 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdu-Theater: A Data-Efficient Agent Framework for Scalable Learner Behavior Simulation through Staging Roll-Call
Jun 13, 2026Large-scale learner-task interaction data are crucial for intelligent educational systems but are costly to collect and constrained by privacy and learner engagement. Learner simulators play a critical role in simulating scalable learner behavior without the need for continuous involvement of real learners. However, existing methods are predominantly \textbf{individual-centric}, pairing a simulator with each learner to iteratively infer latent knowledge states from dense interaction histories, which is both data- and computation-intensive, and fragile in cold-start scenarios. We propose a \textbf{cohort-aware roll-call simulation paradigm} that first constructs cohort-level proficiency priors and refines individual learner states through a small number of targeted diagnostic queries. Based on this paradigm, we introduce \textbf{Edu-Theater}, an LLM-powered agent system that performs cohort-aware learner simulation via a teacher agent and retrospective roll-call probing over learner logs. Edu-Theater enables scalable future behavior simulation without the need for dense per-learner histories. Experiments on two real-world datasets demonstrate that Edu-Theater achieves higher simulation accuracy with significantly fewer LLM calls, producing synthetic data that enhances downstream applications such as adaptive testing.
Guided by Trajectories: Repairing and Rewarding Tool-Use Trajectories for Tool-Integrated Reasoning
Jan 30, 2026Tool-Integrated Reasoning (TIR) enables large language models (LLMs) to solve complex tasks by interacting with external tools, yet existing approaches depend on high-quality synthesized trajectories selected by scoring functions and sparse outcome-based rewards, providing limited and biased supervision for learning TIR. To address these challenges, in this paper, we propose AutoTraj, a two-stage framework that automatically learns TIR by repairing and rewarding tool-use trajectories. Specifically, in the supervised fine-tuning (SFT) stage, AutoTraj generates multiple candidate tool-use trajectories for each query and evaluates them along multiple dimensions. High-quality trajectories are directly retained, while low-quality ones are repaired using a LLM (i.e., LLM-as-Repairer). The resulting repaired and high-quality trajectories form a synthetic SFT dataset, while each repaired trajectory paired with its original low-quality counterpart constitutes a dataset for trajectory preference modeling. In the reinforcement learning (RL) stage, based on the preference dataset, we train a trajectory-level reward model to assess the quality of reasoning paths and combine it with outcome and format rewards, thereby explicitly guiding the optimization toward reliable TIR behaviors. Experiments on real-world benchmarks demonstrate the effectiveness of AutoTraj in TIR.
GraphPrompter: Multi-stage Adaptive Prompt Optimization for Graph In-Context Learning
May 04, 2025Graph In-Context Learning, with the ability to adapt pre-trained graph models to novel and diverse downstream graphs without updating any parameters, has gained much attention in the community. The key to graph in-context learning is to perform downstream graphs conditioned on chosen prompt examples. Existing methods randomly select subgraphs or edges as prompts, leading to noisy graph prompts and inferior model performance. Additionally, due to the gap between pre-training and testing graphs, when the number of classes in the testing graphs is much greater than that in the training, the in-context learning ability will also significantly deteriorate. To tackle the aforementioned challenges, we develop a multi-stage adaptive prompt optimization method GraphPrompter, which optimizes the entire process of generating, selecting, and using graph prompts for better in-context learning capabilities. Firstly, Prompt Generator introduces a reconstruction layer to highlight the most informative edges and reduce irrelevant noise for graph prompt construction. Furthermore, in the selection stage, Prompt Selector employs the $k$-nearest neighbors algorithm and pre-trained selection layers to dynamically choose appropriate samples and minimize the influence of irrelevant prompts. Finally, we leverage a Prompt Augmenter with a cache replacement strategy to enhance the generalization capability of the pre-trained model on new datasets. Extensive experiments show that GraphPrompter effectively enhances the in-context learning ability of graph models. On average across all the settings, our approach surpasses the state-of-the-art baselines by over 8%. Our code is released at https://github.com/karin0018/GraphPrompter.
