 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRomanTex: Decoupling 3D-aware Rotary Positional Embedded Multi-Attention Network for Texture Synthesis
Paper and Code
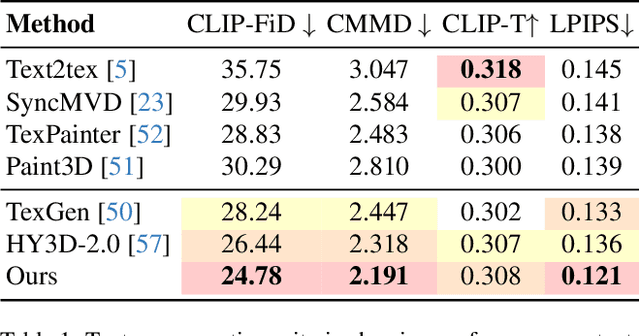

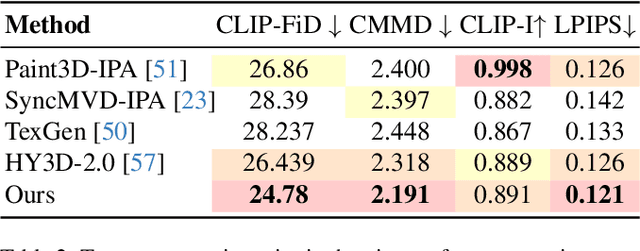

Painting textures for existing geometries is a critical yet labor-intensive process in 3D asset generation. Recent advancements in text-to-image (T2I) models have led to significant progress in texture generation. Most existing research approaches this task by first generating images in 2D spaces using image diffusion models, followed by a texture baking process to achieve UV texture. However, these methods often struggle to produce high-quality textures due to inconsistencies among the generated multi-view images, resulting in seams and ghosting artifacts. In contrast, 3D-based texture synthesis methods aim to address these inconsistencies, but they often neglect 2D diffusion model priors, making them challenging to apply to real-world objects To overcome these limitations, we propose RomanTex, a multiview-based texture generation framework that integrates a multi-attention network with an underlying 3D representation, facilitated by our novel 3D-aware Rotary Positional Embedding. Additionally, we incorporate a decoupling characteristic in the multi-attention block to enhance the model's robustness in image-to-texture task, enabling semantically-correct back-view synthesis. Furthermore, we introduce a geometry-related Classifier-Free Guidance (CFG) mechanism to further improve the alignment with both geometries and images. Quantitative and qualitative evaluations, along with comprehensive user studies, demonstrate that our method achieves state-of-the-art results in texture quality and consistency.