 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Time Series Forecasting via Instance-aware Post-hoc Revision
May 29, 2025Time series forecasting plays a vital role in various real-world applications and has attracted significant attention in recent decades. While recent methods have achieved remarkable accuracy by incorporating advanced inductive biases and training strategies, we observe that instance-level variations remain a significant challenge. These variations--stemming from distribution shifts, missing data, and long-tail patterns--often lead to suboptimal forecasts for specific instances, even when overall performance appears strong. To address this issue, we propose a model-agnostic framework, PIR, designed to enhance forecasting performance through Post-forecasting Identification and Revision. Specifically, PIR first identifies biased forecasting instances by estimating their accuracy. Based on this, the framework revises the forecasts using contextual information, including covariates and historical time series, from both local and global perspectives in a post-processing fashion. Extensive experiments on real-world datasets with mainstream forecasting models demonstrate that PIR effectively mitigates instance-level errors and significantly improves forecasting reliability.
DisenTS: Disentangled Channel Evolving Pattern Modeling for Multivariate Time Series Forecasting
Oct 30, 2024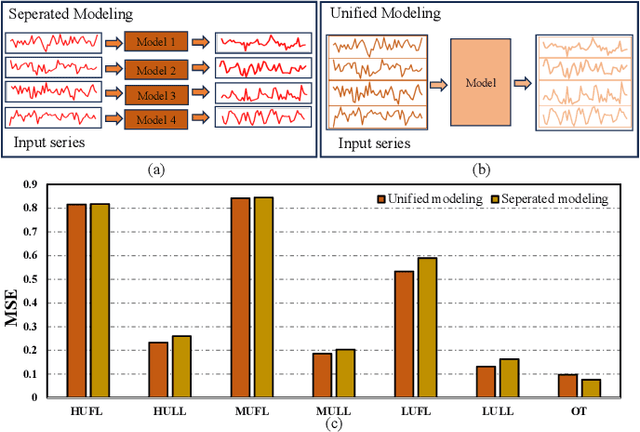
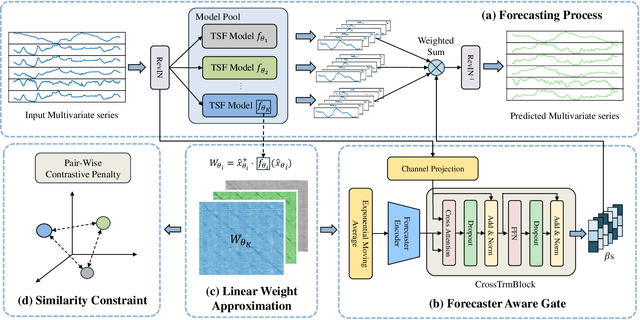

