 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(Fusionformer):Exploiting the Joint Motion Synergy with Fusion Network Based On Transformer for 3D Human Pose Estimation
Oct 08, 2022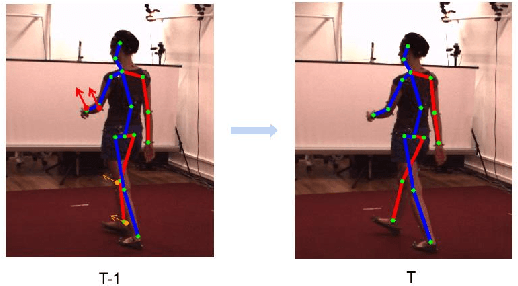
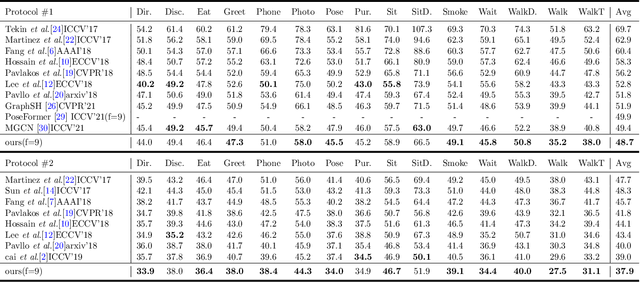


For the current 3D human pose estimation task, in order to improve the efficiency of pose sequence output, we try to further improve the prediction stability in low input video frame scenarios.Many previous methods lack the understanding of local joint information.\cite{9878888}considers the temporal relationship of a single joint in this work.However, we found that there is a certain predictive correlation between the trajectories of different joints in time.Therefore, our proposed \textbf{Fusionformer} method introduces a self-trajectory module and a cross-trajectory module based on the spatio-temporal module.After that, the global spatio-temporal features and local joint trajectory features are fused through a linear network in a parallel manner.To eliminate the influence of bad 2D poses on 3D projections, finally we also introduce a pose refinement network to balance the consistency of 3D projections.In addition, we evaluate the proposed method on two benchmark datasets (Human3.6M, MPI-INF-3DHP). Comparing our method with the baseline method poseformer, the results show an improvement of 2.4\% MPJPE and 4.3\% P-MPJPE on the Human3.6M dataset, respectively.
