 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Representation Dynamics: An Empirical Investigation Across Embedders and Base LLMs
May 12, 2026Hidden states change substantially across the layers of modern language models, but most layer-wise analyses focus on one aspect of that change. We propose Layer-wise Representation Dynamics (LRD), a framework with three layer-wise measurement families: Frenet (Grassmann speed and curvature) for global subspace motion, Neighborhood Retention Score (NRS) for local nearest-neighbor retention, and Graph Filtration Mutual Information (GFMI) for alignment with the final layer. Applying LRD to 31 models (encoder-based and decoder-based embedders, plus base LLMs) on 30 MTEB tasks reveals architectural and task-level differences that are not apparent from final-layer representations alone. We then use LRD for two applications: label-free model selection and inference-time layer pruning. For selection, all three model-level scores correlate positively with downstream MTEB performance, with end-to-end subspace displacement (d_{0,L}) the strongest, and the same direction holds on a smaller base-LLM MMLU panel. For pruning, GFMI is the only measurement-guided rule that beats Random at the 15% and 20% budgets and has the best median change at every budget. Frenet is effective only at the lightest budget, while NRS does not transfer from model selection to pruning. These results show that layer-wise structure provides signal for both interpretation and deployment decisions.
Ready2Unlearn: A Learning-Time Approach for Preparing Models with Future Unlearning Readiness
May 16, 2025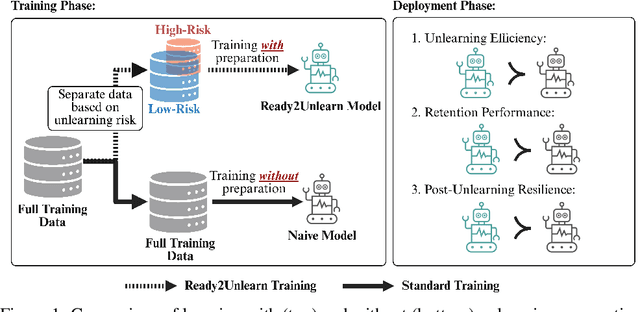


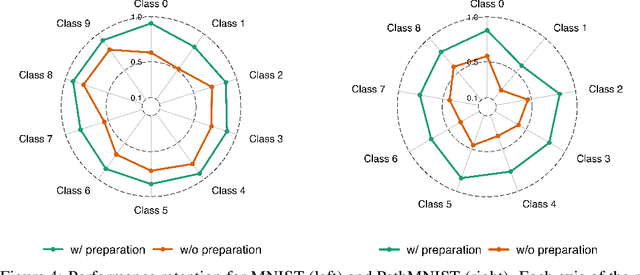
This paper introduces Ready2Unlearn, a learning-time optimization approach designed to facilitate future unlearning processes. Unlike the majority of existing unlearning efforts that focus on designing unlearning algorithms, which are typically implemented reactively when an unlearning request is made during the model deployment phase, Ready2Unlearn shifts the focus to the training phase, adopting a "forward-looking" perspective. Building upon well-established meta-learning principles, Ready2Unlearn proactively trains machine learning models with unlearning readiness, such that they are well prepared and can handle future unlearning requests in a more efficient and principled manner. Ready2Unlearn is model-agnostic and compatible with any gradient ascent-based machine unlearning algorithms. We evaluate the method on both vision and language tasks under various unlearning settings, including class-wise unlearning and random data unlearning. Experimental results show that by incorporating such preparedness at training time, Ready2Unlearn produces an unlearning-ready model state, which offers several key advantages when future unlearning is required, including reduced unlearning time, improved retention of overall model capability, and enhanced resistance to the inadvertent recovery of forgotten data. We hope this work could inspire future efforts to explore more proactive strategies for equipping machine learning models with built-in readiness towards more reliable and principled machine unlearning.
Evaluating and Aligning Human Economic Risk Preferences in LLMs
Mar 09, 2025Large Language Models (LLMs) are increasingly used in decision-making scenarios that involve risk assessment, yet their alignment with human economic rationality remains unclear. In this study, we investigate whether LLMs exhibit risk preferences consistent with human expectations across different personas. Specifically, we assess whether LLM-generated responses reflect appropriate levels of risk aversion or risk-seeking behavior based on individual's persona. Our results reveal that while LLMs make reasonable decisions in simplified, personalized risk contexts, their performance declines in more complex economic decision-making tasks. To address this, we propose an alignment method designed to enhance LLM adherence to persona-specific risk preferences. Our approach improves the economic rationality of LLMs in risk-related applications, offering a step toward more human-aligned AI decision-making.
