 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Intermediate States: Explaining Visual Redundancy through Language
Mar 26, 2025Multi-modal Large Langue Models (MLLMs) often process thousands of visual tokens, which consume a significant portion of the context window and impose a substantial computational burden. Prior work has empirically explored visual token pruning methods based on MLLMs' intermediate states (e.g., attention scores). However, they have limitations in precisely defining visual redundancy due to their inability to capture the influence of visual tokens on MLLMs' visual understanding (i.e., the predicted probabilities for textual token candidates). To address this issue, we manipulate the visual input and investigate variations in the textual output from both token-centric and context-centric perspectives, achieving intuitive and comprehensive analysis. Experimental results reveal that visual tokens with low ViT-[cls] association and low text-to-image attention scores can contain recognizable information and significantly contribute to images' overall information. To develop a more reliable method for identifying and pruning redundant visual tokens, we integrate these two perspectives and introduce a context-independent condition to identify redundant prototypes from training images, which probes the redundancy of each visual token during inference. Extensive experiments on single-image, multi-image and video comprehension tasks demonstrate the effectiveness of our method, notably achieving 90% to 110% of the performance while pruning 80% to 90% of visual tokens.
BREEN: Bridge Data-Efficient Encoder-Free Multimodal Learning with Learnable Queries
Mar 16, 2025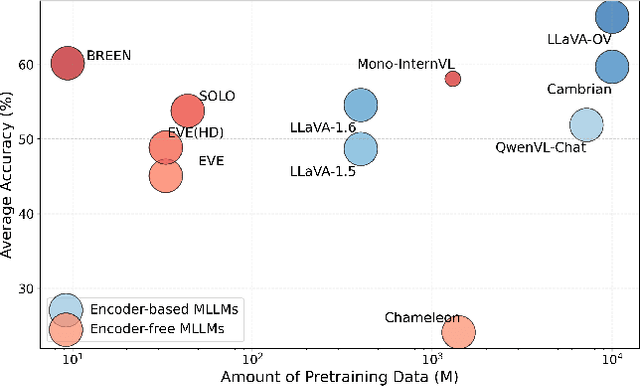
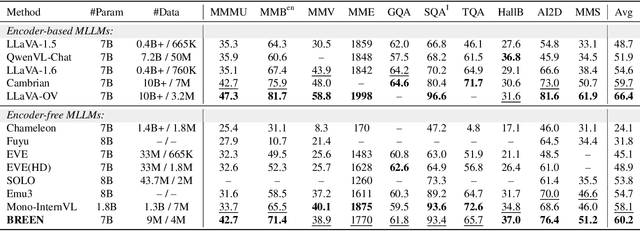
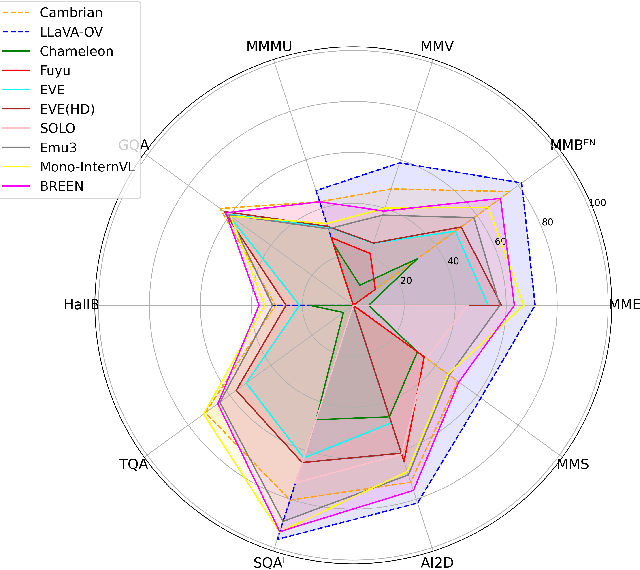
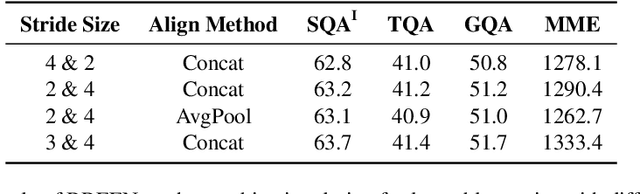
Encoder-free multimodal large language models(MLLMs) eliminate the need for a well-trained vision encoder by directly processing image tokens before the language model. While this approach reduces computational overhead and model complexity, it often requires large amounts of training data to effectively capture the visual knowledge typically encoded by vision models like CLIP. The absence of a vision encoder implies that the model is likely to rely on substantial data to learn the necessary visual-semantic alignments. In this work, we present BREEN, a data-efficient encoder-free multimodal architecture that mitigates this issue. BREEN leverages a learnable query and image experts to achieve comparable performance with significantly less training data. The learnable query, positioned between image and text tokens, is supervised by the output of a pretrained CLIP model to distill visual knowledge, bridging the gap between visual and textual modalities. Additionally, the image expert processes image tokens and learnable queries independently, improving efficiency and reducing interference with the LLM's textual capabilities. BREEN achieves comparable performance to prior encoder-free state-of-the-art models like Mono-InternVL, using only 13 million text-image pairs in training about one percent of the data required by existing methods. Our work highlights a promising direction for data-efficient encoder-free multimodal learning, offering an alternative to traditional encoder-based approaches.
Ola: Pushing the Frontiers of Omni-Modal Language Model with Progressive Modality Alignment
Feb 06, 2025



