 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtGS:3D Gaussian Splatting for Interactive Visual-Physical Modeling and Manipulation of Articulated Objects
Jul 03, 2025Articulated object manipulation remains a critical challenge in robotics due to the complex kinematic constraints and the limited physical reasoning of existing methods. In this work, we introduce ArtGS, a novel framework that extends 3D Gaussian Splatting (3DGS) by integrating visual-physical modeling for articulated object understanding and interaction. ArtGS begins with multi-view RGB-D reconstruction, followed by reasoning with a vision-language model (VLM) to extract semantic and structural information, particularly the articulated bones. Through dynamic, differentiable 3DGS-based rendering, ArtGS optimizes the parameters of the articulated bones, ensuring physically consistent motion constraints and enhancing the manipulation policy. By leveraging dynamic Gaussian splatting, cross-embodiment adaptability, and closed-loop optimization, ArtGS establishes a new framework for efficient, scalable, and generalizable articulated object modeling and manipulation. Experiments conducted in both simulation and real-world environments demonstrate that ArtGS significantly outperforms previous methods in joint estimation accuracy and manipulation success rates across a variety of articulated objects. Additional images and videos are available on the project website: https://sites.google.com/view/artgs/home
KETA: Kinematic-Phrases-Enhanced Text-to-Motion Generation via Fine-grained Alignment
Jan 25, 2025



Motion synthesis plays a vital role in various fields of artificial intelligence. Among the various conditions of motion generation, text can describe motion details elaborately and is easy to acquire, making text-to-motion(T2M) generation important. State-of-the-art T2M techniques mainly leverage diffusion models to generate motions with text prompts as guidance, tackling the many-to-many nature of T2M tasks. However, existing T2M approaches face challenges, given the gap between the natural language domain and the physical domain, making it difficult to generate motions fully consistent with the texts. We leverage kinematic phrases(KP), an intermediate representation that bridges these two modalities, to solve this. Our proposed method, KETA, decomposes the given text into several decomposed texts via a language model. It trains an aligner to align decomposed texts with the KP segments extracted from the generated motions. Thus, it's possible to restrict the behaviors for diffusion-based T2M models. During the training stage, we deploy the text-KP alignment loss as an auxiliary goal to supervise the models. During the inference stage, we refine our generated motions for multiple rounds in our decoder structure, where we compute the text-KP distance as the guidance signal in each new round. Experiments demonstrate that KETA achieves up to 1.19x, 2.34x better R precision and FID value on both backbones of the base model, motion diffusion model. Compared to a wide range of T2M generation models. KETA achieves either the best or the second-best performance.
Stars Are All You Need: A Distantly Supervised Pyramid Network for Document-Level End-to-End Sentiment Analysis
May 02, 2023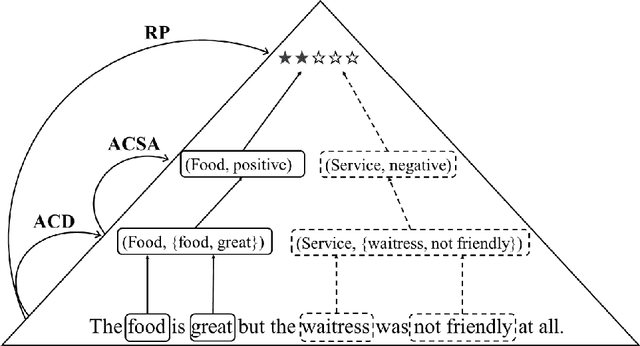
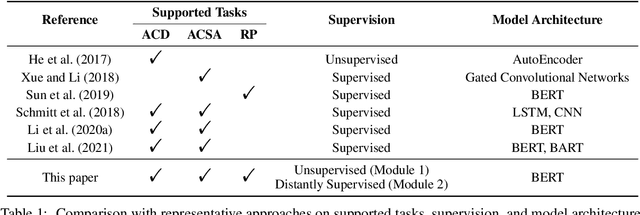

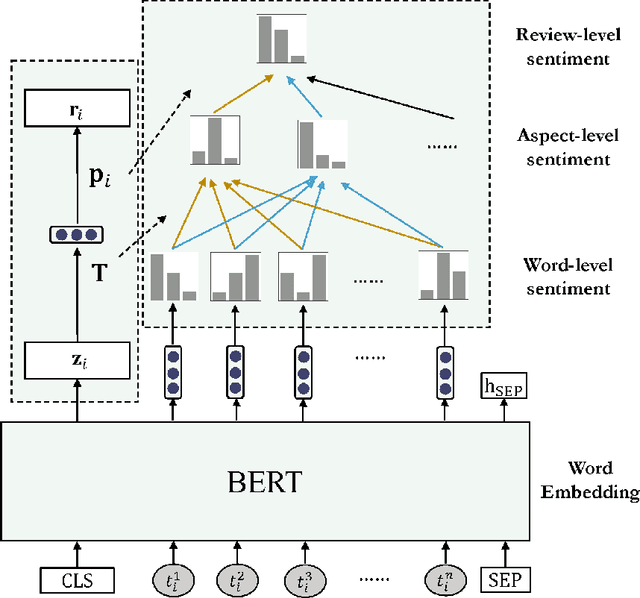
In this paper, we propose document-level end-to-end sentiment analysis to efficiently understand aspect and review sentiment expressed in online reviews in a unified manner. In particular, we assume that star rating labels are a "coarse-grained synthesis" of aspect ratings across in the review. We propose a Distantly Supervised Pyramid Network (DSPN) to efficiently perform Aspect-Category Detection, Aspect-Category Sentiment Analysis, and Rating Prediction using only document star rating labels for training. By performing these three related sentiment subtasks in an end-to-end manner, DSPN can extract aspects mentioned in the review, identify the corresponding sentiments, and predict the star rating labels. We evaluate DSPN on multi-aspect review datasets in English and Chinese and find that with only star rating labels for supervision, DSPN can perform comparably well to a variety of benchmark models. We also demonstrate the interpretability of DSPN's outputs on reviews to show the pyramid structure inherent in document level end-to-end sentiment analysis.