 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBestServe: Serving Strategies with Optimal Goodput in Collocation and Disaggregation Architectures
Jun 06, 2025Serving large language models (LLMs) to millions of users requires efficient resource allocation and parallelism strategies. It is a labor intensive trial-and-error process to find such a strategy. We present BestServe, a novel framework for ranking serving strategies by estimating goodput under various operating scenarios. Supporting both collocated and disaggregated architectures, BestServe leverages an inference simulator built on an adapted roofline model and CPU-GPU dispatch dynamics. Our framework determines the optimal strategy in minutes on a single standard CPU, eliminating the need for costly benchmarking, while achieving predictions within a $20\%$ error margin. It appeals to be practical for rapid deployment planning because of its lightweight design and strong extensibility.
Towards Personalized Evaluation of Large Language Models with An Anonymous Crowd-Sourcing Platform
Mar 13, 2024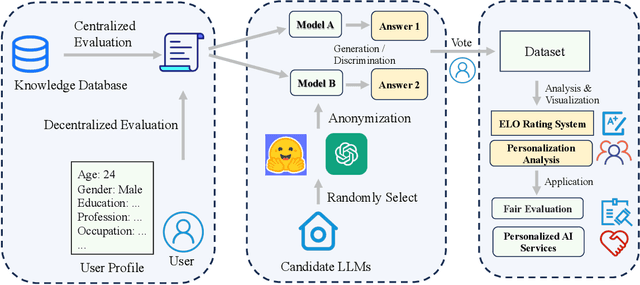
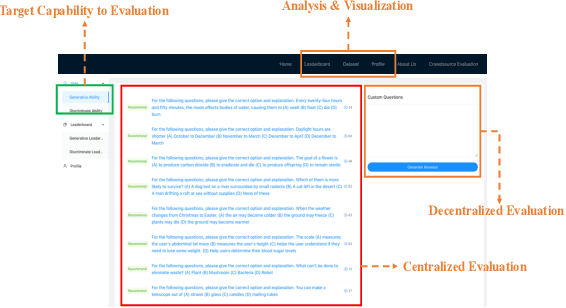
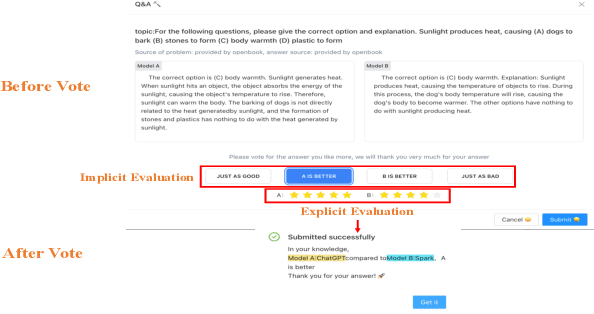
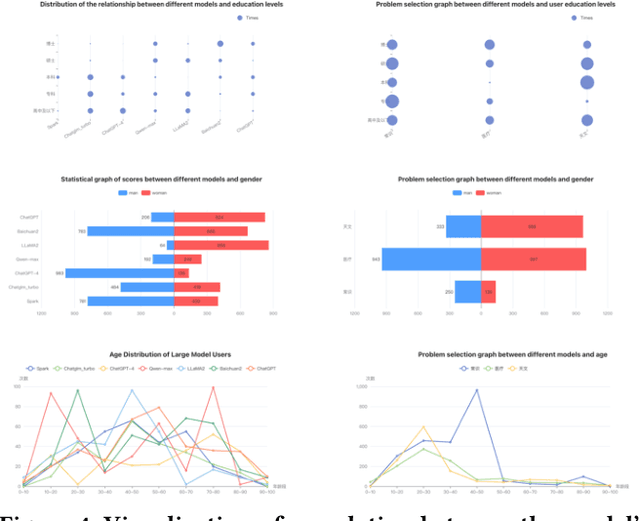
Large language model evaluation plays a pivotal role in the enhancement of its capacity. Previously, numerous methods for evaluating large language models have been proposed in this area. Despite their effectiveness, these existing works mainly focus on assessing objective questions, overlooking the capability to evaluate subjective questions which is extremely common for large language models. Additionally, these methods predominantly utilize centralized datasets for evaluation, with question banks concentrated within the evaluation platforms themselves. Moreover, the evaluation processes employed by these platforms often overlook personalized factors, neglecting to consider the individual characteristics of both the evaluators and the models being evaluated. To address these limitations, we propose a novel anonymous crowd-sourcing evaluation platform, BingJian, for large language models that employs a competitive scoring mechanism where users participate in ranking models based on their performance. This platform stands out not only for its support of centralized evaluations to assess the general capabilities of models but also for offering an open evaluation gateway. Through this gateway, users have the opportunity to submit their questions, testing the models on a personalized and potentially broader range of capabilities. Furthermore, our platform introduces personalized evaluation scenarios, leveraging various forms of human-computer interaction to assess large language models in a manner that accounts for individual user preferences and contexts. The demonstration of BingJian can be accessed at https://github.com/Mingyue-Cheng/Bingjian.