Multivariate time series forecasting plays a crucial role in various real-world applications. Significant efforts have been made to integrate advanced network architectures and training strategies that enhance the capture of temporal dependencies, thereby improving forecasting accuracy. On the other hand, mainstream approaches typically utilize a single unified model with simplistic channel-mixing embedding or cross-channel attention operations to account for the critical intricate inter-channel dependencies. Moreover, some methods even trade capacity for robust prediction based on the channel-independent assumption. Nonetheless, as time series data may display distinct evolving patterns due to the unique characteristics of each channel (including multiple strong seasonalities and trend changes), the unified modeling methods could yield suboptimal results. To this end, we propose DisenTS, a tailored framework for modeling disentangled channel evolving patterns in general multivariate time series forecasting. The central idea of DisenTS is to model the potential diverse patterns within the multivariate time series data in a decoupled manner. Technically, the framework employs multiple distinct forecasting models, each tasked with uncovering a unique evolving pattern. To guide the learning process without supervision of pattern partition, we introduce a novel Forecaster Aware Gate (FAG) module that generates the routing signals adaptively according to both the forecasters' states and input series' characteristics. The forecasters' states are derived from the Linear Weight Approximation (LWA) strategy, which quantizes the complex deep neural networks into compact matrices. Additionally, the Similarity Constraint (SC) is further proposed to guide each model to specialize in an underlying pattern by minimizing the mutual information between the representations.
Towards Personalized Evaluation of Large Language Models with An Anonymous Crowd-Sourcing Platform
Mar 13, 2024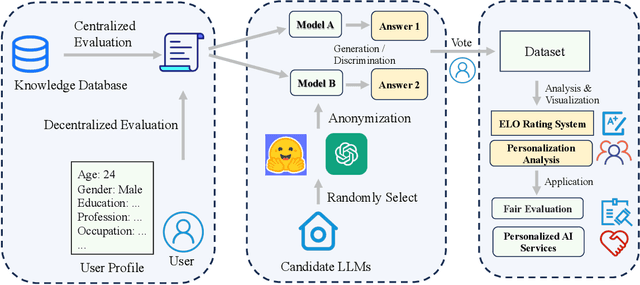
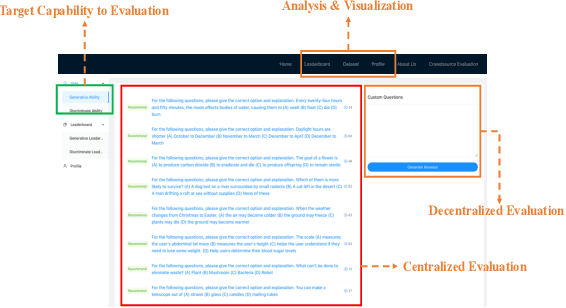
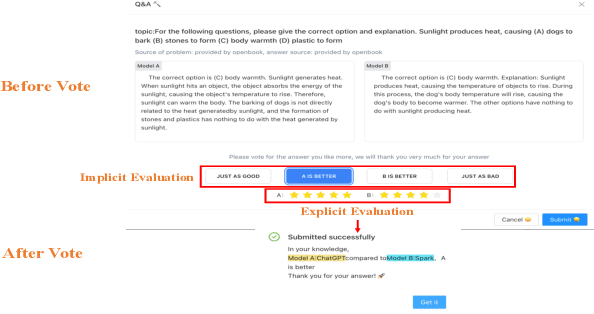
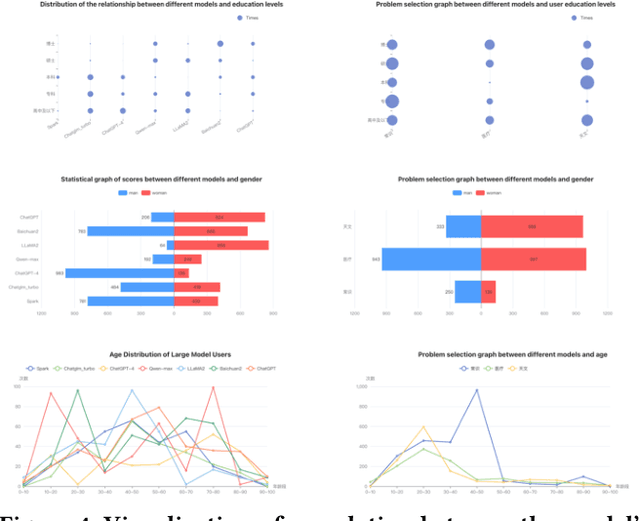
Large language model evaluation plays a pivotal role in the enhancement of its capacity. Previously, numerous methods for evaluating large language models have been proposed in this area. Despite their effectiveness, these existing works mainly focus on assessing objective questions, overlooking the capability to evaluate subjective questions which is extremely common for large language models. Additionally, these methods predominantly utilize centralized datasets for evaluation, with question banks concentrated within the evaluation platforms themselves. Moreover, the evaluation processes employed by these platforms often overlook personalized factors, neglecting to consider the individual characteristics of both the evaluators and the models being evaluated. To address these limitations, we propose a novel anonymous crowd-sourcing evaluation platform, BingJian, for large language models that employs a competitive scoring mechanism where users participate in ranking models based on their performance. This platform stands out not only for its support of centralized evaluations to assess the general capabilities of models but also for offering an open evaluation gateway. Through this gateway, users have the opportunity to submit their questions, testing the models on a personalized and potentially broader range of capabilities. Furthermore, our platform introduces personalized evaluation scenarios, leveraging various forms of human-computer interaction to assess large language models in a manner that accounts for individual user preferences and contexts. The demonstration of BingJian can be accessed at https://github.com/Mingyue-Cheng/Bingjian.
ConvTimeNet: A Deep Hierarchical Fully Convolutional Model for Multivariate Time Series Analysis
Mar 03, 2024



This paper introduces ConvTimeNet, a novel deep hierarchical fully convolutional network designed to serve as a general-purpose model for time series analysis. The key design of this network is twofold, designed to overcome the limitations of traditional convolutional networks. Firstly, we propose an adaptive segmentation of time series into sub-series level patches, treating these as fundamental modeling units. This setting avoids the sparsity semantics associated with raw point-level time steps. Secondly, we design a fully convolutional block by skillfully integrating deepwise and pointwise convolution operations, following the advanced building block style employed in Transformer encoders. This backbone network allows for the effective capture of both global sequence and cross-variable dependence, as it not only incorporates the advancements of Transformer architecture but also inherits the inherent properties of convolution. Furthermore, multi-scale representations of given time series instances can be learned by controlling the kernel size flexibly. Extensive experiments are conducted on both time series forecasting and classification tasks. The results consistently outperformed strong baselines in most situations in terms of effectiveness.The code is publicly available.
Generative Pretrained Hierarchical Transformer for Time Series Forecasting
Feb 26, 2024



Recent efforts have been dedicated to enhancing time series forecasting accuracy by introducing advanced network architectures and self-supervised pretraining strategies. Nevertheless, existing approaches still exhibit two critical drawbacks. Firstly, these methods often rely on a single dataset for training, limiting the model's generalizability due to the restricted scale of the training data. Secondly, the one-step generation schema is widely followed, which necessitates a customized forecasting head and overlooks the temporal dependencies in the output series, and also leads to increased training costs under different horizon length settings. To address these issues, we propose a novel generative pretrained hierarchical transformer architecture for forecasting, named GPHT. There are two aspects of key designs in GPHT. On the one hand, we advocate for constructing a mixed dataset for pretraining our model, comprising various datasets from diverse data scenarios. This approach significantly expands the scale of training data, allowing our model to uncover commonalities in time series data and facilitating improved transfer to specific datasets. On the other hand, GPHT employs an auto-regressive forecasting approach under the channel-independent assumption, effectively modeling temporal dependencies in the output series. Importantly, no customized forecasting head is required, enabling a single model to forecast at arbitrary horizon settings. We conduct sufficient experiments on eight datasets with mainstream self-supervised pretraining models and supervised models. The results demonstrated that GPHT surpasses the baseline models across various fine-tuning and zero/few-shot learning settings in the traditional long-term forecasting task, providing support for verifying the feasibility of pretrained time series large models.