Fast deep learning correspondence for neuron tracking and identification in C.elegans using synthetic training
Jan 20, 2021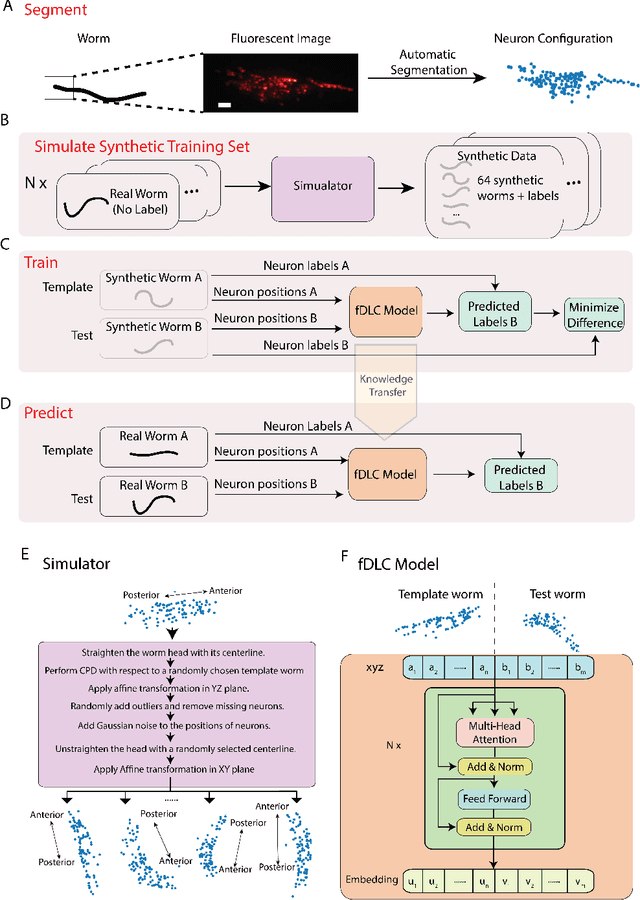
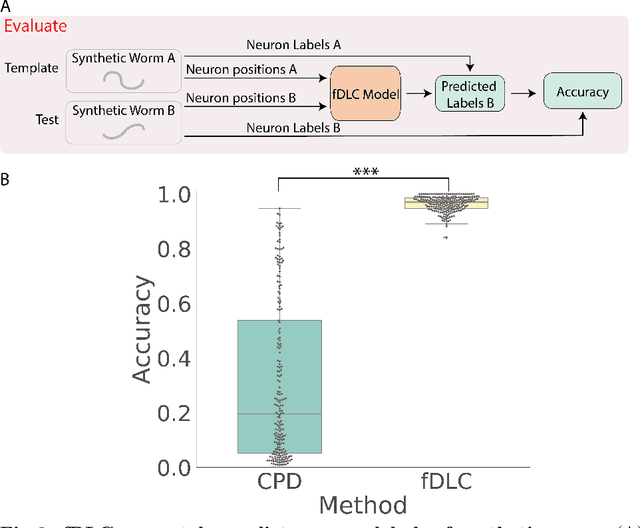
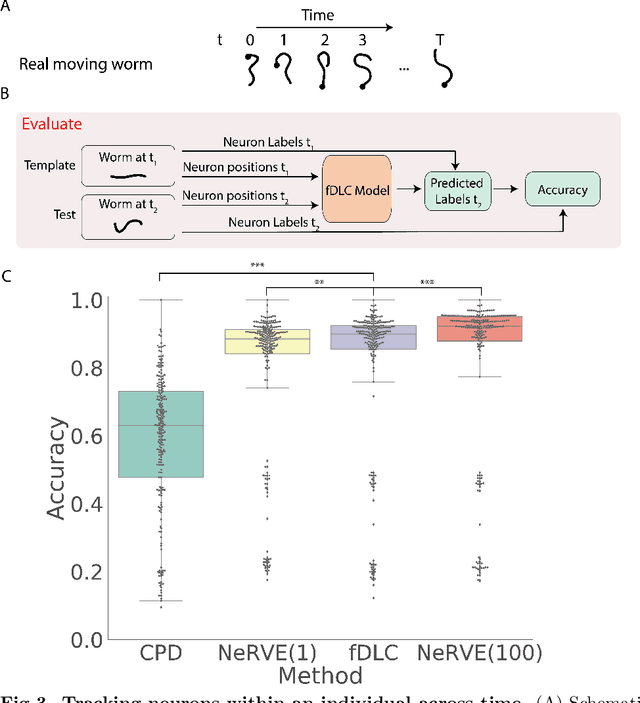
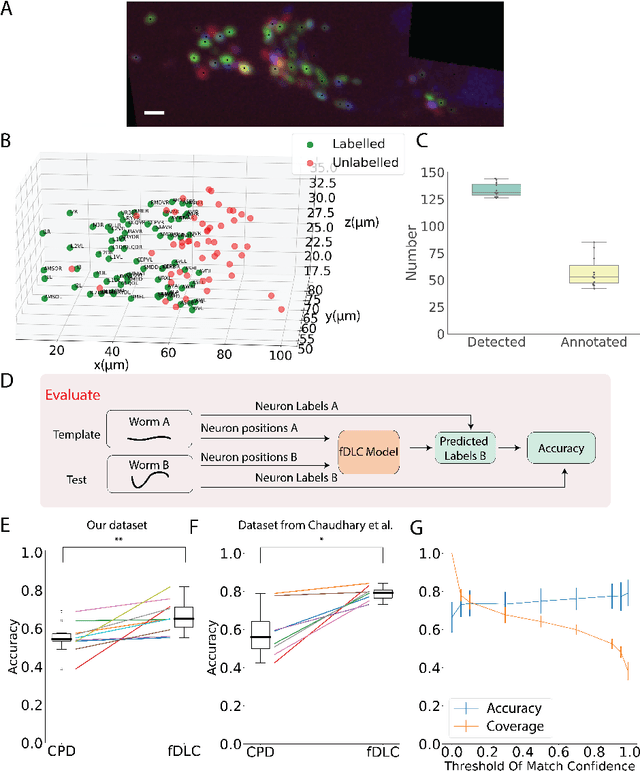
We present an automated method to track and identify neurons in C. elegans, called "fast Deep Learning Correspondence" or fDLC, based on the transformer network architecture. The model is trained once on empirically derived synthetic data and then predicts neural correspondence across held-out real animals via transfer learning. The same pre-trained model both tracks neurons across time and identifies corresponding neurons across individuals. Performance is evaluated against hand-annotated datasets, including NeuroPAL [1]. Using only position information, the method achieves 80.0% accuracy at tracking neurons within an individual and 65.8% accuracy at identifying neurons across individuals. Accuracy is even higher on a published dataset [2]. Accuracy reaches 76.5% when using color information from NeuroPAL. Unlike previous methods, fDLC