Mitigating Membership Inference Attacks by Self-Distillation Through a Novel Ensemble Architecture
Oct 15, 2021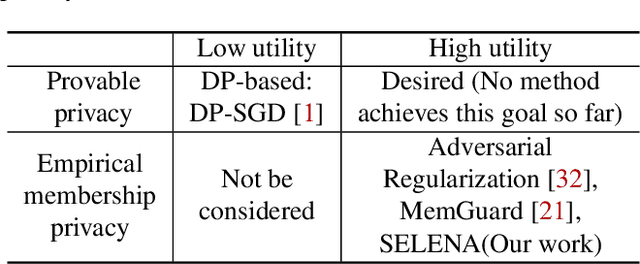

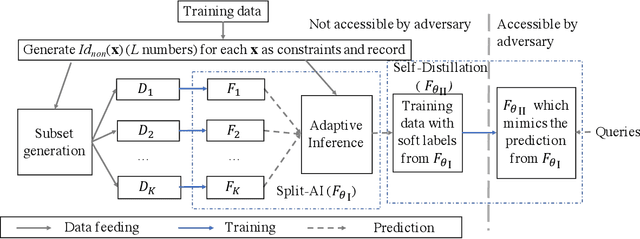
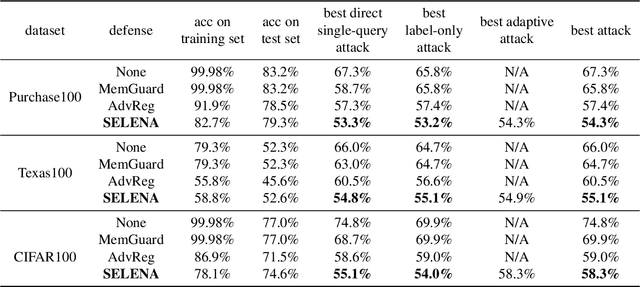
Membership inference attacks are a key measure to evaluate privacy leakage in machine learning (ML) models. These attacks aim to distinguish training members from non-members by exploiting differential behavior of the models on member and non-member inputs. The goal of this work is to train ML models that have high membership privacy while largely preserving their utility; we therefore aim for an empirical membership privacy guarantee as opposed to the provable privacy guarantees provided by techniques like differential privacy, as such techniques are shown to deteriorate model utility. Specifically, we propose a new framework to train privacy-preserving models that induces similar behavior on member and non-member inputs to mitigate membership inference attacks. Our framework, called SELENA, has two major components. The first component and the core of our defense is a novel ensemble architecture for training. This architecture, which we call Split-AI, splits the training data into random subsets, and trains a model on each subset of the data. We use an adaptive inference strategy at test time: our ensemble architecture aggregates the outputs of only those models that did not contain the input sample in their training data. We prove that our Split-AI architecture defends against a large family of membership inference attacks, however, it is susceptible to new adaptive attacks. Therefore, we use a second component in our framework called Self-Distillation to protect against such stronger attacks. The Self-Distillation component (self-)distills the training dataset through our Split-AI ensemble, without using any external public datasets. Through extensive experiments on major benchmark datasets we show that SELENA presents a superior trade-off between membership privacy and utility compared to the state of the art.
