 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnseen Horizons: Unveiling the Real Capability of LLM Code Generation Beyond the Familiar
Dec 11, 2024

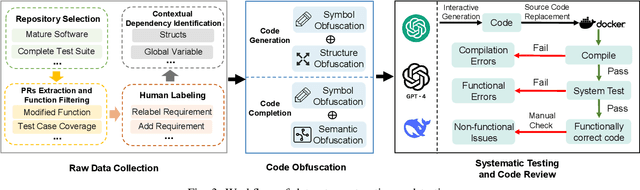
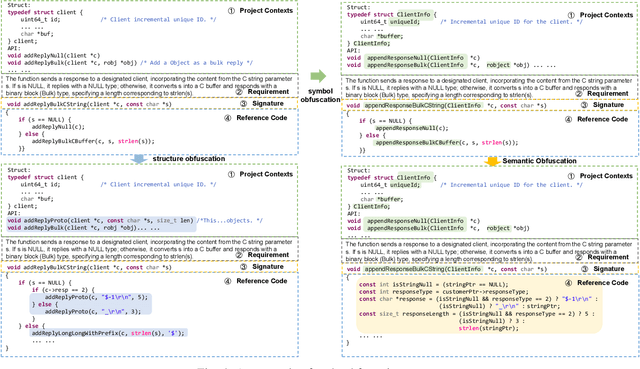
Recently, large language models (LLMs) have shown strong potential in code generation tasks. However, there are still gaps before they can be fully applied in actual software development processes. Accurately assessing the code generation capabilities of large language models has become an important basis for evaluating and improving the models. Some existing works have constructed datasets to evaluate the capabilities of these models. However, the current evaluation process may encounter the illusion of "Specialist in Familiarity", primarily due to three gaps: the exposure of target code, case timeliness, and dependency availability. The fundamental reason for these gaps is that the code in current datasets may have been extensively exposed and exercised during the training phase, and due to the continuous training and development of LLM, their timeliness has been severely compromised. The key to solve the problem is to, as much as possible, evaluate the LLMs using code that they have not encountered before. Thus, the fundamental idea in this paper is to draw on the concept of code obfuscation, changing code at different levels while ensuring the functionality and output. To this end, we build a code-obfuscation based benchmark OBFUSEVAL. We first collect 1,354 raw cases from five real-world projects, including function description and code. Then we use three-level strategy (symbol, structure and semantic) to obfuscate descriptions, code and context dependencies. We evaluate four LLMs on OBFU- SEVAL and compared the effectiveness of different obfuscation strategy. We use official test suites of these projects to evaluate the generated code. The results show that after obfuscation, the average decrease ratio of test pass rate can up to 62.5%.
Augmenting Channel Simulator and Semi- Supervised Learning for Efficient Indoor Positioning
Aug 01, 2024



This work aims to tackle the labor-intensive and resource-consuming task of indoor positioning by proposing an efficient approach. The proposed approach involves the introduction of a semi-supervised learning (SSL) with a biased teacher (SSLB) algorithm, which effectively utilizes both labeled and unlabeled channel data. To reduce measurement expenses, unlabeled data is generated using an updated channel simulator (UCHS), and then weighted by adaptive confidence values to simplify the tuning of hyperparameters. Simulation results demonstrate that the proposed strategy achieves superior performance while minimizing measurement overhead and training expense compared to existing benchmarks, offering a valuable and practical solution for indoor positioning.
DGoT: Dynamic Graph of Thoughts for Scientific Abstract Generation
Mar 26, 2024The method of training language models based on domain datasets has obtained significant achievements in the task of generating scientific paper abstracts. However, such models face problems of generalization and expensive training costs. The use of large language models (LLMs) to solve the task of generating paper abstracts saves the cost of model training. However, due to the hallucination problem of LLM, it is often necessary to improve the reliability of the results through multi-round query prompt approach such as Graph of Thoughts (GoT), which also brings additional reasoning costs. In this paper, we propose a Dynamic Graph of Thought (DGoT). It not only inherits the advantages of the existing GoT prompt approach, but also dynamically adjust the graph structure according to data characteristics while reducing model reasoning cost. Experimental results show that our method's cost-effectiveness in abstract generation tasks is only 43.7% to 56.4% of other multi-round query prompt approaches. Our code is available at https://github.com/JayceNing/DGoT.