does not require straightening or transforming the animal into a canonical coordinate system. The method is fast and predicts correspondence in 10 ms making it suitable for future real-time applications.
Universal Adversarial Attacks with Natural Triggers for Text Classification
May 01, 2020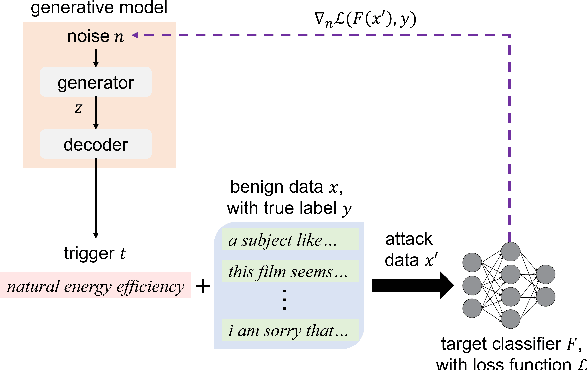
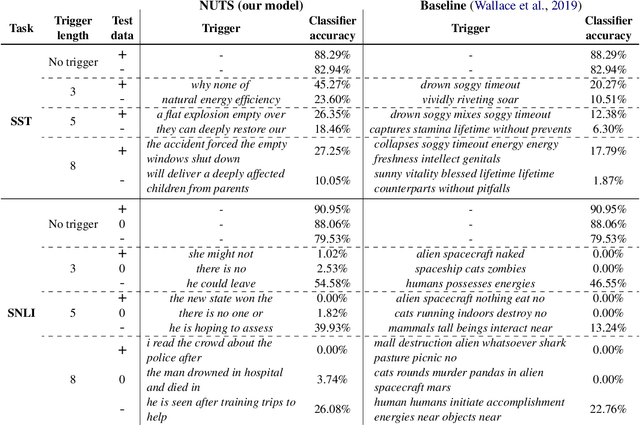


Recent work has demonstrated the vulnerability of modern text classifiers to universal adversarial attacks, which are input-agnostic sequence of words added to any input instance. Despite being highly successful, the word sequences produced in these attacks are often unnatural, do not carry much semantic meaning, and can be easily distinguished from natural text. In this paper, we develop adversarial attacks that appear closer to natural English phrases and yet confuse classification systems when added to benign inputs. To achieve this, we leverage an adversarially regularized autoencoder (ARAE) to generate triggers and propose a gradient-based search method to output natural text that fools a target classifier. Experiments on two different classification tasks demonstrate the effectiveness of our attacks while also being less identifiable than previous approaches on three simple detection metrics.