 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Computerized Adaptive Testing: A Machine Learning Perspective
Apr 05, 2024Computerized Adaptive Testing (CAT) provides an efficient and tailored method for assessing the proficiency of examinees, by dynamically adjusting test questions based on their performance. Widely adopted across diverse fields like education, healthcare, sports, and sociology, CAT has revolutionized testing practices. While traditional methods rely on psychometrics and statistics, the increasing complexity of large-scale testing has spurred the integration of machine learning techniques. This paper aims to provide a machine learning-focused survey on CAT, presenting a fresh perspective on this adaptive testing method. By examining the test question selection algorithm at the heart of CAT's adaptivity, we shed light on its functionality. Furthermore, we delve into cognitive diagnosis models, question bank construction, and test control within CAT, exploring how machine learning can optimize these components. Through an analysis of current methods, strengths, limitations, and challenges, we strive to develop robust, fair, and efficient CAT systems. By bridging psychometric-driven CAT research with machine learning, this survey advocates for a more inclusive and interdisciplinary approach to the future of adaptive testing.
A Dataset for the Validation of Truth Inference Algorithms Suitable for Online Deployment
Mar 10, 2024



For the purpose of efficient and cost-effective large-scale data labeling, crowdsourcing is increasingly being utilized. To guarantee the quality of data labeling, multiple annotations need to be collected for each data sample, and truth inference algorithms have been developed to accurately infer the true labels. Despite previous studies having released public datasets to evaluate the efficacy of truth inference algorithms, these have typically focused on a single type of crowdsourcing task and neglected the temporal information associated with workers' annotation activities. These limitations significantly restrict the practical applicability of these algorithms, particularly in the context of long-term and online truth inference. In this paper, we introduce a substantial crowdsourcing annotation dataset collected from a real-world crowdsourcing platform. This dataset comprises approximately two thousand workers, one million tasks, and six million annotations. The data was gathered over a period of approximately six months from various types of tasks, and the timestamps of each annotation were preserved. We analyze the characteristics of the dataset from multiple perspectives and evaluate the effectiveness of several representative truth inference algorithms on this dataset. We anticipate that this dataset will stimulate future research on tracking workers' abilities over time in relation to different types of tasks, as well as enhancing online truth inference.
Zero-1-to-3: Domain-level Zero-shot Cognitive Diagnosis via One Batch of Early-bird Students towards Three Diagnostic Objectives
Dec 22, 2023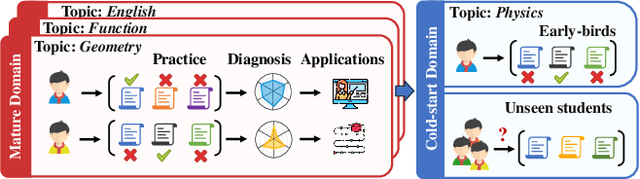

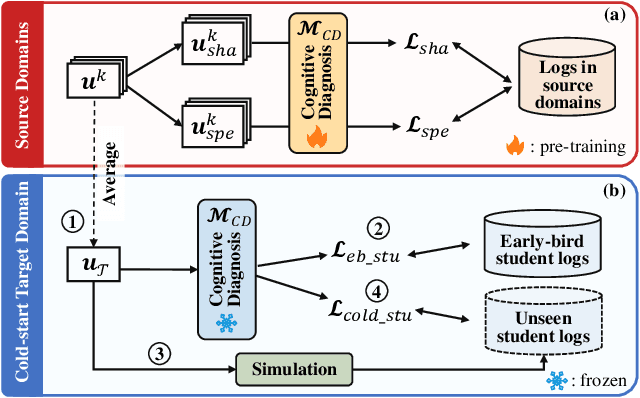
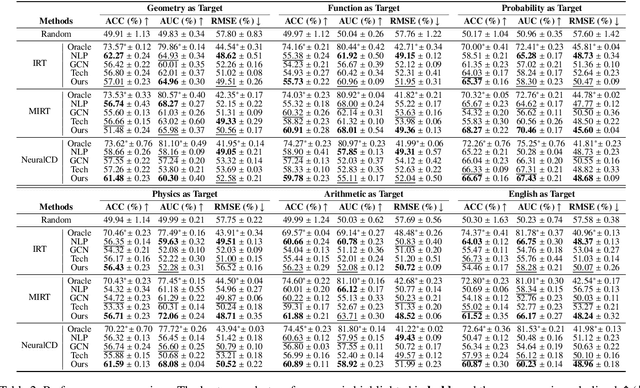
Cognitive diagnosis seeks to estimate the cognitive states of students by exploring their logged practice quiz data. It plays a pivotal role in personalized learning guidance within intelligent education systems. In this paper, we focus on an important, practical, yet often underexplored task: domain-level zero-shot cognitive diagnosis (DZCD), which arises due to the absence of student practice logs in newly launched domains. Recent cross-domain diagnostic models have been demonstrated to be a promising strategy for DZCD. These methods primarily focus on how to transfer student states across domains. However, they might inadvertently incorporate non-transferable information into student representations, thereby limiting the efficacy of knowledge transfer. To tackle this, we propose Zero-1-to-3, a domain-level zero-shot cognitive diagnosis framework via one batch of early-bird students towards three diagnostic objectives. Our approach initiates with pre-training a diagnosis model with dual regularizers, which decouples student states into domain-shared and domain-specific parts. The shared cognitive signals can be transferred to the target domain, enriching the cognitive priors for the new domain, which ensures the cognitive state propagation objective. Subsequently, we devise a strategy to generate simulated practice logs for cold-start students through analyzing the behavioral patterns from early-bird students, fulfilling the domain-adaption goal. Consequently, we refine the cognitive states of cold-start students as diagnostic outcomes via virtual data, aligning with the diagnosis-oriented goal. Finally, extensive experiments on six real-world datasets highlight the efficacy of our model for DZCD and its practical application in question recommendation.
