 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Personalized Evaluation of Large Language Models with An Anonymous Crowd-Sourcing Platform
Paper and Code
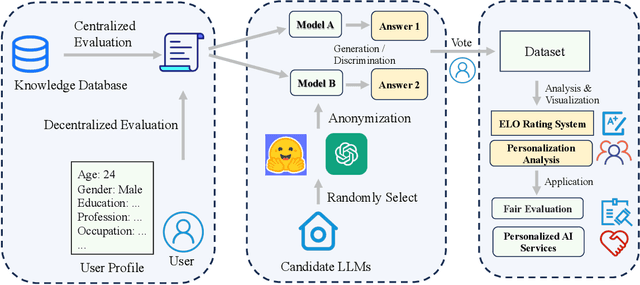
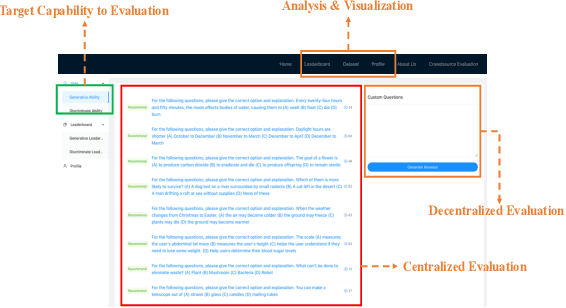
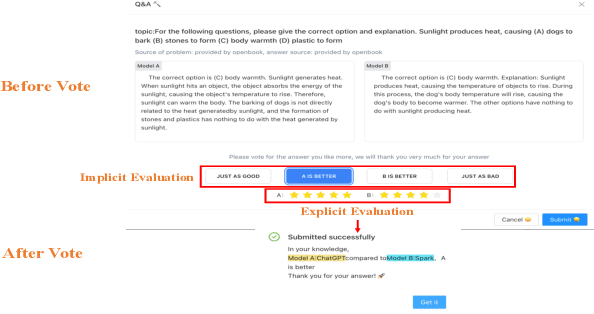
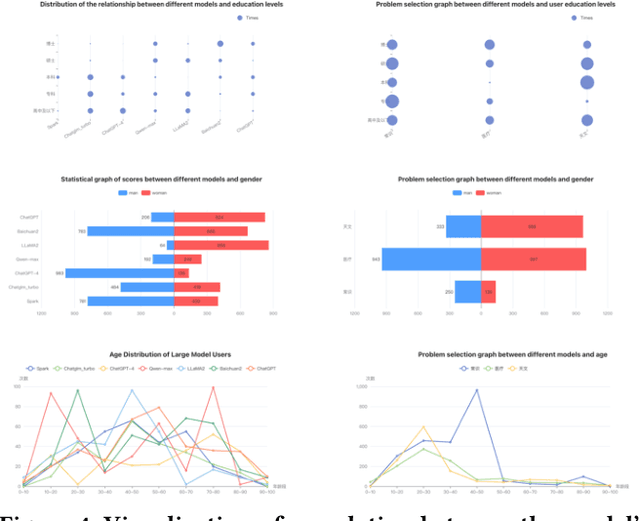
Large language model evaluation plays a pivotal role in the enhancement of its capacity. Previously, numerous methods for evaluating large language models have been proposed in this area. Despite their effectiveness, these existing works mainly focus on assessing objective questions, overlooking the capability to evaluate subjective questions which is extremely common for large language models. Additionally, these methods predominantly utilize centralized datasets for evaluation, with question banks concentrated within the evaluation platforms themselves. Moreover, the evaluation processes employed by these platforms often overlook personalized factors, neglecting to consider the individual characteristics of both the evaluators and the models being evaluated. To address these limitations, we propose a novel anonymous crowd-sourcing evaluation platform, BingJian, for large language models that employs a competitive scoring mechanism where users participate in ranking models based on their performance. This platform stands out not only for its support of centralized evaluations to assess the general capabilities of models but also for offering an open evaluation gateway. Through this gateway, users have the opportunity to submit their questions, testing the models on a personalized and potentially broader range of capabilities. Furthermore, our platform introduces personalized evaluation scenarios, leveraging various forms of human-computer interaction to assess large language models in a manner that accounts for individual user preferences and contexts. The demonstration of BingJian can be accessed at https://github.com/Mingyue-Cheng/Bingjian.