Agent4Edu: Generating Learner Response Data by Generative Agents for Intelligent Education Systems
Jan 17, 2025



Personalized learning represents a promising educational strategy within intelligent educational systems, aiming to enhance learners' practice efficiency. However, the discrepancy between offline metrics and online performance significantly impedes their progress. To address this challenge, we introduce Agent4Edu, a novel personalized learning simulator leveraging recent advancements in human intelligence through large language models (LLMs). Agent4Edu features LLM-powered generative agents equipped with learner profile, memory, and action modules tailored to personalized learning algorithms. The learner profiles are initialized using real-world response data, capturing practice styles and cognitive factors. Inspired by human psychology theory, the memory module records practice facts and high-level summaries, integrating reflection mechanisms. The action module supports various behaviors, including exercise understanding, analysis, and response generation. Each agent can interact with personalized learning algorithms, such as computerized adaptive testing, enabling a multifaceted evaluation and enhancement of customized services. Through a comprehensive assessment, we explore the strengths and weaknesses of Agent4Edu, emphasizing the consistency and discrepancies in responses between agents and human learners. The code, data, and appendix are publicly available at https://github.com/bigdata-ustc/Agent4Edu.
Collaborative Cognitive Diagnosis with Disentangled Representation Learning for Learner Modeling
Nov 04, 2024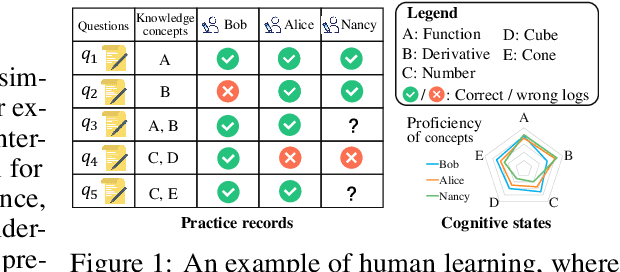
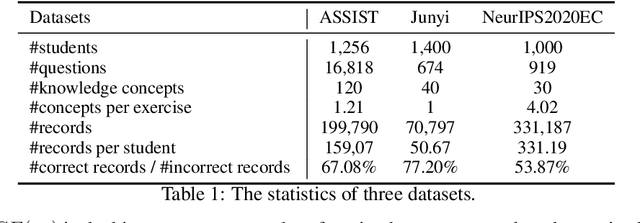
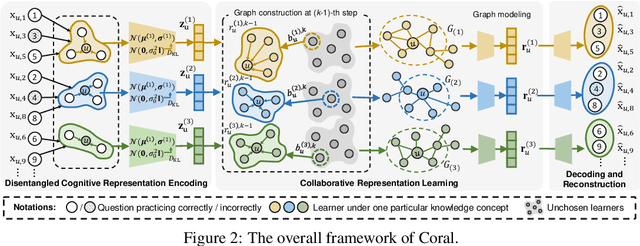
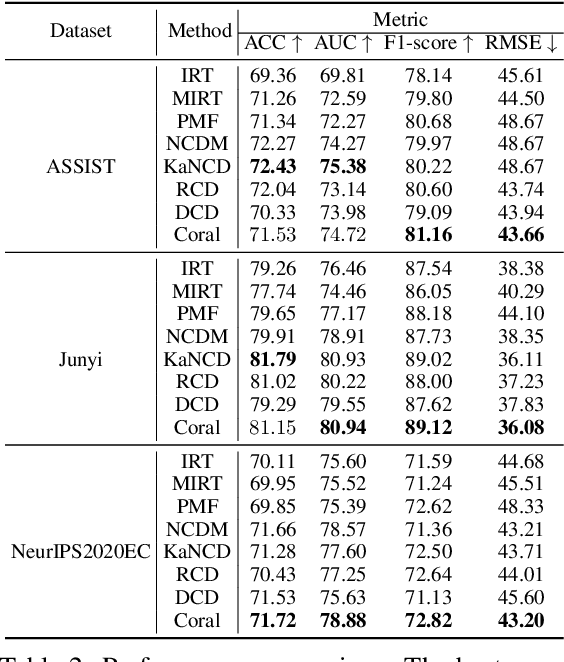
Learners sharing similar implicit cognitive states often display comparable observable problem-solving performances. Leveraging collaborative connections among such similar learners proves valuable in comprehending human learning. Motivated by the success of collaborative modeling in various domains, such as recommender systems, we aim to investigate how collaborative signals among learners contribute to the diagnosis of human cognitive states (i.e., knowledge proficiency) in the context of intelligent education. The primary challenges lie in identifying implicit collaborative connections and disentangling the entangled cognitive factors of learners for improved explainability and controllability in learner Cognitive Diagnosis (CD). However, there has been no work on CD capable of simultaneously modeling collaborative and disentangled cognitive states. To address this gap, we present Coral, a Collaborative cognitive diagnosis model with disentangled representation learning. Specifically, Coral first introduces a disentangled state encoder to achieve the initial disentanglement of learners' states. Subsequently, a meticulously designed collaborative representation learning procedure captures collaborative signals. It dynamically constructs a collaborative graph of learners by iteratively searching for optimal neighbors in a context-aware manner. Using the constructed graph, collaborative information is extracted through node representation learning. Finally, a decoding process aligns the initial cognitive states and collaborative states, achieving co-disentanglement with practice performance reconstructions. Extensive experiments demonstrate the superior performance of Coral, showcasing significant improvements over state-of-the-art methods across several real-world datasets. Our code is available at https://github.com/bigdata-ustc/Coral.
