 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Semi-Supervised Learning for Natural Language Understanding by Optimizing Diversity
Paper and Code
Oct 09, 2019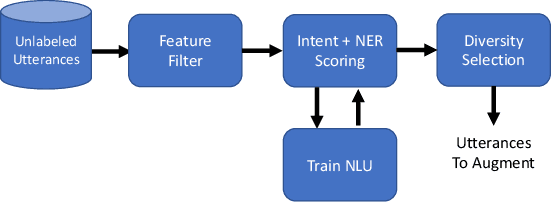
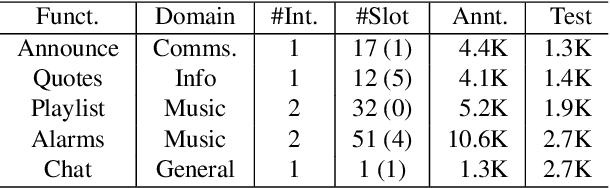
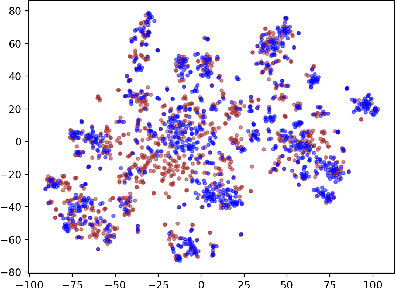
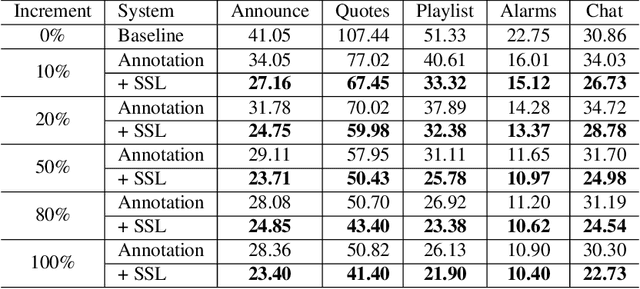
Expanding new functionalities efficiently is an ongoing challenge for single-turn task-oriented dialogue systems. In this work, we explore functionality-specific semi-supervised learning via self-training. We consider methods that augment training data automatically from unlabeled data sets in a functionality-targeted manner. In addition, we examine multiple techniques for efficient selection of augmented utterances to reduce training time and increase diversity. First, we consider paraphrase detection methods that attempt to find utterance variants of labeled training data with good coverage. Second, we explore sub-modular optimization based on n-grams features for utterance selection. Experiments show that functionality-specific self-training is very effective for improving system performance. In addition, methods optimizing diversity can reduce training data in many cases to 50% with little impact on performance.