KDSM: An uplift modeling framework based on knowledge distillation and sample matching
Mar 06, 2023



Uplift modeling aims to estimate the treatment effect on individuals, widely applied in the e-commerce platform to target persuadable customers and maximize the return of marketing activities. Among the existing uplift modeling methods, tree-based methods are adept at fitting increment and generalization, while neural-network-based models excel at predicting absolute value and precision, and these advantages have not been fully explored and combined. Also, the lack of counterfactual sample pairs is the root challenge in uplift modeling. In this paper, we proposed an uplift modeling framework based on Knowledge Distillation and Sample Matching (KDSM). The teacher model is the uplift decision tree (UpliftDT), whose structure is exploited to construct counterfactual sample pairs, and the pairwise incremental prediction is treated as another objective for the student model. Under the idea of multitask learning, the student model can achieve better performance on generalization and even surpass the teacher. Extensive offline experiments validate the universality of different combinations of teachers and student models and the superiority of KDSM measured against the baselines. In online A/B testing, the cost of each incremental room night is reduced by 6.5\%.
Zero3D: Semantic-Driven Multi-Category 3D Shape Generation
Feb 13, 2023Semantic-driven 3D shape generation aims to generate 3D objects conditioned on text. Previous works face problems with single-category generation, low-frequency 3D details, and requiring a large number of paired datasets for training. To tackle these challenges, we propose a multi-category conditional diffusion model. Specifically, 1) to alleviate the problem of lack of large-scale paired data, we bridge the text, 2D image and 3D shape based on the pre-trained CLIP model, and 2) to obtain the multi-category 3D shape feature, we apply the conditional flow model to generate 3D shape vector conditioned on CLIP embedding. 