 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Slot Attention for Efficient Linear-Time Sequence Modeling
Sep 11, 2024



Linear attention Transformers and their gated variants, celebrated for enabling parallel training and efficient recurrent inference, still fall short in recall-intensive tasks compared to traditional Transformers and demand significant resources for training from scratch. This paper introduces Gated Slot Attention (GSA), which enhances Attention with Bounded-memory-Control (ABC) by incorporating a gating mechanism inspired by Gated Linear Attention (GLA). Essentially, GSA comprises a two-layer GLA linked via softmax, utilizing context-aware memory reading and adaptive forgetting to improve memory capacity while maintaining compact recurrent state size. This design greatly enhances both training and inference efficiency through GLA's hardware-efficient training algorithm and reduced state size. Additionally, retaining the softmax operation is particularly beneficial in "finetuning pretrained Transformers to RNNs" (T2R) settings, reducing the need for extensive training from scratch. Extensive experiments confirm GSA's superior performance in scenarios requiring in-context recall and in T2R settings.
Scalable MatMul-free Language Modeling
Jun 04, 2024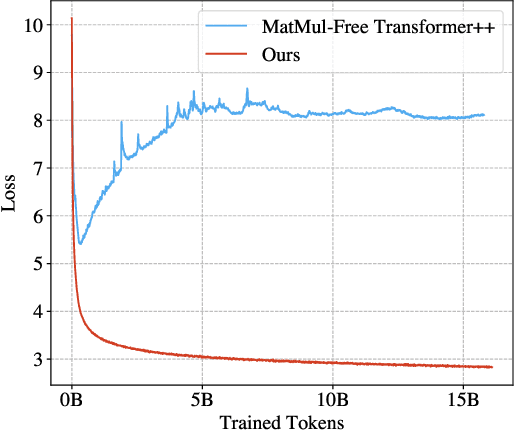
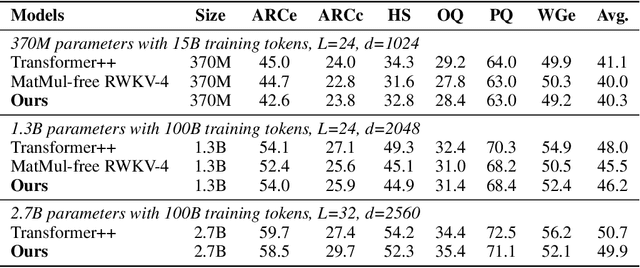
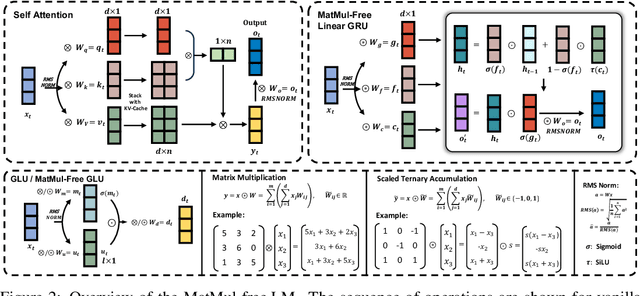
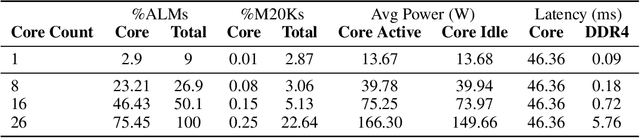
Matrix multiplication (MatMul) typically dominates the overall computational cost of large language models (LLMs). This cost only grows as LLMs scale to larger embedding dimensions and context lengths. In this work, we show that MatMul operations can be completely eliminated from LLMs while maintaining strong performance at billion-parameter scales. Our experiments show that our proposed MatMul-free models achieve performance on-par with state-of-the-art Transformers that require far more memory during inference at a scale up to at least 2.7B parameters. We investigate the scaling laws and find that the performance gap between our MatMul-free models and full precision Transformers narrows as the model size increases. We also provide a GPU-efficient implementation of this model which reduces memory usage by up to 61% over an unoptimized baseline during training. By utilizing an optimized kernel during inference, our model's memory consumption can be reduced by more than 10x compared to unoptimized models. To properly quantify the efficiency of our architecture, we build a custom hardware solution on an FPGA which exploits lightweight operations beyond what GPUs are capable of. We processed billion-parameter scale models at 13W beyond human readable throughput, moving LLMs closer to brain-like efficiency. This work not only shows how far LLMs can be stripped back while still performing effectively, but also points at the types of operations future accelerators should be optimized for in processing the next generation of lightweight LLMs. Our code implementation is available at \url{https://github.com/ridgerchu/matmulfreellm}.