 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Utilize Complementary Vision-Text Information for 2D Structure Understanding
Mar 17, 2026LLMs typically linearize 2D tables into 1D sequences to fit their autoregressive architecture, which weakens row-column adjacency and other layout cues. In contrast, purely visual encoders can capture spatial cues, yet often struggle to preserve exact cell text. Our analysis reveals that these two modalities provide highly distinct information to LLMs and exhibit strong complementarity. However, direct concatenation and other fusion methods yield limited gains and frequently introduce cross-modal interference. To address this issue, we propose DiVA-Former, a lightweight architecture designed to effectively integrate vision and text information. DiVA-Former leverages visual tokens as dynamic queries to distill long textual sequences into digest vectors, thereby effectively exploiting complementary vision--text information. Evaluated across 13 table benchmarks, DiVA-Former improves upon the pure-text baseline by 23.9\% and achieves consistent gains over existing baselines using visual inputs, textual inputs, or a combination of both.
MOSAIC: Composable Safety Alignment with Modular Control Tokens
Mar 17, 2026Safety alignment in large language models (LLMs) is commonly implemented as a single static policy embedded in model parameters. However, real-world deployments often require context-dependent safety rules that vary across users, regions, and applications. Existing approaches struggle to provide such conditional control: parameter-level alignment entangles safety behaviors with general capabilities, while prompt-based methods rely on natural language instructions that provide weak enforcement. We propose MOSAIC, a modular framework that enables compositional safety alignment through learnable control tokens optimized over a frozen backbone model. Each token represents a safety constraint and can be flexibly activated and composed at inference time. To train compositional tokens efficiently, we introduce order-based task sampling and a distribution-level alignment objective that mitigates over-refusal. Experiments show that MOSAIC achieves strong defense performance with substantially lower over-refusal while preserving model utility.
AdaSwitch: Adaptive Switching Generation for Knowledge Distillation
Oct 09, 2025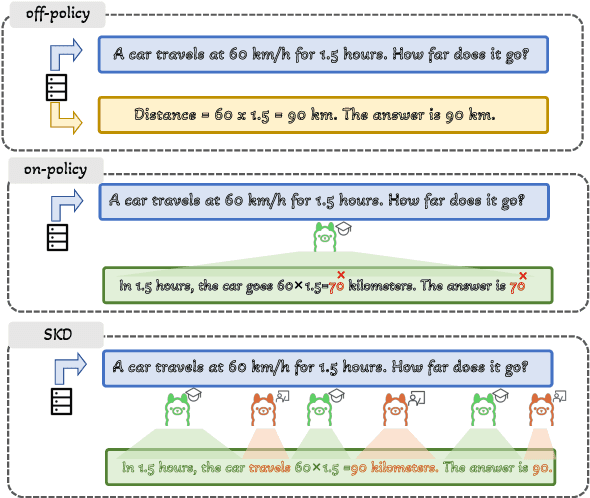
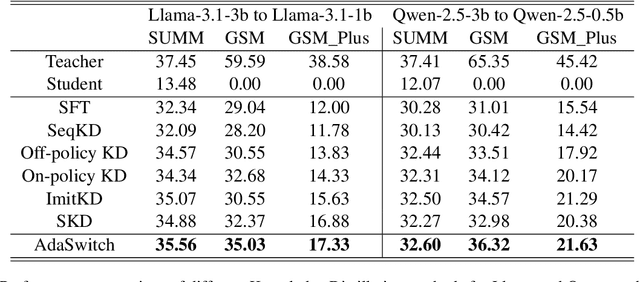
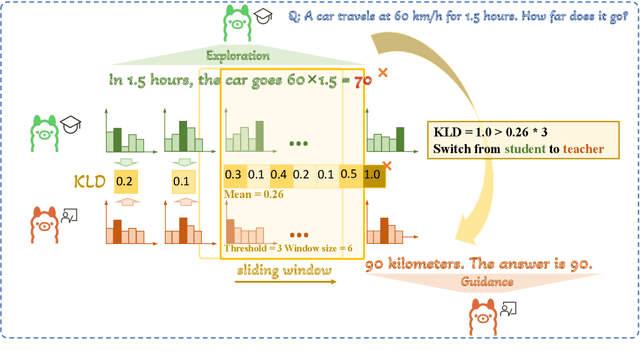
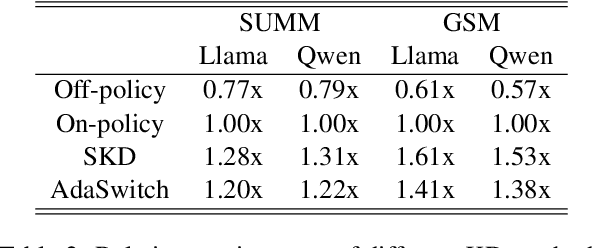
Small language models (SLMs) are crucial for applications with strict latency and computational constraints, yet achieving high performance remains challenging. Knowledge distillation (KD) can transfer capabilities from large teacher models, but existing methods involve trade-offs: off-policy distillation provides high-quality supervision but introduces a training-inference mismatch, while on-policy approaches maintain consistency but rely on low-quality student outputs. To address these issues, we propose AdaSwitch, a novel approach that dynamically combines on-policy and off-policy