Cooperative Classification and Rationalization for Graph Generalization
Mar 10, 2024



Graph Neural Networks (GNNs) have achieved impressive results in graph classification tasks, but they struggle to generalize effectively when faced with out-of-distribution (OOD) data. Several approaches have been proposed to address this problem. Among them, one solution is to diversify training distributions in vanilla classification by modifying the data environment, yet accessing the environment information is complex. Besides, another promising approach involves rationalization, extracting invariant rationales for predictions. However, extracting rationales is difficult due to limited learning signals, resulting in less accurate rationales and diminished predictions. To address these challenges, in this paper, we propose a Cooperative Classification and Rationalization (C2R) method, consisting of the classification and the rationalization module. Specifically, we first assume that multiple environments are available in the classification module. Then, we introduce diverse training distributions using an environment-conditional generative network, enabling robust graph representations. Meanwhile, the rationalization module employs a separator to identify relevant rationale subgraphs while the remaining non-rationale subgraphs are de-correlated with labels. Next, we align graph representations from the classification module with rationale subgraph representations using the knowledge distillation methods, enhancing the learning signal for rationales. Finally, we infer multiple environments by gathering non-rationale representations and incorporate them into the classification module for cooperative learning. Extensive experimental results on both benchmarks and synthetic datasets demonstrate the effectiveness of C2R. Code is available at https://github.com/yuelinan/Codes-of-C2R.
Zero-1-to-3: Domain-level Zero-shot Cognitive Diagnosis via One Batch of Early-bird Students towards Three Diagnostic Objectives
Dec 22, 2023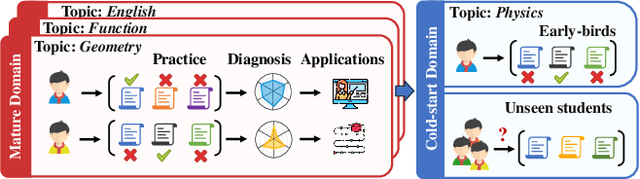

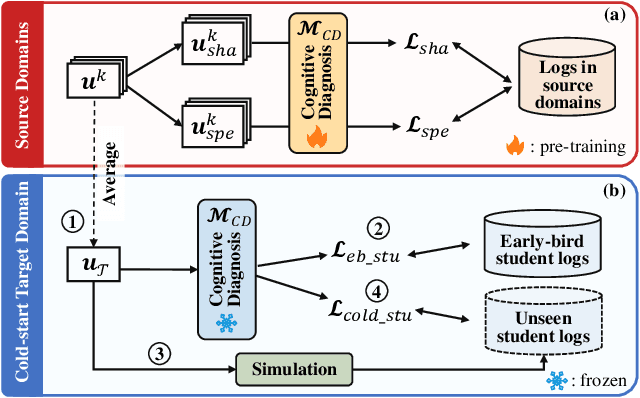
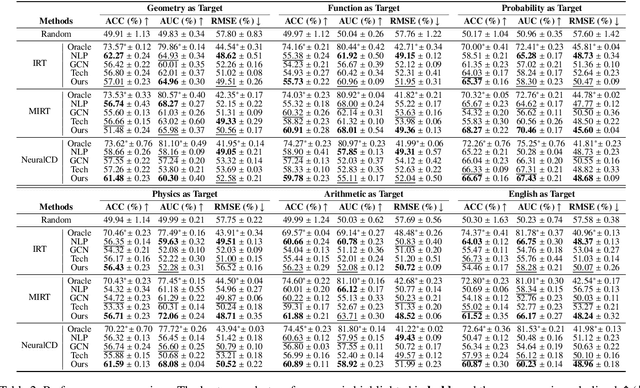
Cognitive diagnosis seeks to estimate the cognitive states of students by exploring their logged practice quiz data. It plays a pivotal role in personalized learning guidance within intelligent education systems. In this paper, we focus on an important, practical, yet often underexplored task: domain-level zero-shot cognitive diagnosis (DZCD), which arises due to the absence of student practice logs in newly launched domains. Recent cross-domain diagnostic models have been demonstrated to be a promising strategy for DZCD. These methods primarily focus on how to transfer student states across domains. However, they might inadvertently