Predicting Practically? Domain Generalization for Predictive Analytics in Real-world Environments
Mar 05, 2025Predictive machine learning models are widely used in customer relationship management (CRM) to forecast customer behaviors and support decision-making. However, the dynamic nature of customer behaviors often results in significant distribution shifts between training data and serving data, leading to performance degradation in predictive models. Domain generalization, which aims to train models that can generalize to unseen environments without prior knowledge of their distributions, has become a critical area of research. In this work, we propose a novel domain generalization method tailored to handle complex distribution shifts, encompassing both covariate and concept shifts. Our method builds upon the Distributionally Robust Optimization framework, optimizing model performance over a set of hypothetical worst-case distributions rather than relying solely on the training data. Through simulation experiments, we demonstrate the working mechanism of the proposed method. We also conduct experiments on a real-world customer churn dataset, and validate its effectiveness in both temporal and spatial generalization settings. Finally, we discuss the broader implications of our method for advancing Information Systems (IS) design research, particularly in building robust predictive models for dynamic managerial environments.
Beyond Surface Similarity: Detecting Subtle Semantic Shifts in Financial Narratives
Mar 21, 2024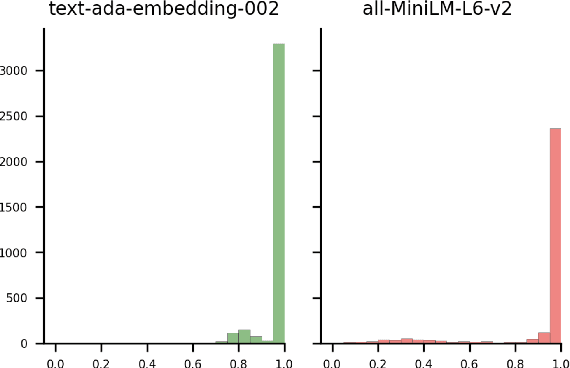

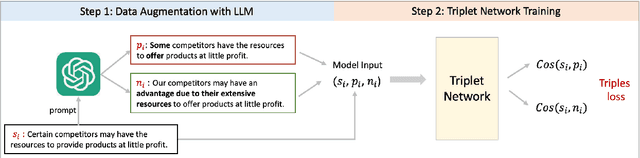

In this paper, we introduce the Financial-STS task, a financial domain-specific NLP task designed to measure the nuanced semantic similarity between pairs of financial narratives. These narratives originate from the financial statements of the same company but correspond to different periods, such as year-over-year comparisons. Measuring the subtle semantic differences between these paired narratives enables market stakeholders to gauge changes over time in the company's financial and operational situations, which is critical for financial decision-making. We find that existing pretrained embedding models and LLM embeddings fall short in discerning these subtle financial narrative shifts. To address this gap, we propose an LLM-augmented pipeline specifically designed for the Financial-STS task. Evaluation on a human-annotated dataset demonstrates that our proposed method outperforms existing methods trained on classic STS tasks and generic LLM embeddings.
Do LLMs Know about Hallucination? An Empirical Investigation of LLM's Hidden States
Feb 15, 2024Large Language Models (LLMs) can make up answers that are not real, and this is known as hallucination. This research aims to see if, how, and to what extent LLMs are aware of hallucination. More specifically, we check whether and how an LLM reacts differently in its hidden states when it answers a question right versus when it hallucinates. To do this, we introduce an experimental framework which allows examining LLM's hidden states in different hallucination situations. Building upon this framework, we conduct a series of experiments with language models in the LLaMA family (Touvron et al., 2023). Our empirical findings suggest that LLMs react differently when processing a genuine response versus a fabricated one. We then apply various model interpretation techniques to help understand and explain the findings better. Moreover, informed by the empirical observations, we show great potential of using the guidance derived from LLM's hidden representation space to mitigate hallucination. We believe this work provides insights into how LLMs produce hallucinated answers and how to make them occur less often.
