 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViCoStream: Streaming VideoLLMs Can Run Beyond 100 FPS with Stage-Wise Coordinated Inference
Jun 18, 2026Streaming VideoLLMs must continuously process incoming video while maintaining low query latency, making both video-ingestion throughput and query-time responsiveness critical for real-time deployment. Existing methods largely focus on accelerating individual modules, such as visual encoding, token pruning, or KV-cache compression, but provide limited insight into whether the resulting system can sustain real-time streaming performance. We formulate streaming VideoLLM inference as a coordinated pipeline spanning visual preprocessing, visual encoding, token dropping, and LLM prefilling/decoding. Building on this formulation, we propose ViCoStream (Video Coordinated Streaming), a stage-wise coordinated streaming framework that combines chunk-wise execution, CUDA-stream overlap, visual token control, bounded visual attention, and query-side retrieval to bound per-chunk computation and memory costs. We further provide a systematic study of bottleneck migration, revealing how chunk size, token retention, attention locality, and retrieval scope shape the throughput-accuracy trade-off. Experiments with Qwen2.5-VL-3B/7B-Instruct across multiple streaming benchmarks show that ViCoStream achieves 134 FPS video throughput and less than 50 ms TTFT on a single A100 GPU while maintaining accuracy close to full-history baselines.
Edu-Theater: A Data-Efficient Agent Framework for Scalable Learner Behavior Simulation through Staging Roll-Call
Jun 13, 2026Large-scale learner-task interaction data are crucial for intelligent educational systems but are costly to collect and constrained by privacy and learner engagement. Learner simulators play a critical role in simulating scalable learner behavior without the need for continuous involvement of real learners. However, existing methods are predominantly \textbf{individual-centric}, pairing a simulator with each learner to iteratively infer latent knowledge states from dense interaction histories, which is both data- and computation-intensive, and fragile in cold-start scenarios. We propose a \textbf{cohort-aware roll-call simulation paradigm} that first constructs cohort-level proficiency priors and refines individual learner states through a small number of targeted diagnostic queries. Based on this paradigm, we introduce \textbf{Edu-Theater}, an LLM-powered agent system that performs cohort-aware learner simulation via a teacher agent and retrospective roll-call probing over learner logs. Edu-Theater enables scalable future behavior simulation without the need for dense per-learner histories. Experiments on two real-world datasets demonstrate that Edu-Theater achieves higher simulation accuracy with significantly fewer LLM calls, producing synthetic data that enhances downstream applications such as adaptive testing.
When AI reviews science: Can we trust the referee?
Apr 26, 2026The volume of scientific submissions continues to climb, outpacing the capacity of qualified human referees and stretching editorial timelines. At the same time, modern large language models (LLMs) offer impressive capabilities in summarization, fact checking, and literature triage, making the integration of AI into peer review increasingly attractive -- and, in practice, unavoidable. Yet early deployments and informal adoption have exposed acute failure modes. Recent incidents have revealed that hidden prompt injections embedded in manuscripts can steer LLM-generated reviews toward unjustifiably positive judgments. Complementary studies have also demonstrated brittleness to adversarial phrasing, authority and length biases, and hallucinated claims. These episodes raise a central question for scholarly communication: when AI reviews science, can we trust the AI referee? This paper provides a security- and reliability-centered analysis of AI peer review. We map attacks across the review lifecycle -- training and data retrieval, desk review, deep review, rebuttal, and system-level. We instantiate this taxonomy with four treatment-control probes on a stratified set of ICLR 2025 submissions, using two advanced LLM-based referees to isolate the causal effects of prestige framing, assertion strength, rebuttal sycophancy, and contextual poisoning on review scores. Together, this taxonomy and experimental audit provide an evidence-based baseline for assessing and tracking the reliability of AI peer review and highlight concrete failure points to guide targeted, testable mitigations.
Towards Safer Large Reasoning Models by Promoting Safety Decision-Making before Chain-of-Thought Generation
Mar 18, 2026Large reasoning models (LRMs) achieved remarkable performance via chain-of-thought (CoT), but recent studies showed that such enhanced reasoning capabilities are at the expense of significantly degraded safety capabilities. In this paper, we reveal that LRMs' safety degradation occurs only after CoT is enabled, and this degradation is not observed when CoT is disabled. This observation motivates us to consider encouraging LRMs to make safety decisions before CoT generation. To this end, we propose a novel safety alignment method that promotes the safety decision-making of LRMs before starting CoT generation. Specifically, we first utilize a Bert-based classifier to extract safety decision signals from a safe model (e.g., a CoT-disabled LRM) and then integrate these signals into LRMs' safety alignment as auxiliary supervision. In this way, the safety gradients can be backpropagated to the LRMs' latent representations, effectively strengthening the LRMs' safety decision-making abilities against CoT generation. Extensive experiments demonstrate that our method substantially improves the safety capabilities of LRMs while effectively maintaining LRMs' general reasoning performance.