3) to generate multi-category 3D shape, we employ the hidden-layer diffusion model conditioned on the multi-category shape vector, which greatly reduces the training time and memory consumption.
Rapid grasping of fabric using bionic soft grippers with elastic instability
Jan 26, 2023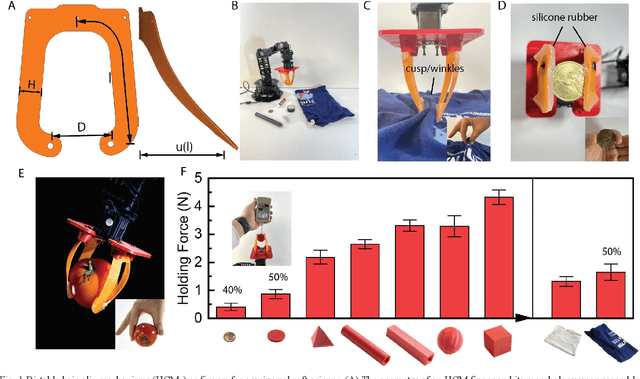
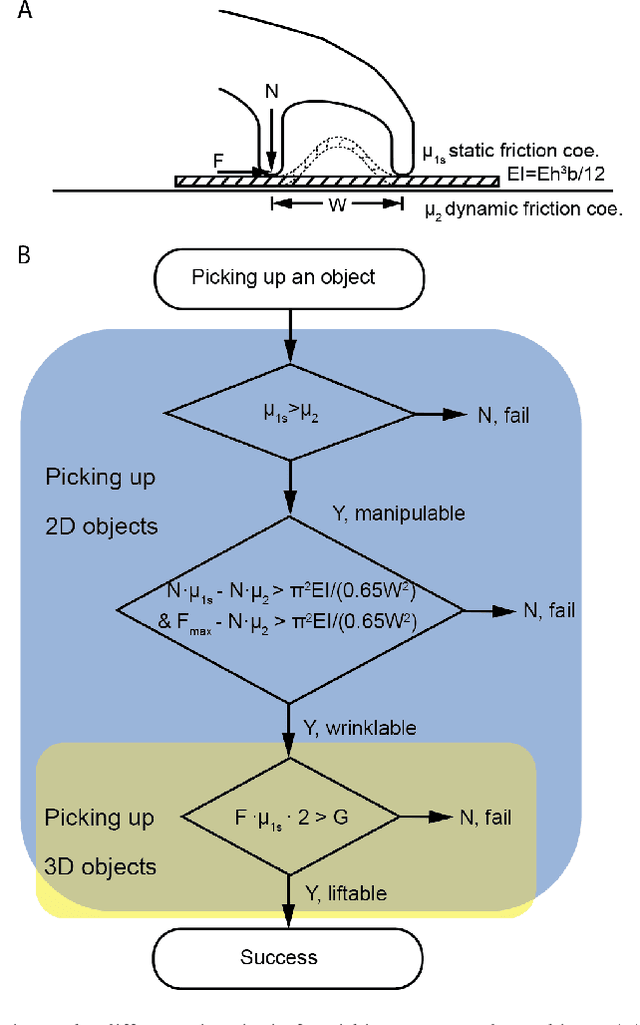
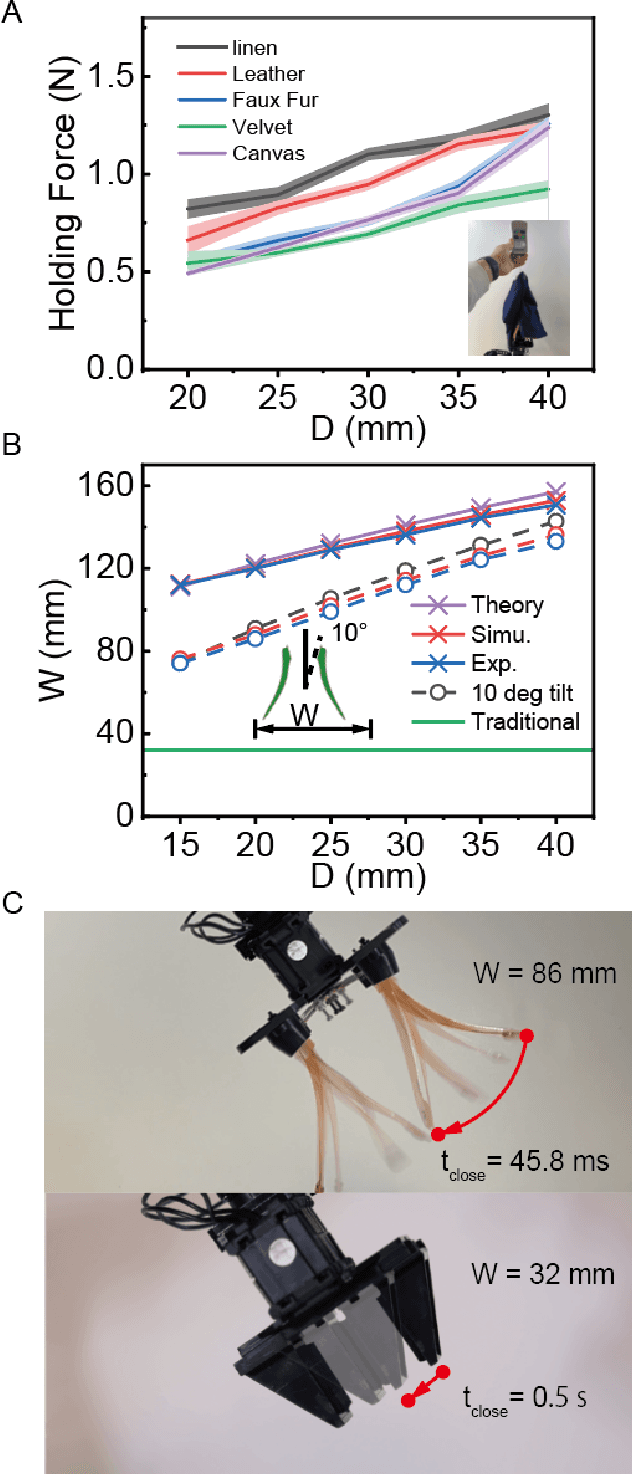
Robot grasping is subject to an inherent tradeoff: Grippers with a large span typically take a longer time to close, and fast grippers usually cover a small span. However, many practical applications of soft grippers require the ability to close a large distance rapidly. For example, grasping cloth typically requires pressing a wide span of fabric into a graspable cusp. Here, we demonstrate a human-finger-inspired snapping gripper that exploits elastic instability to achieve reversible rapid closure over a wide span. Using prestressed semi-rigid material as the skeleton, the gripper fingers can widely open (86 ~) and rapidly close (46 ms) following a trajectory similar to that of a thumb-index finger pinching which is 2.7 times and 10.9 times better than the reference gripper in terms of span and speed, respectively. We theoretically give the design principle, simulatively verify the method, and experimentally test this gripper on a variety of rigid, flexible, and limp objects and achieve good adaptivity and mechanical performance. This research helps bridge the gap between strong industry manipulators and safe human-interactive robotic hands.
