 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangMap: A Hierarchical Benchmark for Open-Vocabulary Goal Navigation
Feb 02, 2026The relationships between objects and language are fundamental to meaningful communication between humans and AI, and to practically useful embodied intelligence. We introduce HieraNav, a multi-granularity, open-vocabulary goal navigation task where agents interpret natural language instructions to reach targets at four semantic levels: scene, room, region, and instance. To this end, we present Language as a Map (LangMap), a large-scale benchmark built on real-world 3D indoor scans with comprehensive human-verified annotations and tasks spanning these levels. LangMap provides region labels, discriminative region descriptions, discriminative instance descriptions covering 414 object categories, and over 18K navigation tasks. Each target features both concise and detailed descriptions, enabling evaluation across different instruction styles. LangMap achieves superior annotation quality, outperforming GOAT-Bench by 23.8% in discriminative accuracy using four times fewer words. Comprehensive evaluations of zero-shot and supervised models on LangMap reveal that richer context and memory improve success, while long-tailed, small, context-dependent, and distant goals, as well as multi-goal completion, remain challenging. HieraNav and LangMap establish a rigorous testbed for advancing language-driven embodied navigation. Project: https://bo-miao.github.io/LangMap
Context-Enhanced Video Moment Retrieval with Large Language Models
May 21, 2024Current methods for Video Moment Retrieval (VMR) struggle to align complex situations involving specific environmental details, character descriptions, and action narratives. To tackle this issue, we propose a Large Language Model-guided Moment Retrieval (LMR) approach that employs the extensive knowledge of Large Language Models (LLMs) to improve video context representation as well as cross-modal alignment, facilitating accurate localization of target moments. Specifically, LMR introduces a context enhancement technique with LLMs to generate crucial target-related context semantics. These semantics are integrated with visual features for producing discriminative video representations. Finally, a language-conditioned transformer is designed to decode free-form language queries, on the fly, using aligned video representations for moment retrieval. Extensive experiments demonstrate that LMR achieves state-of-the-art results, outperforming the nearest competitor by up to 3.28\% and 4.06\% on the challenging QVHighlights and Charades-STA benchmarks, respectively. More importantly, the performance gains are significantly higher for localization of complex queries.
Query-Based Knowledge Sharing for Open-Vocabulary Multi-Label Classification
Jan 02, 2024Identifying labels that did not appear during training, known as multi-label zero-shot learning, is a non-trivial task in computer vision. To this end, recent studies have attempted to explore the multi-modal knowledge of vision-language pre-training (VLP) models by knowledge distillation, allowing to recognize unseen labels in an open-vocabulary manner. However, experimental evidence shows that knowledge distillation is suboptimal and provides limited performance gain in unseen label prediction. In this paper, a novel query-based knowledge sharing paradigm is proposed to explore the multi-modal knowledge from the pretrained VLP model for open-vocabulary multi-label classification. Specifically, a set of learnable label-agnostic query tokens is trained to extract critical vision knowledge from the input image, and further shared across all labels, allowing them to select tokens of interest as visual clues for recognition. Besides, we propose an effective prompt pool for robust label embedding, and reformulate the standard ranking learning into a form of classification to allow the magnitude of feature vectors for matching, which both significantly benefit label recognition. Experimental results show that our framework significantly outperforms state-of-the-art methods on zero-shot task by 5.9% and 4.5% in mAP on the NUS-WIDE and Open Images, respectively.