Quality meets Diversity: A Model-Agnostic Framework for Computerized Adaptive Testing
Jan 15, 2021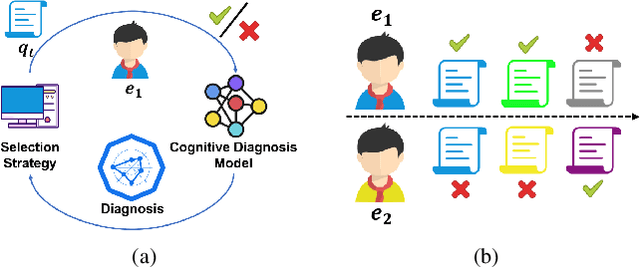
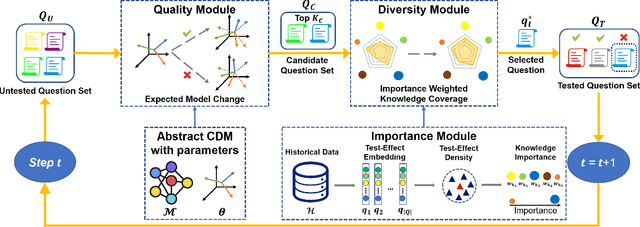
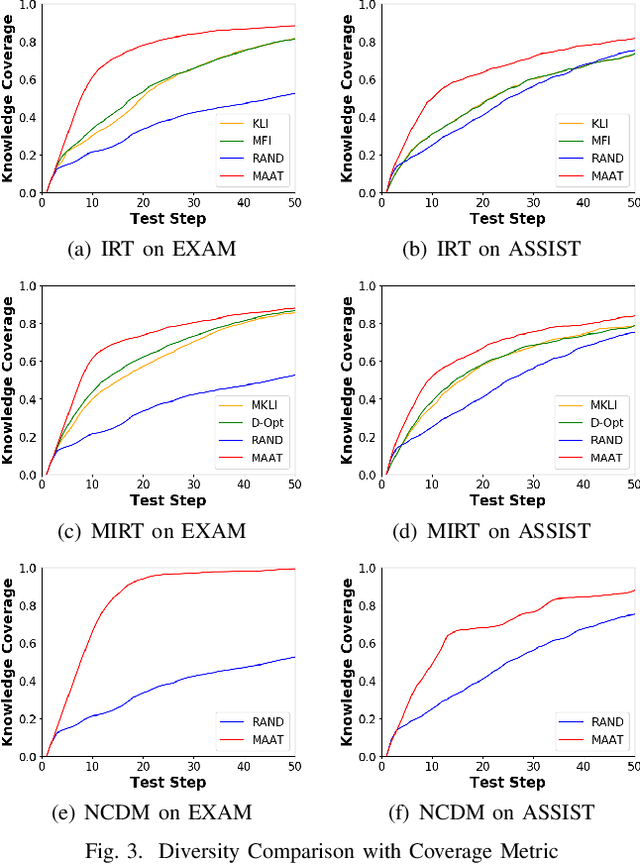
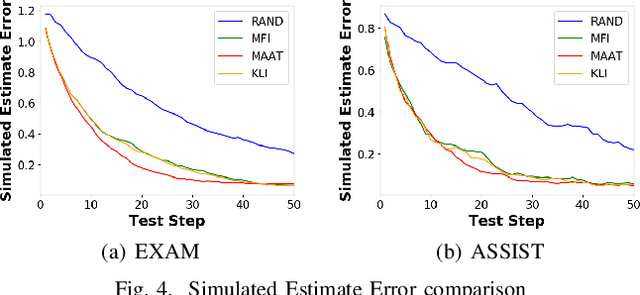
Computerized Adaptive Testing (CAT) is emerging as a promising testing application in many scenarios, such as education, game and recruitment, which targets at diagnosing the knowledge mastery levels of examinees on required concepts. It shows the advantage of tailoring a personalized testing procedure for each examinee, which selects questions step by step, depending on her performance. While there are many efforts on developing CAT systems, existing solutions generally follow an inflexible model-specific fashion. That is, they need to observe a specific cognitive model which can estimate examinee's knowledge levels and design the selection strategy according to the model estimation. In this paper, we study a novel model-agnostic CAT problem, where we aim to propose a flexible framework that can adapt to different cognitive models. Meanwhile, this work also figures out CAT solution with addressing the problem of how to generate both high-quality and diverse questions simultaneously, which can give a comprehensive knowledge diagnosis for each examinee. Inspired by Active Learning, we propose a novel framework, namely Model-Agnostic Adaptive Testing (MAAT) for CAT solution, where we design three sophisticated modules including Quality Module, Diversity Module and Importance Module. Extensive experimental results on two real-world datasets clearly demonstrate that our MAAT can support CAT with guaranteeing both quality and diversity perspectives.