A Lightweight Dual-Domain Attention Framework for Sparse-View CT Reconstruction
Feb 19, 2022



Computed Tomography (CT) plays an essential role in clinical diagnosis. Due to the adverse effects of radiation on patients, the radiation dose is expected to be reduced as low as possible. Sparse sampling is an effective way, but it will lead to severe artifacts on the reconstructed CT image, thus sparse-view CT image reconstruction has been a prevailing and challenging research area. With the popularity of mobile devices, the requirements for lightweight and real-time networks are increasing rapidly. In this paper, we design a novel lightweight network called CAGAN, and propose a dual-domain reconstruction pipeline for parallel beam sparse-view CT. CAGAN is an adversarial auto-encoder, combining the Coordinate Attention unit, which preserves the spatial information of features. Also, the application of Shuffle Blocks reduces the parameters by a quarter without sacrificing its performance. In the Radon domain, the CAGAN learns the mapping between the interpolated data and fringe-free projection data. After the restored Radon data is reconstructed to an image, the image is sent into the second CAGAN trained for recovering the details, so that a high-quality image is obtained. Experiments indicate that the CAGAN strikes an excellent balance between model complexity and performance, and our pipeline outperforms the DD-Net and the DuDoNet.
A Lightweight Structure Aimed to Utilize Spatial Correlation for Sparse-View CT Reconstruction
Jan 19, 2021
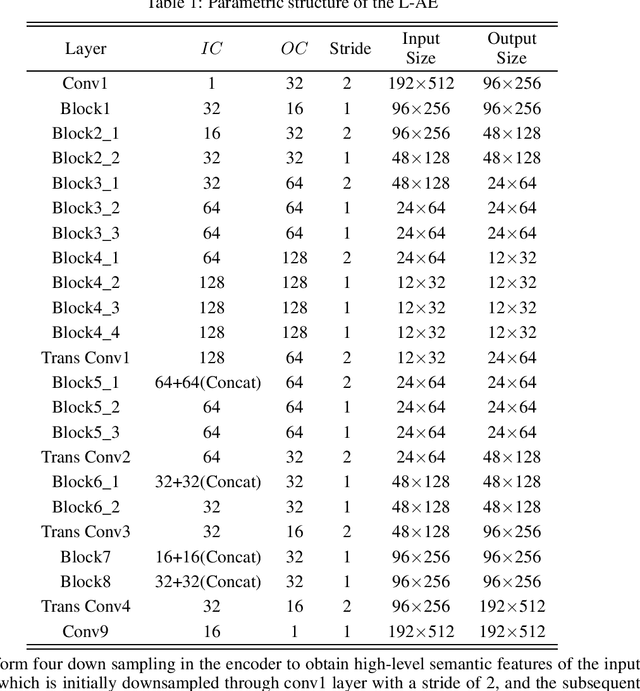
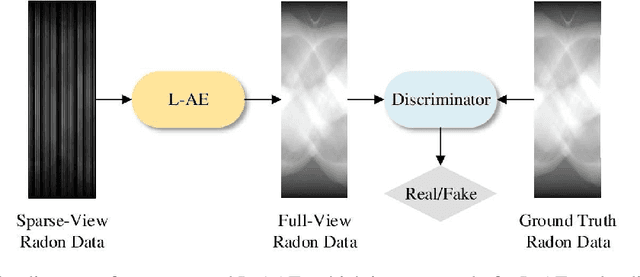
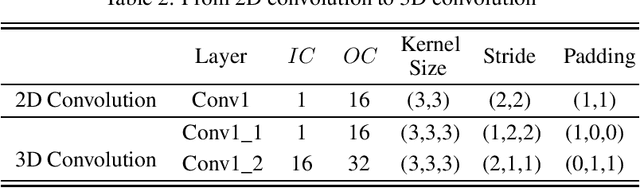
Sparse-view computed tomography (CT) is known as a widely used approach to reduce radiation dose while accelerating imaging through lowered projection views and correlated calculations. However, its severe imaging noise and streaking artifacts turn out to be a major issue in the low dose protocol. In this paper, we propose a dual-domain deep learning-based method that breaks through the limitations of currently prevailing algorithms that merely process single image slices. Since the scanned object usually contains a high degree of spatial continuity, the obtained consecutive imaging slices embody rich information that is largely unexplored. Therefore, we establish a cascade model named LS-AAE which aims to tackle the above problem. In addition, in order to adapt to the social trend of lightweight medical care, our