generation at the token level. AdaSwitch allows the student to first explore its own predictions and then selectively integrate teacher guidance based on real-time quality assessment. This approach simultaneously preserves consistency and maintains supervision quality. Experiments on three datasets with two teacher-student LLM pairs demonstrate that AdaSwitch consistently improves accuracy, offering a practical and effective method for distilling SLMs with acceptable additional overhead.
Stepwise Reasoning Error Disruption Attack of LLMs
Dec 16, 2024



Large language models (LLMs) have made remarkable strides in complex reasoning tasks, but their safety and robustness in reasoning processes remain underexplored. Existing attacks on LLM reasoning are constrained by specific settings or lack of imperceptibility, limiting their feasibility and generalizability. To address these challenges, we propose the Stepwise rEasoning Error Disruption (SEED) attack, which subtly injects errors into prior reasoning steps to mislead the model into producing incorrect subsequent reasoning and final answers. Unlike previous methods, SEED is compatible with zero-shot and few-shot settings, maintains the natural reasoning flow, and ensures covert execution without modifying the instruction. Extensive experiments on four datasets across four different models demonstrate SEED's effectiveness, revealing the vulnerabilities of LLMs to disruptions in reasoning processes. These findings underscore the need for greater attention to the robustness of LLM reasoning to ensure safety in practical applications.
Towards Few-shot Self-explaining Graph Neural Networks
Aug 14, 2024Recent advancements in Graph Neural Networks (GNNs) have spurred an upsurge of research dedicated to enhancing the explainability of GNNs, particularly in critical domains such as medicine. A promising approach is the self-explaining method, which outputs explanations along with predictions. However, existing self-explaining models require a large amount of training data, rendering them unavailable in few-shot scenarios. To address this challenge, in this paper, we propose a Meta-learned Self-Explaining GNN (MSE-GNN), a novel framework that generates explanations to support predictions in few-shot settings. MSE-GNN adopts a two-stage self-explaining structure, consisting of an explainer and a predictor. Specifically, the explainer first imitates the attention mechanism of humans to select the explanation subgraph, whereby attention is naturally paid to regions containing important characteristics. Subsequently, the predictor mimics the decision-making process, which makes predictions based on the generated explanation. Moreover, with a novel meta-training process and a designed mechanism that exploits task information, MSE-GNN can achieve remarkable performance on new few-shot tasks. Extensive experimental results on four datasets demonstrate that MSE-GNN can achieve superior performance on prediction tasks while generating high-quality explanations compared with existing methods. The code is publicly available at https://github.com/jypeng28/MSE-GNN.