Bias A-head? Analyzing Bias in Transformer-Based Language Model Attention Heads
Nov 17, 2023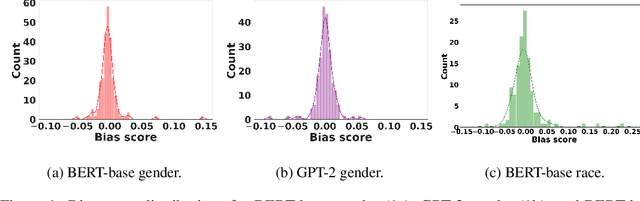
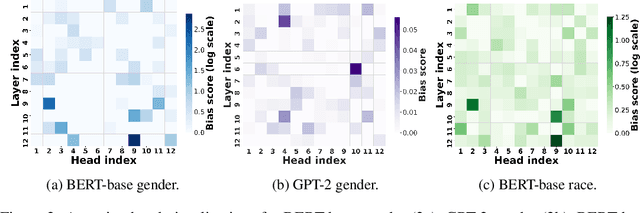
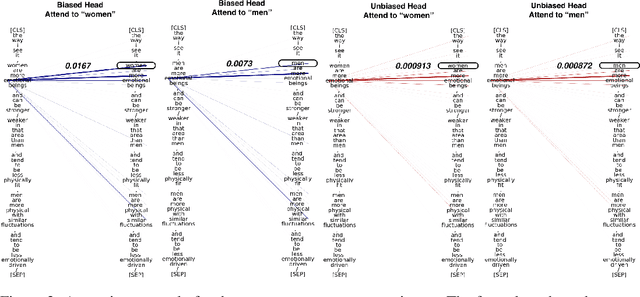
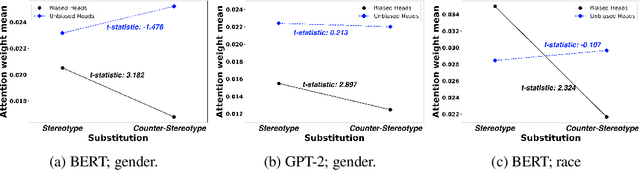
Transformer-based pretrained large language models (PLM) such as BERT and GPT have achieved remarkable success in NLP tasks. However, PLMs are prone to encoding stereotypical biases. Although a burgeoning literature has emerged on stereotypical bias mitigation in PLMs, such as work on debiasing gender and racial stereotyping, how such biases manifest and behave internally within PLMs remains largely unknown. Understanding the internal stereotyping mechanisms may allow better assessment of model fairness and guide the development of effective mitigation strategies. In this work, we focus on attention heads, a major component of the Transformer architecture, and propose a bias analysis framework to explore and identify a small set of biased heads that are found to contribute to a PLM's stereotypical bias. We conduct extensive experiments to validate the existence of these biased heads and to better understand how they behave. We investigate gender and racial bias in the English language in two types of Transformer-based PLMs: the encoder-based BERT model and the decoder-based autoregressive GPT model. Overall, the results shed light on understanding the bias behavior in pretrained language models.
Exploring the Relationship between In-Context Learning and Instruction Tuning
Nov 17, 2023In-Context Learning (ICL) and Instruction Tuning (IT) are two primary paradigms of adopting Large Language Models (LLMs) to downstream applications. However, they are significantly different. In ICL, a set of demonstrations are provided at inference time but the LLM's parameters are not updated. In IT, a set of demonstrations are used to tune LLM's parameters in training time but no demonstrations are used at inference time. Although a growing body of literature has explored ICL and IT, studies on these topics have largely been conducted in isolation, leading to a disconnect between these two paradigms. In this work, we explore the relationship between ICL and IT by examining how the hidden states of LLMs change in these two paradigms. Through carefully designed experiments conducted with LLaMA-2 (7B and 13B), we find that ICL is implicit IT. In other words, ICL changes an LLM's hidden states as if the demonstrations were used to instructionally tune the model. Furthermore, the convergence between ICL and IT is largely contingent upon several factors related to the provided demonstrations. Overall, this work offers a unique perspective to explore the connection between ICL and IT and sheds light on understanding the behaviors of LLM.
InvestLM: A Large Language Model for Investment using Financial Domain Instruction Tuning
Sep 15, 2023We present a new financial domain large language model, InvestLM, tuned on LLaMA-65B (Touvron et al., 2023), using a carefully curated instruction dataset related to financial investment. Inspired by less-is-more-for-alignment (Zhou et al., 2023), we manually curate a small yet diverse instruction dataset, covering a wide range of financial related topics, from Chartered Financial Analyst (CFA) exam questions to SEC filings to Stackexchange quantitative finance discussions. InvestLM shows strong capabilities in understanding financial text and provides helpful responses to investment related questions. Financial experts, including hedge fund managers and research analysts, rate InvestLM's response as comparable to those of state-of-the-art commercial models (GPT-3.5, GPT-4 and Claude-2). Zero-shot evaluation on a set of financial NLP benchmarks demonstrates strong generalizability. From a research perspective, this work suggests that a high-quality domain specific LLM can be tuned using a small set of carefully curated instructions on a well-trained foundation model, which is consistent with the Superficial Alignment Hypothesis (Zhou et al., 2023). From a practical perspective, this work develops a state-of-the-art financial domain LLM with superior capability in understanding financial texts and providing helpful investment advice, potentially enhancing the work efficiency of financial professionals. We release the model parameters to the research community.