 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoderAgent: Simulating Student Behavior for Personalized Programming Learning with Large Language Models
May 27, 2025Personalized programming tutoring, such as exercise recommendation, can enhance learners' efficiency, motivation, and outcomes, which is increasingly important in modern digital education. However, the lack of sufficient and high-quality programming data, combined with the mismatch between offline evaluation and real-world learning, hinders the practical deployment of such systems. To address this challenge, many approaches attempt to simulate learner practice data, yet they often overlook the fine-grained, iterative nature of programming learning, resulting in a lack of interpretability and granularity. To fill this gap, we propose a LLM-based agent, CoderAgent, to simulate students' programming processes in a fine-grained manner without relying on real data. Specifically, we equip each human learner with an intelligent agent, the core of which lies in capturing the cognitive states of the human programming practice process. Inspired by ACT-R, a cognitive architecture framework, we design the structure of CoderAgent to align with human cognitive architecture by focusing on the mastery of programming knowledge and the application of coding ability. Recognizing the inherent patterns in multi-layered cognitive reasoning, we introduce the Programming Tree of Thought (PTOT), which breaks down the process into four steps: why, how, where, and what. This approach enables a detailed analysis of iterative problem-solving strategies. Finally, experimental evaluations on real-world datasets demonstrate that CoderAgent provides interpretable insights into learning trajectories and achieves accurate simulations, paving the way for personalized programming education.
am-ELO: A Stable Framework for Arena-based LLM Evaluation
May 06, 2025Arena-based evaluation is a fundamental yet significant evaluation paradigm for modern AI models, especially large language models (LLMs). Existing framework based on ELO rating system suffers from the inevitable instability problem due to ranking inconsistency and the lack of attention to the varying abilities of annotators. In this paper, we introduce a novel stable arena framework to address these issues by enhancing the ELO Rating System. Specifically, we replace the iterative update method with a Maximum Likelihood Estimation (MLE) approach, m-ELO, and provide theoretical proof of the consistency and stability of the MLE approach for model ranking. Additionally, we proposed the am-ELO, which modify the Elo Rating's probability function to incorporate annotator abilities, enabling the simultaneous estimation of model scores and annotator reliability. Experiments demonstrate that this method ensures stability, proving that this framework offers a more robust, accurate, and stable evaluation method for LLMs.
Enhancing Knowledge Graph Completion with Entity Neighborhood and Relation Context
Mar 29, 2025Knowledge Graph Completion (KGC) aims to infer missing information in Knowledge Graphs (KGs) to address their inherent incompleteness. Traditional structure-based KGC methods, while effective, face significant computational demands and scalability challenges due to the need for dense embedding learning and scoring all entities in the KG for each prediction. Recent text-based approaches using language models like T5 and BERT have mitigated these issues by converting KG triples into text for reasoning. However, they often fail to fully utilize contextual information, focusing mainly on the neighborhood of the entity and neglecting the context of the relation. To address this issue, we propose KGC-ERC, a framework that integrates both types of context to enrich the input of generative language models and enhance their reasoning capabilities. Additionally, we introduce a sampling strategy to effectively select relevant context within input token constraints, which optimizes the utilization of contextual information and potentially improves model performance. Experiments on the Wikidata5M, Wiki27K, and FB15K-237-N datasets show that KGC-ERC outperforms or matches state-of-the-art baselines in predictive performance and scalability.
Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering
May 27, 2024
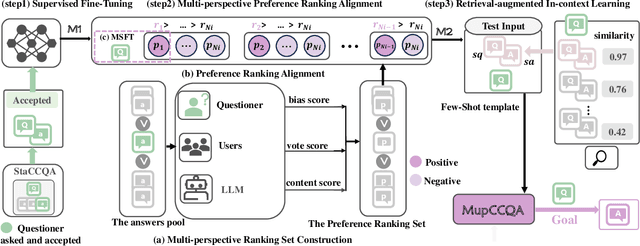
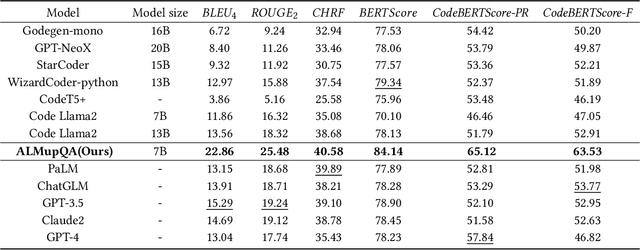
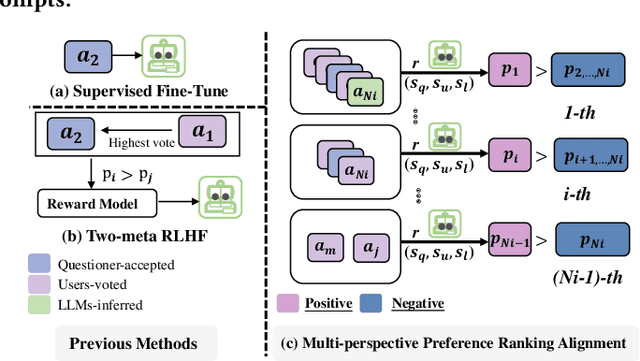
