 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided by Trajectories: Repairing and Rewarding Tool-Use Trajectories for Tool-Integrated Reasoning
Jan 30, 2026Tool-Integrated Reasoning (TIR) enables large language models (LLMs) to solve complex tasks by interacting with external tools, yet existing approaches depend on high-quality synthesized trajectories selected by scoring functions and sparse outcome-based rewards, providing limited and biased supervision for learning TIR. To address these challenges, in this paper, we propose AutoTraj, a two-stage framework that automatically learns TIR by repairing and rewarding tool-use trajectories. Specifically, in the supervised fine-tuning (SFT) stage, AutoTraj generates multiple candidate tool-use trajectories for each query and evaluates them along multiple dimensions. High-quality trajectories are directly retained, while low-quality ones are repaired using a LLM (i.e., LLM-as-Repairer). The resulting repaired and high-quality trajectories form a synthetic SFT dataset, while each repaired trajectory paired with its original low-quality counterpart constitutes a dataset for trajectory preference modeling. In the reinforcement learning (RL) stage, based on the preference dataset, we train a trajectory-level reward model to assess the quality of reasoning paths and combine it with outcome and format rewards, thereby explicitly guiding the optimization toward reliable TIR behaviors. Experiments on real-world benchmarks demonstrate the effectiveness of AutoTraj in TIR.
Language Hierarchization Provides the Optimal Solution to Human Working Memory Limits
Jan 06, 2026Language is a uniquely human trait, conveying information efficiently by organizing word sequences in sentences into hierarchical structures. A central question persists: Why is human language hierarchical? In this study, we show that hierarchization optimally solves the challenge of our limited working memory capacity. We established a likelihood function that quantifies how well the average number of units according to the language processing mechanisms aligns with human working memory capacity (WMC) in a direct fashion. The maximum likelihood estimate (MLE) of this function, tehta_MLE, turns out to be the mean of units. Through computational simulations of symbol sequences and validation analyses of natural language sentences, we uncover that compared to linear processing, hierarchical processing far surpasses it in constraining the tehta_MLE values under the human WMC limit, along with the increase of sequence/sentence length successfully. It also shows a converging pattern related to children's WMC development. These results suggest that constructing hierarchical structures optimizes the processing efficiency of sequential language input while staying within memory constraints, genuinely explaining the universal hierarchical nature of human language.
Artificial intelligence for representing and characterizing quantum systems
Sep 05, 2025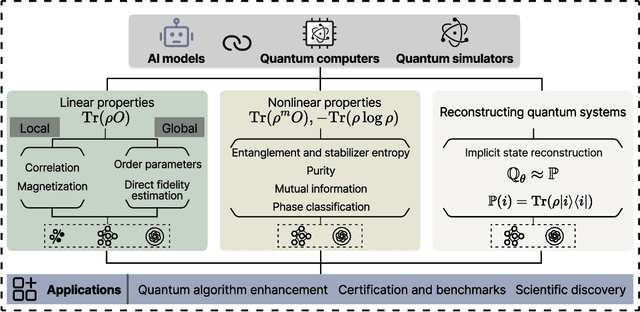
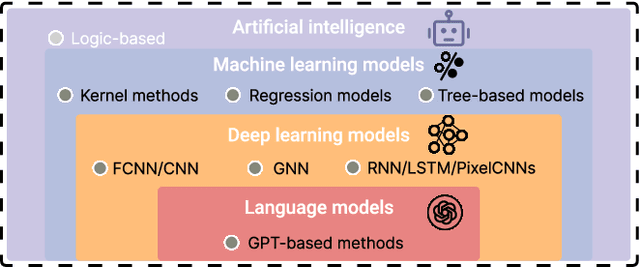
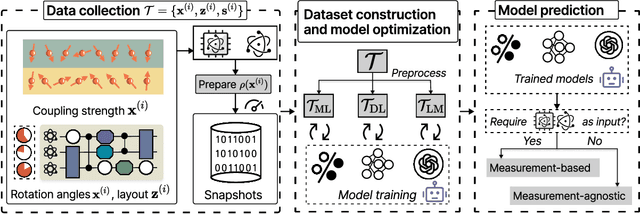
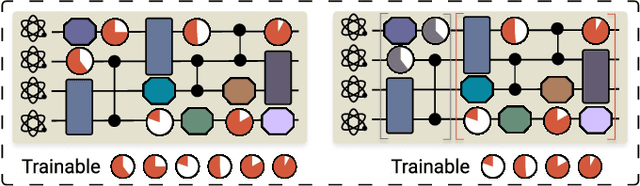
Efficient characterization of large-scale quantum systems, especially those produced by quantum analog simulators and megaquop quantum computers, poses a central challenge in quantum science due to the exponential scaling of the Hilbert space with respect to system size. Recent advances in artificial intelligence (AI), with its aptitude for high-dimensional pattern recognition and function approximation, have emerged as a powerful tool to address this challenge. A growing body of research has leveraged AI to represent and characterize scalable quantum systems, spanning from theoretical foundations to experimental realizations. Depending on how prior knowledge and learning architectures are incorporated, the integration of AI into quantum system characterization can be categorized into three synergistic paradigms: machine learning, and, in particular, deep learning and language models. This review discusses how each of these AI paradigms contributes to two core tasks in quantum systems characterization: quantum property prediction and the construction of surrogates for quantum states. These tasks underlie diverse applications, from quantum certification and benchmarking to the enhancement of quantum algorithms and the understanding of strongly correlated phases of matter. Key challenges and open questions are also discussed, together with future prospects at the interface of AI and quantum science.