model adopts the inverted residual with linear bottleneck in the module design to make it mobile and lightweight (reduce model parameters to one-eighth of its original) without sacrificing its performance. In our experiments, sparse sampling is conducted at intervals of 4{\deg}, 8{\deg} and 16{\deg}, which appears to be a challenging sparsity that few scholars have attempted before. Nevertheless, our method still exhibits its robustness and achieves the state-of-the-art performance by reaching the PSNR of 40.305 and the SSIM of 0.948, while ensuring high model mobility. Particularly, it still exceeds other current methods when the sampling rate is one-fourth of them, thereby demonstrating its remarkable superiority.
Real-Time Limited-View CT Inpainting and Reconstruction with Dual Domain Based on Spatial Information
Jan 19, 2021


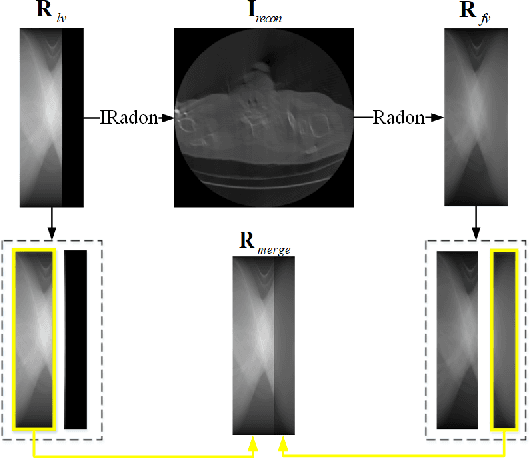
Low-dose Computed Tomography is a common issue in reality. Current reduction, sparse sampling and limited-view scanning can all cause it. Between them, limited-view CT is general in the industry due to inevitable mechanical and physical limitation. However, limited-view CT can cause serious imaging problem on account of its massive information loss. Thus, we should effectively utilize the scant prior information to perform completion. It is an undeniable fact that CT imaging slices are extremely dense, which leads to high continuity between successive images. We realized that fully exploit the spatial correlation between consecutive frames can significantly improve restoration results in video inpainting. Inspired by this, we propose a deep learning-based three-stage algorithm that hoist limited-view CT imaging quality based on spatial information. In stage one, to better utilize prior information in the Radon domain, we design an adversarial autoencoder to complement the Radon data. In the second stage, a model is built to perform inpainting based on spatial continuity in the image domain. At this point, we have roughly restored the imaging, while its texture still needs to be finely repaired. Hence, we propose a model to accurately restore the image in stage three, and finally achieve an ideal inpainting result. In addition, we adopt FBP instead of SART-TV to make our algorithm more suitable for real-time use. In the experiment, we restore and reconstruct the Radon data that has been cut the rear one-third part, they achieve PSNR of 40.209, SSIM of 0.943, while precisely present the texture.