incorporate non-transferable information into student representations, thereby limiting the efficacy of knowledge transfer. To tackle this, we propose Zero-1-to-3, a domain-level zero-shot cognitive diagnosis framework via one batch of early-bird students towards three diagnostic objectives. Our approach initiates with pre-training a diagnosis model with dual regularizers, which decouples student states into domain-shared and domain-specific parts. The shared cognitive signals can be transferred to the target domain, enriching the cognitive priors for the new domain, which ensures the cognitive state propagation objective. Subsequently, we devise a strategy to generate simulated practice logs for cold-start students through analyzing the behavioral patterns from early-bird students, fulfilling the domain-adaption goal. Consequently, we refine the cognitive states of cold-start students as diagnostic outcomes via virtual data, aligning with the diagnosis-oriented goal. Finally, extensive experiments on six real-world datasets highlight the efficacy of our model for DZCD and its practical application in question recommendation.
FedJudge: Federated Legal Large Language Model
Sep 15, 2023
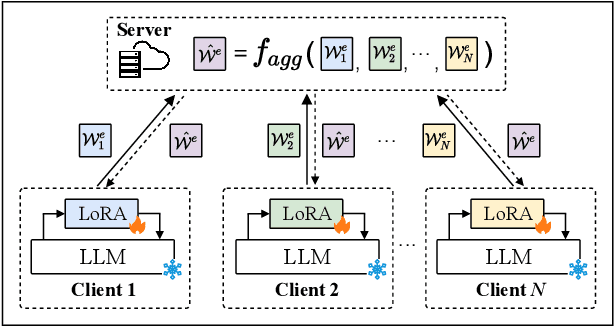
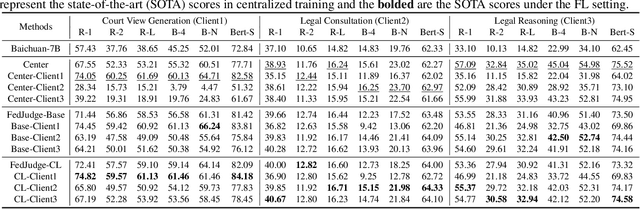
Large Language Models (LLMs) have gained prominence in the field of Legal Intelligence, offering potential applications in assisting legal professionals and laymen. However, the centralized training of these Legal LLMs raises data privacy concerns, as legal data is distributed among various institutions containing sensitive individual information. This paper addresses this challenge by exploring the integration of Legal LLMs with Federated Learning (FL) methodologies. By employing FL, Legal LLMs can be fine-tuned locally on devices or clients, and their parameters are aggregated and distributed on a central server, ensuring data privacy without directly sharing raw data. However, computation and communication overheads hinder the full fine-tuning of LLMs under the FL setting. Moreover, the distribution shift of legal data reduces the effectiveness of FL methods. To this end, in this paper, we propose the first Federated Legal Large Language Model (FedJudge) framework, which fine-tunes Legal LLMs efficiently and effectively. Specifically, FedJudge utilizes parameter-efficient fine-tuning methods to update only a few additional parameters during the FL training. Besides, we explore the continual learning methods to preserve the global model's important parameters when training local clients to mitigate the problem of data shifts. Extensive experimental results on three real-world datasets clearly validate the effectiveness of FedJudge. Code is released at https://github.com/yuelinan/FedJudge.