A Critical Evaluation of Open-World Machine Learning
Jul 08, 2020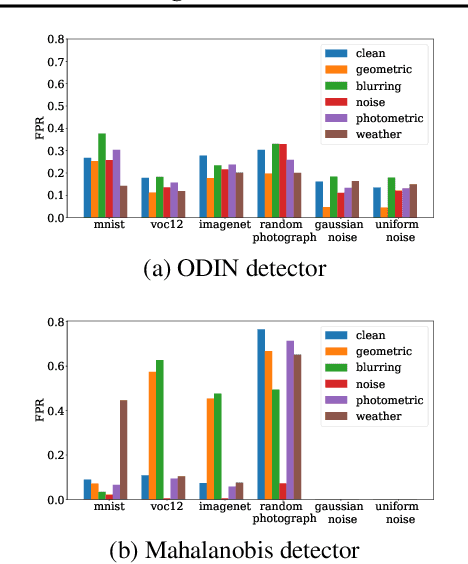
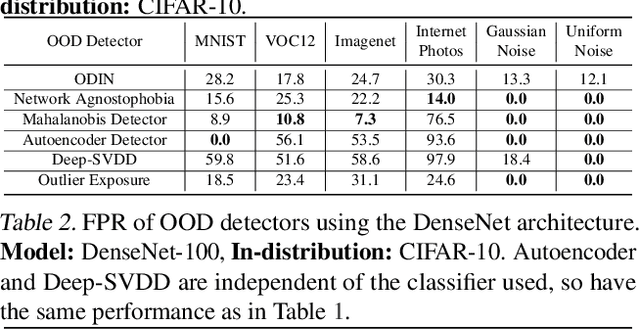
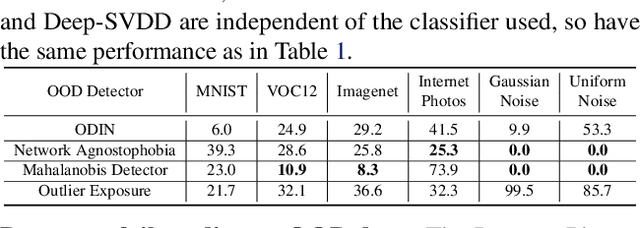
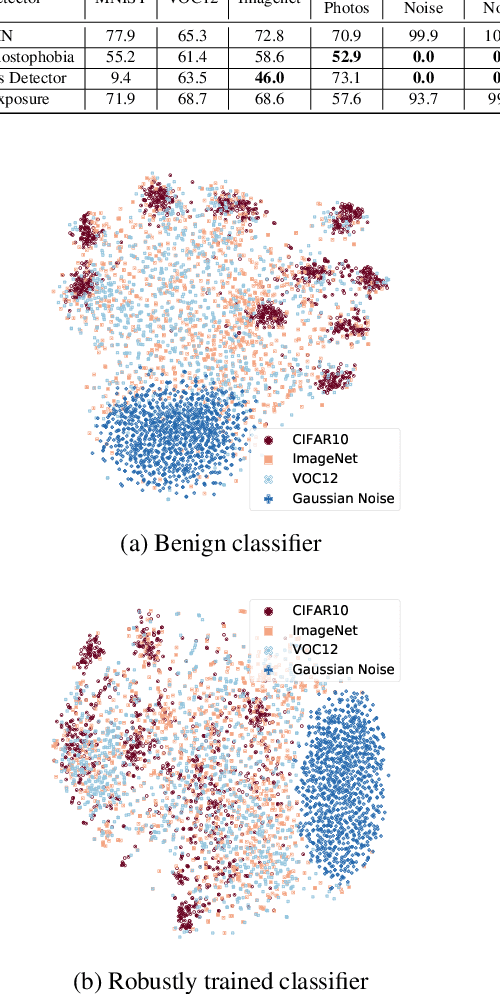
Open-world machine learning (ML) combines closed-world models trained on in-distribution data with out-of-distribution (OOD) detectors, which aim to detect and reject OOD inputs. Previous works on open-world ML systems usually fail to test their reliability under diverse, and possibly adversarial conditions. Therefore, in this paper, we seek to understand how resilient are state-of-the-art open-world ML systems to changes in system components? With our evaluation across 6 OOD detectors, we find that the choice of in-distribution data, model architecture and OOD data have a strong impact on OOD detection performance, inducing false positive rates in excess of $70\%$. We further show that OOD inputs with 22 unintentional corruptions or adversarial perturbations render open-world ML systems unusable with false positive rates of up to $100\%$. To increase the resilience of open-world ML, we combine robust classifiers with OOD detection techniques and uncover a new trade-off between OOD detection and robustness.