Bridging Efficiency and Transparency: Explainable CoT Compression in Multimodal Large Reasoning Models
Feb 10, 2026Long chains of thought (Long CoTs) are widely employed in multimodal reasoning models to tackle complex tasks by capturing detailed visual information. However, these Long CoTs are often excessively lengthy and contain redundant reasoning steps, which can hinder inference efficiency. Compressing these long CoTs is a natural solution, yet existing approaches face two major challenges: (1) they may compromise the integrity of visual-textual reasoning by removing essential alignment cues, and (2) the compression process lacks explainability, making it difficult to discern which information is critical. To address these problems, we propose XMCC, an eXplainable Multimodal CoT Compressor that formulates compression as a sequential decision-making process optimized via reinforcement learning. XMCC can effectively shorten reasoning trajectories while preserving key reasoning steps and answer correctness, and simultaneously generates natural-language explanations for its compression decisions. Extensive experiments on representative multimodal reasoning benchmarks demonstrate that XMCC not only reduces reasoning length but also provides explainable explanations, validating its effectiveness.
Guided by Trajectories: Repairing and Rewarding Tool-Use Trajectories for Tool-Integrated Reasoning
Jan 30, 2026Tool-Integrated Reasoning (TIR) enables large language models (LLMs) to solve complex tasks by interacting with external tools, yet existing approaches depend on high-quality synthesized trajectories selected by scoring functions and sparse outcome-based rewards, providing limited and biased supervision for learning TIR. To address these challenges, in this paper, we propose AutoTraj, a two-stage framework that automatically learns TIR by repairing and rewarding tool-use trajectories. Specifically, in the supervised fine-tuning (SFT) stage, AutoTraj generates multiple candidate tool-use trajectories for each query and evaluates them along multiple dimensions. High-quality trajectories are directly retained, while low-quality ones are repaired using a LLM (i.e., LLM-as-Repairer). The resulting repaired and high-quality trajectories form a synthetic SFT dataset, while each repaired trajectory paired with its original low-quality counterpart constitutes a dataset for trajectory preference modeling. In the reinforcement learning (RL) stage, based on the preference dataset, we train a trajectory-level reward model to assess the quality of reasoning paths and combine it with outcome and format rewards, thereby explicitly guiding the optimization toward reliable TIR behaviors. Experiments on real-world benchmarks demonstrate the effectiveness of AutoTraj in TIR.
Training Multimodal Large Reasoning Models Needs Better Thoughts: A Three-Stage Framework for Long Chain-of-Thought Synthesis and Selection
Dec 22, 2025Large Reasoning Models (LRMs) have demonstrated remarkable performance on complex reasoning tasks through long Chain-of-Thought (CoT) reasoning. Extending these successes to multimodal reasoning remains challenging due to the increased complexity of integrating diverse input modalities and the scarcity of high-quality long CoT training data. Existing multimodal datasets and CoT synthesis methods still suffer from limited reasoning depth, modality conversion errors, and rigid generation pipelines, hindering model performance and stability. To this end, in this paper, we propose SynSelect, a novel three-stage Synthesis-Selection framework for generating high-quality long CoT data tailored to multimodal reasoning tasks. Specifically, SynSelect first leverages multiple heterogeneous multimodal LRMs to produce diverse candidate CoTs, and then applies both instance and batch level selection to filter high-quality CoTs that can effectively enhance the model's reasoning capabilities. Extensive experiments on multiple multimodal benchmarks demonstrate that models supervised fine-tuned on SynSelect-generated data significantly outperform baselines and achieve further improvements after reinforcement learning post-training. Our results validate SynSelect as an effective approach for advancing multimodal LRMs reasoning capabilities.