Text as Image: Learning Transferable Adapter for Multi-Label Classification
Dec 07, 2023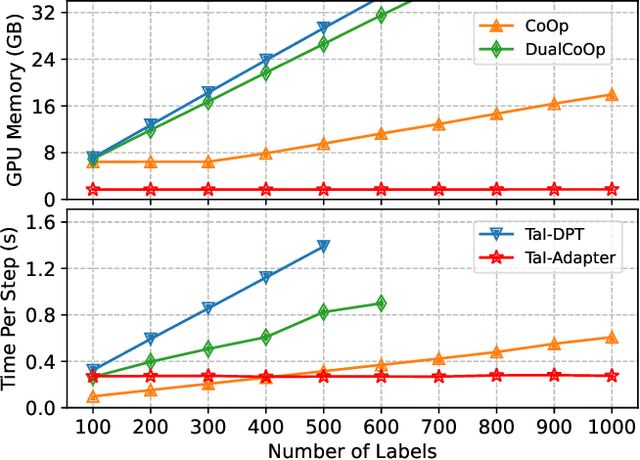



Pre-trained vision-language models have notably accelerated progress of open-world concept recognition. Their impressive zero-shot ability has recently been transferred to multi-label image classification via prompt tuning, enabling to discover novel labels in an open-vocabulary manner. However, this paradigm suffers from non-trivial training costs, and becomes computationally prohibitive for a large number of candidate labels. To address this issue, we note that vision-language pre-training aligns images and texts in a unified embedding space, making it potential for an adapter network to identify labels in visual modality while be trained in text modality. To enhance such cross-modal transfer ability, a simple yet effective method termed random perturbation is proposed, which enables the adapter to search for potential visual embeddings by perturbing text embeddings with noise during training, resulting in better performance in visual modality. Furthermore, we introduce an effective approach to employ large language models for multi-label instruction-following text generation. In this way, a fully automated pipeline for visual label recognition is developed without relying on any manual data. Extensive experiments on public benchmarks show the superiority of our method in various multi-label classification tasks.
Beyond Visual Cues: Synchronously Exploring Target-Centric Semantics for Vision-Language Tracking
Nov 28, 2023
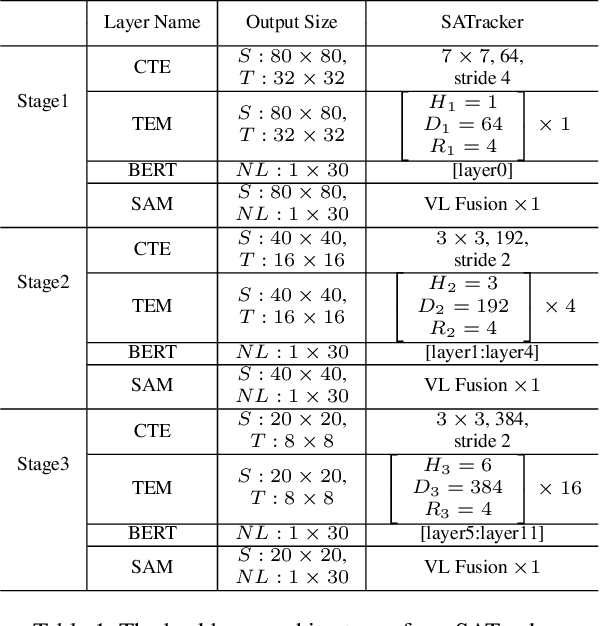


Single object tracking aims to locate one specific target in video sequences, given its initial state. Classical trackers rely solely on visual cues, restricting their ability to handle challenges such as appearance variations, ambiguity, and distractions. Hence, Vision-Language (VL) tracking has emerged as a promising approach, incorporating language descriptions to directly provide high-level semantics and enhance tracking performance. However, current VL trackers have not fully exploited the power of VL learning, as they suffer from limitations such as heavily relying on off-the-shelf backbones for feature extraction, ineffective VL fusion designs, and the absence of VL-related loss functions. Consequently, we present a novel tracker that progressively explores target-centric semantics for VL tracking. Specifically, we propose the first Synchronous Learning Backbone (SLB) for VL tracking, which consists of two novel modules: the Target Enhance Module (TEM) and the Semantic Aware Module (SAM). These modules enable the tracker to perceive target-related semantics and comprehend the context of both visual and textual modalities at the same pace, facilitating VL feature extraction and fusion at different semantic levels. Moreover, we devise the dense matching loss to further strengthen multi-modal representation learning. Extensive experiments on VL tracking datasets demonstrate the superiority and effectiveness of our methods.