Universal Adversarial Attacks with Natural Triggers for Text Classification
May 01, 2020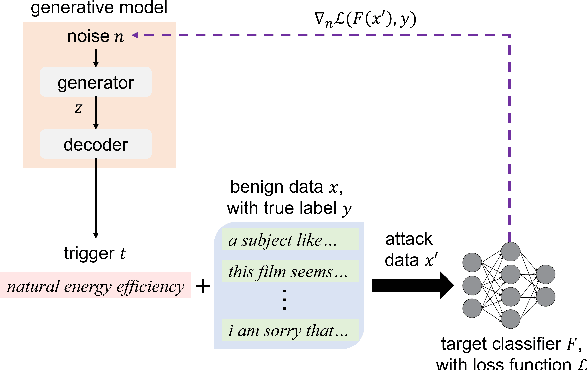
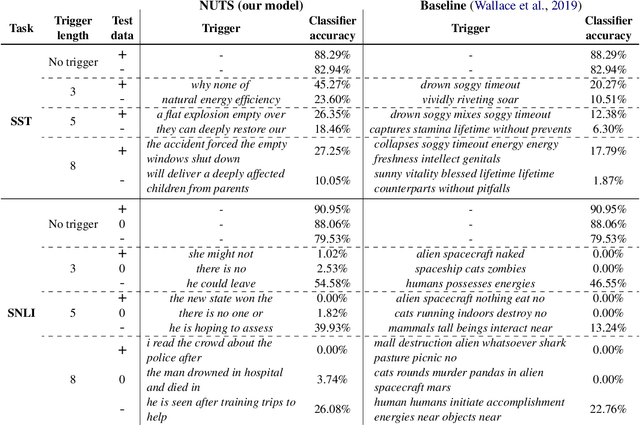


Recent work has demonstrated the vulnerability of modern text classifiers to universal adversarial attacks, which are input-agnostic sequence of words added to any input instance. Despite being highly successful, the word sequences produced in these attacks are often unnatural, do not carry much semantic meaning, and can be easily distinguished from natural text. In this paper, we develop adversarial attacks that appear closer to natural English phrases and yet confuse classification systems when added to benign inputs. To achieve this, we leverage an adversarially regularized autoencoder (ARAE) to generate triggers and propose a gradient-based search method to output natural text that fools a target classifier. Experiments on two different classification tasks demonstrate the effectiveness of our attacks while also being less identifiable than previous approaches on three simple detection metrics.
Systematic Evaluation of Privacy Risks of Machine Learning Models
Mar 24, 2020
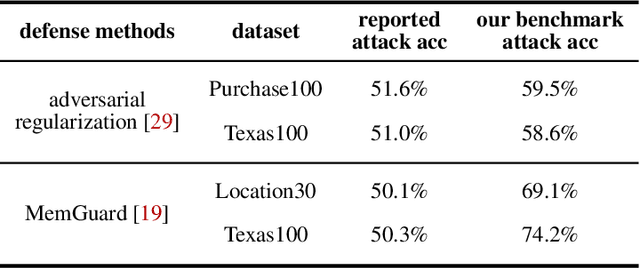
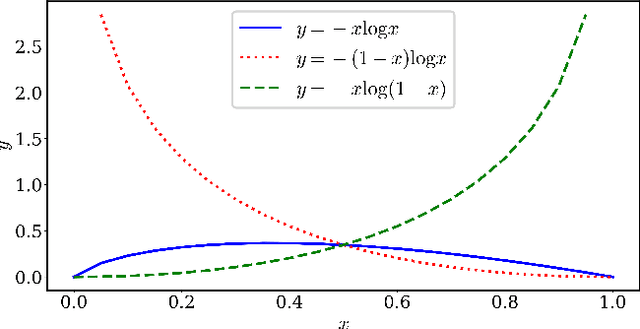
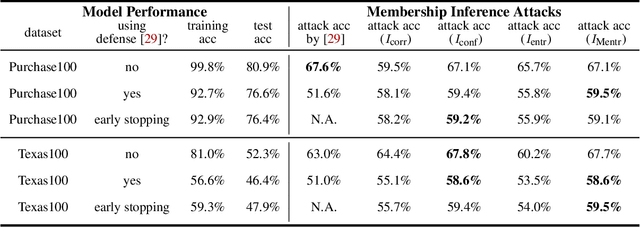
Machine learning models are prone to memorizing sensitive data, making them vulnerable to membership inference attacks in which an adversary aims to guess if an input sample was used to train the model. In this paper, we show that prior work on membership inference attacks may severely underestimate the privacy risks by relying solely on training custom neural network classifiers to perform attacks and focusing only on the aggregate results over data samples, such as the attack accuracy. To overcome these limitations, we first propose to benchmark membership inference privacy risks by improving existing non-neural network based inference attacks and proposing a new inference attack method based on a modification of prediction entropy. We also propose benchmarks for defense mechanisms by accounting for adaptive adversaries with knowledge of the defense and also accounting for the trade-off between model accuracy and privacy risks. Using our benchmark attacks, we demonstrate that existing defense approaches are not as effective as previously reported. Next, we introduce a new approach for fine-grained privacy analysis by formulating and deriving a new metric called the privacy risk score. Our privacy risk score metric measures an individual sample's likelihood of being a training member, which