Code Community Question Answering (CCQA) seeks to tackle programming-related issues, thereby boosting productivity in both software engineering and academic research. Recent advancements in Reinforcement Learning from Human Feedback (RLHF) have transformed the fine-tuning process of Large Language Models (LLMs) to produce responses that closely mimic human behavior. Leveraging LLMs with RLHF for practical CCQA applications has thus emerged as a promising area of study. Unlike standard code question-answering tasks, CCQA involves multiple possible answers, with varying user preferences for each response. Additionally, code communities often show a preference for new APIs. These challenges prevent LLMs from generating responses that cater to the diverse preferences of users in CCQA tasks. To address these issues, we propose a novel framework called Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering (ALMupQA) to create user-focused responses. Our approach starts with Multi-perspective Preference Ranking Alignment (MPRA), which synthesizes varied user preferences based on the characteristics of answers from code communities. We then introduce a Retrieval-augmented In-context Learning (RIL) module to mitigate the problem of outdated answers by retrieving responses to similar questions from a question bank. Due to the limited availability of high-quality, multi-answer CCQA datasets, we also developed a dataset named StaCCQA from real code communities. Extensive experiments demonstrated the effectiveness of the ALMupQA framework in terms of accuracy and user preference. Compared to the base model, ALMupQA showed nearly an 11% improvement in BLEU, with increases of 20% and 17.5% in BERTScore and CodeBERTScore, respectively.
Quiz-based Knowledge Tracing
Apr 06, 2023Knowledge tracing (KT) aims to assess individuals' evolving knowledge states according to their learning interactions with different exercises in online learning systems (OIS), which is critical in supporting decision-making for subsequent intelligent services, such as personalized learning source recommendation. Existing researchers have broadly studied KT and developed many effective methods. However, most of them assume that students' historical interactions are uniformly distributed in a continuous sequence, ignoring the fact that actual interaction sequences are organized based on a series of quizzes with clear boundaries, where interactions within a quiz are consecutively completed, but interactions across different quizzes are discrete and may be spaced over days. In this paper, we present the Quiz-based Knowledge Tracing (QKT) model to monitor students' knowledge states according to their quiz-based learning interactions. Specifically, as students' interactions within a quiz are continuous and have the same or similar knowledge concepts, we design the adjacent gate followed by a global average pooling layer to capture the intra-quiz short-term knowledge influence. Then, as various quizzes tend to focus on different knowledge concepts, we respectively measure the inter-quiz knowledge substitution by the gated recurrent unit and the inter-quiz knowledge complementarity by the self-attentive encoder with a novel recency-aware attention mechanism. Finally, we integrate the inter-quiz long-term knowledge substitution and complementarity across different quizzes to output students' evolving knowledge states. Extensive experimental results on three public real-world datasets demonstrate that QKT achieves state-of-the-art performance compared to existing methods. Further analyses confirm that QKT is promising in designing more effective quizzes.
A Survey of Knowledge Tracing
Jun 01, 2021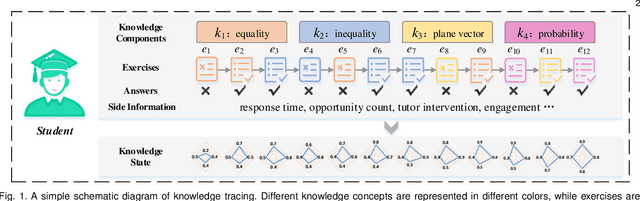

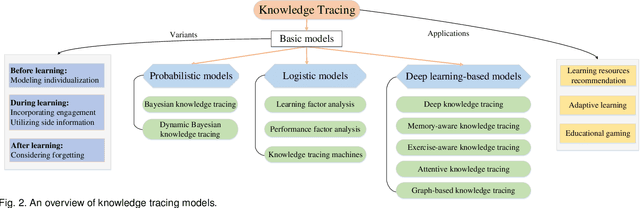

High-quality education is one of the keys to achieving a more sustainable world. The recent COVID-19 epidemic has triggered the outbreak of online education, which has enabled both students and teachers to learn and teach at home. Meanwhile, it is now possible to record and research a large amount of learning data using online learning platforms in order to offer better intelligent educational services. Knowledge Tracing (KT), which aims to monitor students' evolving knowledge state, is a fundamental and crucial task to support these intelligent services. Therefore, an increasing amount of research attention has been paid to this emerging area and considerable progress has been made. In this survey, we propose a new taxonomy of existing basic KT models from a technical perspective and provide a comprehensive overview of these models in a systematic manner. In addition, many variants of KT models have been proposed to capture more complete learning process. We then review these variants involved in three phases of the learning process: before, during, and after the student learning, respectively. Moreover, we present several typical applications of KT in different educational scenarios. Finally, we provide some potential directions for future research in this fast-growing field.