Agentic Video Intelligence: A Flexible Framework for Advanced Video Exploration and Understanding
Nov 18, 2025
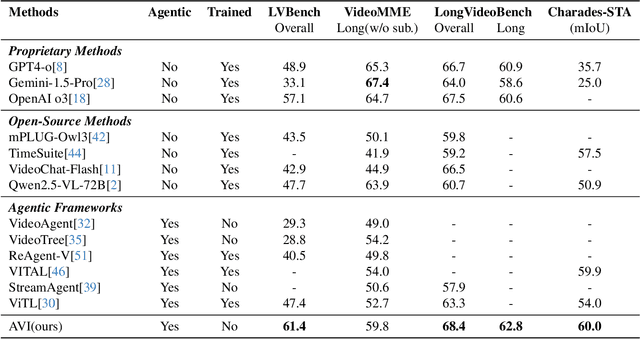
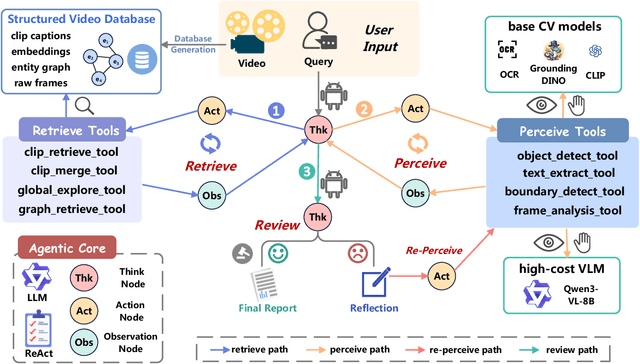
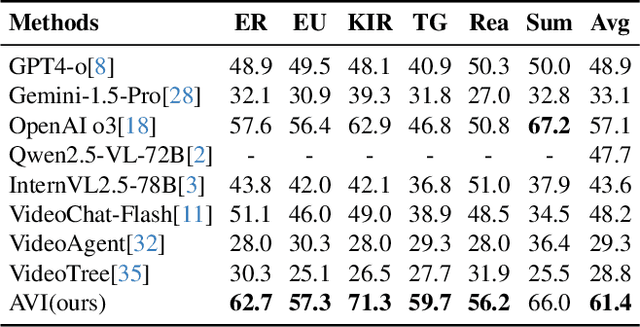
Video understanding requires not only visual recognition but also complex reasoning. While Vision-Language Models (VLMs) demonstrate impressive capabilities, they typically process videos largely in a single-pass manner with limited support for evidence revisit and iterative refinement. While recently emerging agent-based methods enable long-horizon reasoning, they either depend heavily on expensive proprietary models or require extensive agentic RL training. To overcome these limitations, we propose Agentic Video Intelligence (AVI), a flexible and training-free framework that can mirror human video comprehension through system-level design and optimization. AVI introduces three key innovations: (1) a human-inspired three-phase reasoning process (Retrieve-Perceive-Review) that ensures both sufficient global exploration and focused local analysis, (2) a structured video knowledge base organized through entity graphs, along with multi-granularity integrated tools, constituting the agent's interaction environment, and (3) an open-source model ensemble combining reasoning LLMs with lightweight base CV models and VLM, eliminating dependence on proprietary APIs or RL training. Experiments on LVBench, VideoMME-Long, LongVideoBench, and Charades-STA demonstrate that AVI achieves competitive performance while offering superior interpretability.
GraphPrompter: Multi-stage Adaptive Prompt Optimization for Graph In-Context Learning
May 04, 2025Graph In-Context Learning, with the ability to adapt pre-trained graph models to novel and diverse downstream graphs without updating any parameters, has gained much attention in the community. The key to graph in-context learning is to perform downstream graphs conditioned on chosen prompt examples. Existing methods randomly select subgraphs or edges as prompts, leading to noisy graph prompts and inferior model performance. Additionally, due to the gap between pre-training and testing graphs, when the number of classes in the testing graphs is much greater than that in the training, the in-context learning ability will also significantly deteriorate. To tackle the aforementioned challenges, we develop a multi-stage adaptive prompt optimization method GraphPrompter, which optimizes the entire process of generating, selecting, and using graph prompts for better in-context learning capabilities. Firstly, Prompt Generator introduces a reconstruction layer to highlight the most informative edges and reduce irrelevant noise for graph prompt construction. Furthermore, in the selection stage, Prompt Selector employs the $k$-nearest neighbors algorithm and pre-trained selection layers to dynamically choose appropriate samples and minimize the influence of irrelevant prompts. Finally, we leverage a Prompt Augmenter with a cache replacement strategy to enhance the generalization capability of the pre-trained model on new datasets. Extensive experiments show that GraphPrompter effectively enhances the in-context learning ability of graph models. On average across all the settings, our approach surpasses the state-of-the-art baselines by over 8%. Our code is released at https://github.com/karin0018/GraphPrompter.
Agent4Edu: Generating Learner Response Data by Generative Agents for Intelligent Education Systems
Jan 17, 2025



Personalized learning represents a promising educational strategy within intelligent educational systems, aiming to enhance learners' practice efficiency. However, the discrepancy between offline metrics and online performance significantly impedes their progress. To address this challenge, we introduce Agent4Edu, a novel personalized learning simulator leveraging recent advancements in human intelligence through large language models (LLMs). Agent4Edu features LLM-powered generative agents equipped with learner profile, memory, and action modules tailored to personalized learning algorithms. The learner profiles are initialized using real-world response data, capturing practice styles and cognitive factors. Inspired by human psychology theory, the memory module records practice facts and high-level summaries, integrating reflection mechanisms. The action module supports various behaviors, including exercise understanding, analysis, and response generation. Each agent can interact with personalized learning algorithms, such as computerized adaptive testing, enabling a multifaceted evaluation and enhancement of customized services. Through a comprehensive assessment, we explore the strengths and weaknesses of Agent4Edu, emphasizing the consistency and discrepancies in responses between agents and human learners. The code, data, and appendix are publicly available at https://github.com/bigdata-ustc/Agent4Edu.