allows an adversary to perform membership inference attacks with high confidence. We experimentally validate the effectiveness of the privacy risk score metric and demonstrate that the distribution of the privacy risk score across individual samples is heterogeneous. Finally, we perform an in-depth investigation for understanding why certain samples have high privacy risk scores, including correlations with model sensitivity, generalization error, and feature embeddings. Our work emphasizes the importance of a systematic and rigorous evaluation of privacy risks of machine learning models.
Towards Probabilistic Verification of Machine Unlearning
Mar 09, 2020


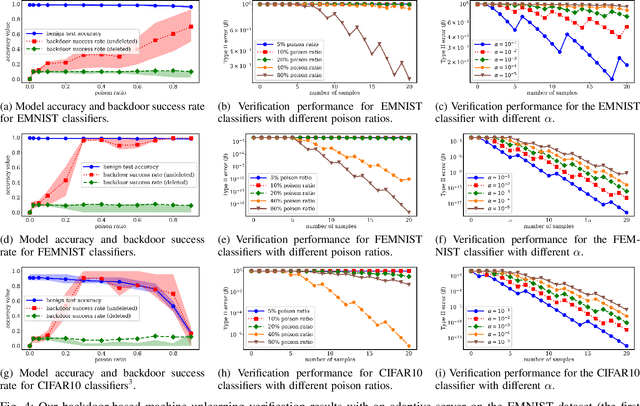
Right to be forgotten, also known as the right to erasure, is the right of individuals to have their data erased from an entity storing it. The General Data Protection Regulation in the European Union legally solidified the status of this long held notion. As a consequence, there is a growing need for the development of mechanisms whereby users can verify if service providers comply with their deletion requests. In this work, we take the first step in proposing a formal framework to study the design of such verification mechanisms for data deletion requests -- also known as machine unlearning -- in the context of systems that provide machine learning as a service. We propose a backdoor-based verification mechanism and demonstrate its effectiveness in certifying data deletion with high confidence using the above framework. Our mechanism makes a novel use of backdoor attacks in ML as a basis for quantitatively inferring machine unlearning. In our mechanism, each user poisons part of its training data by injecting a user-specific backdoor trigger associated with a user-specific target label. The prediction of target labels on test samples with the backdoor trigger is then used as an indication of the user's data being used to train the ML model. We formalize the verification process as a hypothesis testing problem, and provide theoretical guarantees on the statistical power of the hypothesis test. We experimentally demonstrate that our approach has minimal effect on the machine learning service but provides high confidence verification of unlearning. We show that with a $30\%$ poison ratio and merely $20$ test queries, our verification mechanism has both false positive and false negative ratios below $10^{-5}$. Furthermore, we also show the effectiveness of our approach by testing it against an adaptive adversary that uses a state-of-the-art backdoor defense method.