CoderAgent: Simulating Student Behavior for Personalized Programming Learning with Large Language Models
May 27, 2025Personalized programming tutoring, such as exercise recommendation, can enhance learners' efficiency, motivation, and outcomes, which is increasingly important in modern digital education. However, the lack of sufficient and high-quality programming data, combined with the mismatch between offline evaluation and real-world learning, hinders the practical deployment of such systems. To address this challenge, many approaches attempt to simulate learner practice data, yet they often overlook the fine-grained, iterative nature of programming learning, resulting in a lack of interpretability and granularity. To fill this gap, we propose a LLM-based agent, CoderAgent, to simulate students' programming processes in a fine-grained manner without relying on real data. Specifically, we equip each human learner with an intelligent agent, the core of which lies in capturing the cognitive states of the human programming practice process. Inspired by ACT-R, a cognitive architecture framework, we design the structure of CoderAgent to align with human cognitive architecture by focusing on the mastery of programming knowledge and the application of coding ability. Recognizing the inherent patterns in multi-layered cognitive reasoning, we introduce the Programming Tree of Thought (PTOT), which breaks down the process into four steps: why, how, where, and what. This approach enables a detailed analysis of iterative problem-solving strategies. Finally, experimental evaluations on real-world datasets demonstrate that CoderAgent provides interpretable insights into learning trajectories and achieves accurate simulations, paving the way for personalized programming education.
GraphPrompter: Multi-stage Adaptive Prompt Optimization for Graph In-Context Learning
May 04, 2025Graph In-Context Learning, with the ability to adapt pre-trained graph models to novel and diverse downstream graphs without updating any parameters, has gained much attention in the community. The key to graph in-context learning is to perform downstream graphs conditioned on chosen prompt examples. Existing methods randomly select subgraphs or edges as prompts, leading to noisy graph prompts and inferior model performance. Additionally, due to the gap between pre-training and testing graphs, when the number of classes in the testing graphs is much greater than that in the training, the in-context learning ability will also significantly deteriorate. To tackle the aforementioned challenges, we develop a multi-stage adaptive prompt optimization method GraphPrompter, which optimizes the entire process of generating, selecting, and using graph prompts for better in-context learning capabilities. Firstly, Prompt Generator introduces a reconstruction layer to highlight the most informative edges and reduce irrelevant noise for graph prompt construction. Furthermore, in the selection stage, Prompt Selector employs the $k$-nearest neighbors algorithm and pre-trained selection layers to dynamically choose appropriate samples and minimize the influence of irrelevant prompts. Finally, we leverage a Prompt Augmenter with a cache replacement strategy to enhance the generalization capability of the pre-trained model on new datasets. Extensive experiments show that GraphPrompter effectively enhances the in-context learning ability of graph models. On average across all the settings, our approach surpasses the state-of-the-art baselines by over 8%. Our code is released at https://github.com/karin0018/GraphPrompter.
