representation space with the semantic space of the LLMs; (3) they require task-specific retraining, which is both computationally expensive and labor-intensive. To bridge these gaps, we propose TableTime, which reformulates MTSC as a table understanding task. Specifically, TableTime introduces the following strategies: (1) convert multivariate time series into a tabular form, thus minimizing information loss to the greatest extent; (2) represent tabular time series in text format to achieve natural alignment with the semantic space of LLMs; (3) design a reasoning framework that integrates contextual text information, neighborhood assistance, multi-path inference and problem decomposition to enhance the reasoning ability of LLMs and realize zero-shot classification. Extensive experiments performed on 10 publicly representative datasets from UEA archive verify the superiorities of the TableTime.
DisenTS: Disentangled Channel Evolving Pattern Modeling for Multivariate Time Series Forecasting
Oct 30, 2024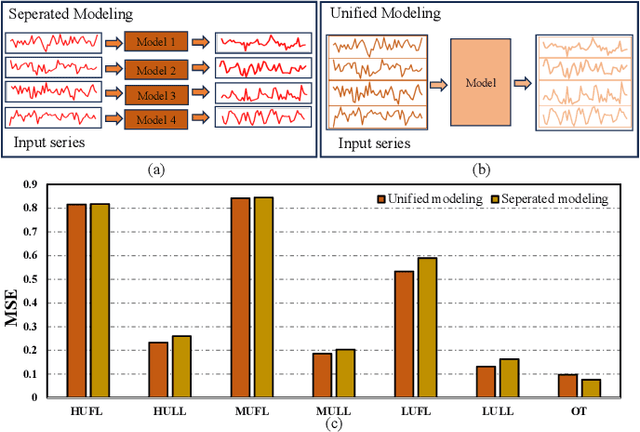
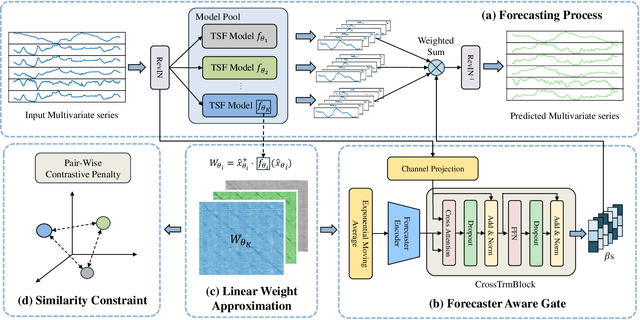

Multivariate time series forecasting plays a crucial role in various real-world applications. Significant efforts have been made to integrate advanced network architectures and training strategies that enhance the capture of temporal dependencies, thereby improving forecasting accuracy. On the other hand, mainstream approaches typically utilize a single unified model with simplistic channel-mixing embedding or cross-channel attention operations to account for the critical intricate inter-channel dependencies. Moreover, some methods even trade capacity for robust prediction based on the channel-independent assumption. Nonetheless, as time series data may display distinct evolving patterns due to the unique characteristics of each channel (including multiple strong seasonalities and trend changes), the unified modeling methods could yield suboptimal results. To this end, we propose DisenTS, a tailored framework for modeling disentangled channel evolving patterns in general multivariate time series forecasting. The central idea of DisenTS is to model the potential diverse patterns within the multivariate time series data in a decoupled manner. Technically, the framework employs multiple distinct forecasting models, each tasked with uncovering a unique evolving pattern. To guide the learning process without supervision of pattern partition, we introduce a novel Forecaster Aware Gate (FAG) module that generates the routing signals adaptively according to both the forecasters' states and input series' characteristics. The forecasters' states are derived from the Linear Weight Approximation (LWA) strategy, which quantizes the complex deep neural networks into compact matrices. Additionally, the Similarity Constraint (SC) is further proposed to guide each model to specialize in an underlying pattern by minimizing the mutual information between the representations.