Privacy Risks of Securing Machine Learning Models against Adversarial Examples
May 27, 2019



The arms race between attacks and defenses for machine learning models has come to a forefront in recent years, in both the security community and the privacy community. However, one big limitation of previous research is that the security domain and the privacy domain have typically been considered separately. It is thus unclear whether the defense methods in one domain will have any unexpected impact on the other domain. In this paper, we take a step towards resolving this limitation by combining the two domains. In particular, we measure the success of membership inference attacks against six state-of-the-art adversarial defense methods that mitigate adversarial examples (i.e., evasion attacks). Membership inference attacks aim to infer an individual's participation in the target model's training set and are known to be correlated with target model's overfitting and sensitivity with regard to training data. Meanwhile, adversarial defense methods aim to enhance the robustness of target models by ensuring that model predictions are unchanged for a small area around each training sample. Thus, adversarial defenses typically have a more fine-grained reliance on the training set and make the target model more vulnerable to membership inference attacks. To perform the membership inference attacks, we leverage the conventional inference method based on prediction confidence and propose two new inference methods that exploit structural properties of adversarially robust defenses. Our experimental evaluation demonstrates that compared with the natural training (undefended) approach, adversarial defense methods can indeed increase the target model's risk against membership inference attacks. When applying adversarial defenses to train the robust models, the membership inference advantage increases by up to $4.5$ times compared to the naturally undefended models.
Better the Devil you Know: An Analysis of Evasion Attacks using Out-of-Distribution Adversarial Examples
May 05, 2019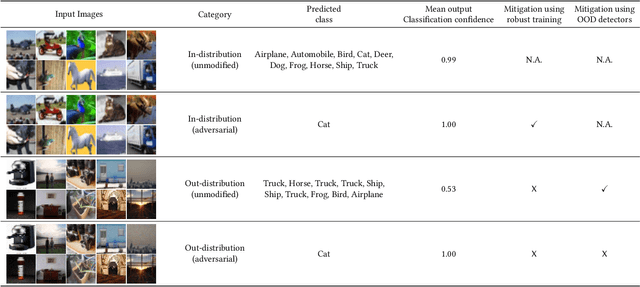
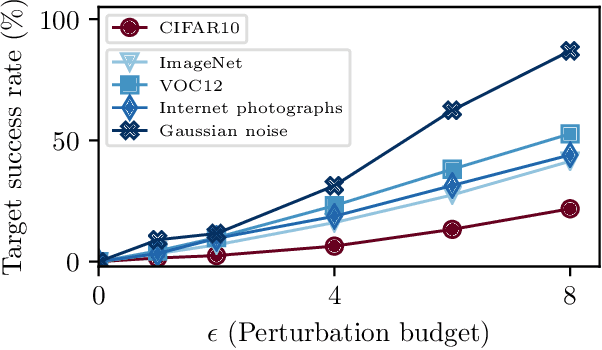
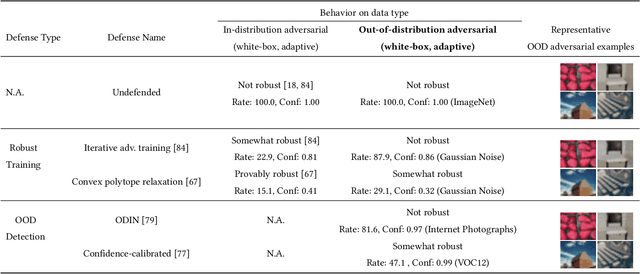
A large body of recent work has investigated the phenomenon of evasion attacks using adversarial examples for deep learning systems, where the addition of norm-bounded perturbations to the test inputs leads to incorrect output classification. Previous work has investigated this phenomenon in closed-world systems where training and test inputs follow a pre-specified distribution. However, real-world implementations of deep learning applications, such as autonomous driving and content classification are likely to operate in the open-world environment. In this paper, we demonstrate the success of open-world evasion attacks, where adversarial examples are generated from out-of-distribution inputs (OOD adversarial examples). In our study, we use 11 state-of-the-art neural network models trained on 3 image datasets of varying complexity. We first demonstrate that state-of-the-art detectors for out-of-distribution data are not robust against OOD adversarial examples. We then consider 5 known defenses for adversarial examples, including state-of-the-art robust training methods, and show that against these defenses, OOD adversarial examples can achieve up to 4$\times$ higher target success rates compared to adversarial examples generated from in-distribution data. We also take a quantitative look at how open-world evasion attacks may affect real-world systems. Finally, we present the first steps towards a robust open-world machine learning system.