The Other Side of the Coin: Exploring Fairness in Retrieval-Augmented Generation
Apr 19, 2025Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by retrieving relevant document from external knowledge sources. By referencing this external knowledge, RAG effectively reduces the generation of factually incorrect content and addresses hallucination issues within LLMs. Recently, there has been growing attention to improving the performance and efficiency of RAG systems from various perspectives. While these advancements have yielded significant results, the application of RAG in domains with considerable societal implications raises a critical question about fairness: What impact does the introduction of the RAG paradigm have on the fairness of LLMs? To address this question, we conduct extensive experiments by varying the LLMs, retrievers, and retrieval sources. Our experimental analysis reveals that the scale of the LLMs plays a significant role in influencing fairness outcomes within the RAG framework. When the model scale is smaller than 8B, the integration of retrieval mechanisms often exacerbates unfairness in small-scale LLMs (e.g., LLaMA3.2-1B, Mistral-7B, and LLaMA3-8B). To mitigate the fairness issues introduced by RAG for small-scale LLMs, we propose two approaches, FairFT and FairFilter. Specifically, in FairFT, we align the retriever with the LLM in terms of fairness, enabling it to retrieve documents that facilitate fairer model outputs. In FairFilter, we propose a fairness filtering mechanism to filter out biased content after retrieval. Finally, we validate our proposed approaches on real-world datasets, demonstrating their effectiveness in improving fairness while maintaining performance.
Agent4Edu: Generating Learner Response Data by Generative Agents for Intelligent Education Systems
Jan 17, 2025



Personalized learning represents a promising educational strategy within intelligent educational systems, aiming to enhance learners' practice efficiency. However, the discrepancy between offline metrics and online performance significantly impedes their progress. To address this challenge, we introduce Agent4Edu, a novel personalized learning simulator leveraging recent advancements in human intelligence through large language models (LLMs). Agent4Edu features LLM-powered generative agents equipped with learner profile, memory, and action modules tailored to personalized learning algorithms. The learner profiles are initialized using real-world response data, capturing practice styles and cognitive factors. Inspired by human psychology theory, the memory module records practice facts and high-level summaries, integrating reflection mechanisms. The action module supports various behaviors, including exercise understanding, analysis, and response generation. Each agent can interact with personalized learning algorithms, such as computerized adaptive testing, enabling a multifaceted evaluation and enhancement of customized services. Through a comprehensive assessment, we explore the strengths and weaknesses of Agent4Edu, emphasizing the consistency and discrepancies in responses between agents and human learners. The code, data, and appendix are publicly available at https://github.com/bigdata-ustc/Agent4Edu.
Collaborative Cognitive Diagnosis with Disentangled Representation Learning for Learner Modeling
Nov 04, 2024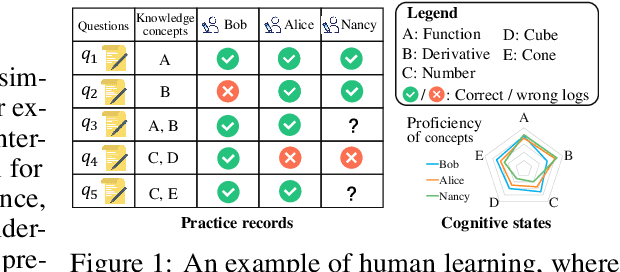
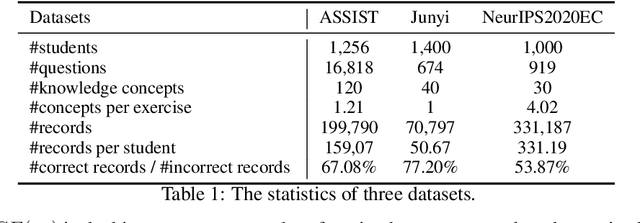
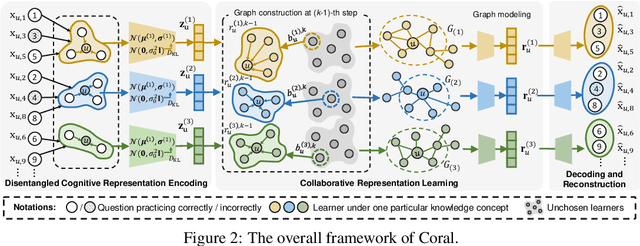
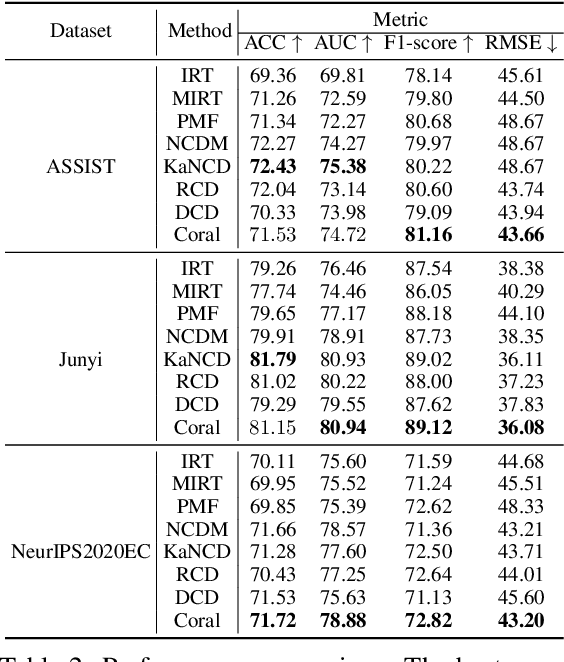
