 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
Nov 18, 2025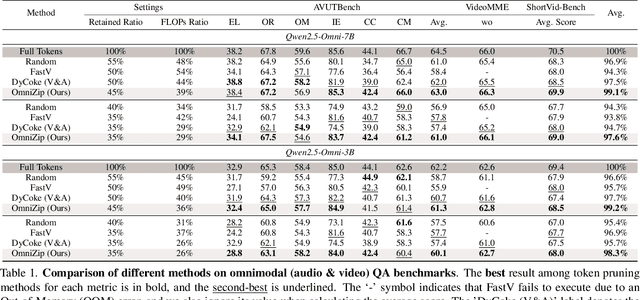
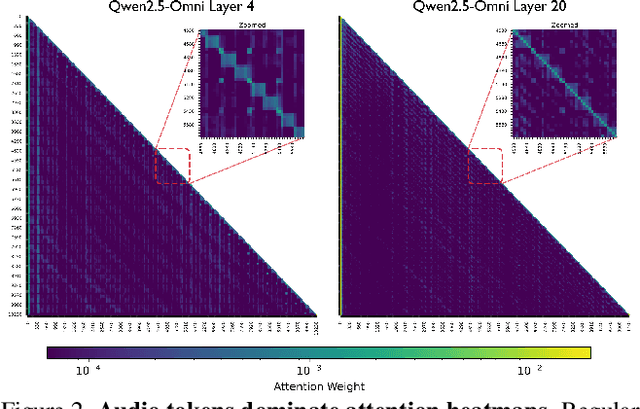
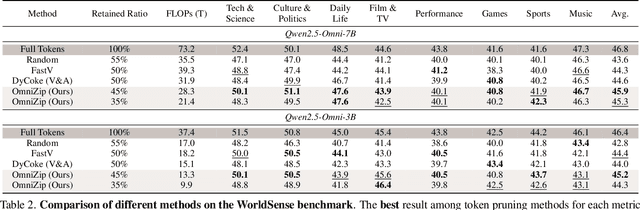
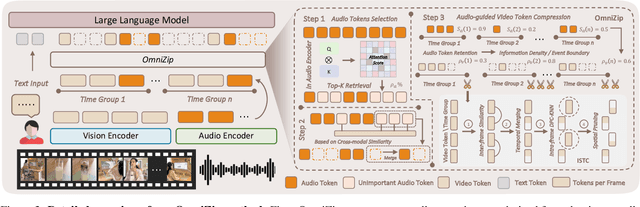
Omnimodal large language models (OmniLLMs) have attracted increasing research attention of late towards unified audio-video understanding, wherein processing audio-video token sequences creates a significant computational bottleneck, however. Existing token compression methods have yet to accommodate this emerging need of jointly compressing multimodal tokens. To bridge this gap, we present OmniZip, a training-free, audio-guided audio-visual token-compression framework that optimizes multimodal token representation and accelerates inference. Specifically, OmniZip first identifies salient audio tokens, then computes an audio retention score for each time group to capture information density, thereby dynamically guiding video token pruning and preserving cues from audio anchors enhanced by cross-modal similarity. For each time window, OmniZip compresses the video tokens using an interleaved spatio-temporal scheme. Extensive empirical results demonstrate the merits of OmniZip - it achieves 3.42X inference speedup and 1.4X memory reduction over other top-performing counterparts, while maintaining performance with no training.
OrderChain: A General Prompting Paradigm to Improve Ordinal Understanding Ability of MLLM
Apr 07, 2025Despite the remarkable progress of multimodal large language models (MLLMs), they continue to face challenges in achieving competitive performance on ordinal regression (OR; a.k.a. ordinal classification). To address this issue, this paper presents OrderChain, a novel and general prompting paradigm that improves the ordinal understanding ability of MLLMs by specificity and commonality modeling. Specifically, our OrderChain consists of a set of task-aware prompts to facilitate the specificity modeling of diverse OR tasks and a new range optimization Chain-of-Thought (RO-CoT), which learns a commonality way of thinking about OR tasks by uniformly decomposing them into multiple small-range optimization subtasks. Further, we propose a category recursive division (CRD) method to generate instruction candidate category prompts to support RO-CoT automatic optimization. Comprehensive experiments show that a Large Language and Vision Assistant (LLaVA) model with our OrderChain improves baseline LLaVA significantly on diverse OR datasets, e.g., from 47.5% to 93.2% accuracy on the Adience dataset for age estimation, and from 30.0% to 85.7% accuracy on the Diabetic Retinopathy dataset. Notably, LLaVA with our OrderChain also remarkably outperforms state-of-the-art methods by 27% on accuracy and 0.24 on MAE on the Adience dataset. To our best knowledge, our OrderChain is the first work that augments MLLMs for OR tasks, and the effectiveness is witnessed across a spectrum of OR datasets.
Text as Image: Learning Transferable Adapter for Multi-Label Classification
Dec 07, 2023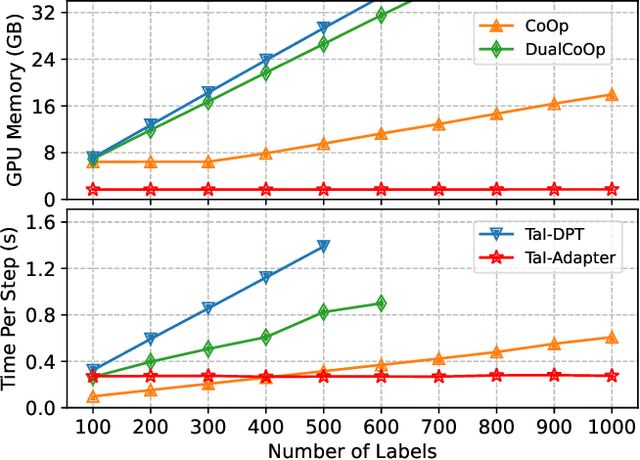



Pre-trained vision-language models have notably accelerated progress of open-world concept recognition. Their impressive zero-shot ability has recently been transferred to multi-label image classification via prompt tuning, enabling to discover novel labels in an open-vocabulary manner. However, this paradigm suffers from non-trivial training costs, and becomes computationally prohibitive for a large number of candidate labels. To address this issue, we note that vision-language pre-training aligns images and texts in a unified embedding space, making it potential for an adapter network to identify labels in visual modality while be trained in text modality. To enhance such cross-modal transfer ability, a simple yet effective method termed random perturbation is proposed, which enables the adapter to search for potential visual embeddings by perturbing text embeddings with noise during training, resulting in better performance in visual modality. Furthermore, we introduce an effective approach to employ large language models for multi-label instruction-following text generation. In this way, a fully automated pipeline for visual label recognition is developed without relying on any manual data. Extensive experiments on public benchmarks show the superiority of our method in various multi-label classification tasks.