Learners sharing similar implicit cognitive states often display comparable observable problem-solving performances. Leveraging collaborative connections among such similar learners proves valuable in comprehending human learning. Motivated by the success of collaborative modeling in various domains, such as recommender systems, we aim to investigate how collaborative signals among learners contribute to the diagnosis of human cognitive states (i.e., knowledge proficiency) in the context of intelligent education. The primary challenges lie in identifying implicit collaborative connections and disentangling the entangled cognitive factors of learners for improved explainability and controllability in learner Cognitive Diagnosis (CD). However, there has been no work on CD capable of simultaneously modeling collaborative and disentangled cognitive states. To address this gap, we present Coral, a Collaborative cognitive diagnosis model with disentangled representation learning. Specifically, Coral first introduces a disentangled state encoder to achieve the initial disentanglement of learners' states. Subsequently, a meticulously designed collaborative representation learning procedure captures collaborative signals. It dynamically constructs a collaborative graph of learners by iteratively searching for optimal neighbors in a context-aware manner. Using the constructed graph, collaborative information is extracted through node representation learning. Finally, a decoding process aligns the initial cognitive states and collaborative states, achieving co-disentanglement with practice performance reconstructions. Extensive experiments demonstrate the superior performance of Coral, showcasing significant improvements over state-of-the-art methods across several real-world datasets. Our code is available at https://github.com/bigdata-ustc/Coral.
A Survey of Models for Cognitive Diagnosis: New Developments and Future Directions
Jul 07, 2024



Cognitive diagnosis has been developed for decades as an effective measurement tool to evaluate human cognitive status such as ability level and knowledge mastery. It has been applied to a wide range of fields including education, sport, psychological diagnosis, etc. By providing better awareness of cognitive status, it can serve as the basis for personalized services such as well-designed medical treatment, teaching strategy and vocational training. This paper aims to provide a survey of current models for cognitive diagnosis, with more attention on new developments using machine learning-based methods. By comparing the model structures, parameter estimation algorithms, model evaluation methods and applications, we provide a relatively comprehensive review of the recent trends in cognitive diagnosis models. Further, we discuss future directions that are worthy of exploration. In addition, we release two Python libraries: EduData for easy access to some relevant public datasets we have collected, and EduCDM that implements popular CDMs to facilitate both applications and research purposes.
Event Grounded Criminal Court View Generation with Cooperative (Large) Language Models
Apr 13, 2024



With the development of legal intelligence, Criminal Court View Generation has attracted much attention as a crucial task of legal intelligence, which aims to generate concise and coherent texts that summarize case facts and provide explanations for verdicts. Existing researches explore the key information in case facts to yield the court views. Most of them employ a coarse-grained approach that partitions the facts into broad segments (e.g., verdict-related sentences) to make predictions. However, this approach fails to capture the complex details present in the case facts, such as various criminal elements and legal events. To this end, in this paper, we propose an Event Grounded Generation (EGG) method for criminal court view generation with cooperative (Large) Language Models, which introduces the fine-grained event information into the generation. Specifically, we first design a LLMs-based extraction method that can extract events in case facts without massive annotated events. Then, we incorporate the extracted events into court view generation by merging case facts and events. Besides, considering the computational burden posed by the use of LLMs in the extraction phase of EGG, we propose a LLMs-free EGG method that can eliminate the requirement for event extraction using LLMs in the inference phase. Extensive experimental results on a real-world dataset clearly validate the effectiveness of our proposed method.