Recent advances in large language models, particularly following GPT-4o, have sparked increasing interest in developing omni-modal models capable of understanding more modalities. While some open-source alternatives have emerged, there is still a notable lag behind specialized single-modality models in performance. In this paper, we present Ola, an Omni-modal language model that achieves competitive performance across image, video, and audio understanding compared to specialized counterparts. The core design of Ola lies in its progressive modality alignment strategy that extends the supporting modality of the language model progressively. Our training pipeline begins with the most distinct modalities: image and text, then gradually expands the skill sets of the model using speech data that connects language and audio knowledge, and video data that connects all modalities. The progressive learning pipeline also enables us to maintain a relatively small size of the cross-modal alignment data, making developing omni-modal from existing vision-language models easy and less costly. Moreover, to unlock an advanced interactive experience like GPT-4o, we further design a sentence-wise decoding solution for streaming speech generation. Extensive experiments demonstrate that Ola surpasses existing open omni-modal LLMs across all modalities while achieving highly competitive performance compared to state-of-the-art specialized models of similar sizes. We aim to make Ola a fully open omni-modal understanding solution to advance future research in this emerging field. Model weights, code, and data are open-sourced at https://github.com/Ola-Omni/Ola.
Insight-V: Exploring Long-Chain Visual Reasoning with Multimodal Large Language Models
Nov 21, 2024



Large Language Models (LLMs) demonstrate enhanced capabilities and reliability by reasoning more, evolving from Chain-of-Thought prompting to product-level solutions like OpenAI o1. Despite various efforts to improve LLM reasoning, high-quality long-chain reasoning data and optimized training pipelines still remain inadequately explored in vision-language tasks. In this paper, we present Insight-V, an early effort to 1) scalably produce long and robust reasoning data for complex multi-modal tasks, and 2) an effective training pipeline to enhance the reasoning capabilities of multi-modal large language models (MLLMs). Specifically, to create long and structured reasoning data without human labor, we design a two-step pipeline with a progressive strategy to generate sufficiently long and diverse reasoning paths and a multi-granularity assessment method to ensure data quality. We observe that directly supervising MLLMs with such long and complex reasoning data will not yield ideal reasoning ability. To tackle this problem, we design a multi-agent system consisting of a reasoning agent dedicated to performing long-chain reasoning and a summary agent trained to judge and summarize reasoning results. We further incorporate an iterative DPO algorithm to enhance the reasoning agent's generation stability and quality. Based on the popular LLaVA-NeXT model and our stronger base MLLM, we demonstrate significant performance gains across challenging multi-modal benchmarks requiring visual reasoning. Benefiting from our multi-agent system, Insight-V can also easily maintain or improve performance on perception-focused multi-modal tasks.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Parallel Speculative Decoding with Adaptive Draft Length
Aug 13, 2024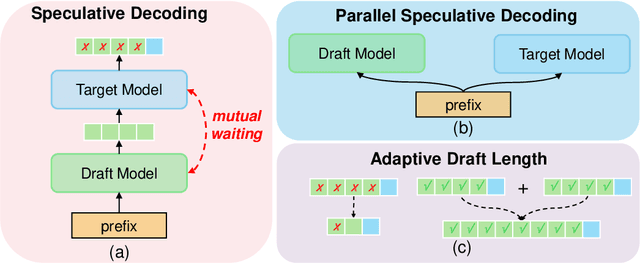

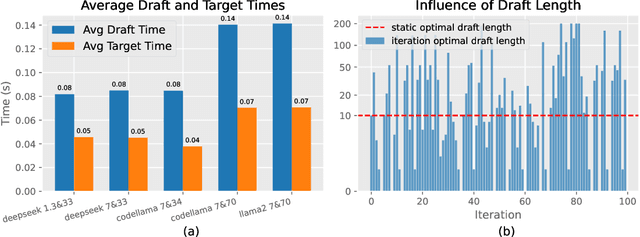

Speculative decoding (SD), where an extra draft model is employed to provide multiple \textit{draft} tokens first and then the original target model verifies these tokens in parallel, has shown great power for LLM inference acceleration. However, existing SD methods suffer from the mutual waiting problem, i.e., the target model gets stuck when the draft model is \textit{guessing} tokens, and vice versa. This problem is directly incurred by the asynchronous execution of the draft model and the target model, and is exacerbated due to the fixed draft length in speculative decoding. To address these challenges, we propose a conceptually simple, flexible, and general framework to boost speculative decoding, namely \textbf{P}arallel sp\textbf{E}culative decoding with \textbf{A}daptive d\textbf{R}aft \textbf{L}ength (PEARL). Specifically, PEARL proposes \textit{pre-verify} to verify the first draft token in advance during the drafting phase, and \textit{post-verify} to generate more draft tokens during the verification phase. PEARL parallels the drafting phase and the verification phase via applying the two strategies, and achieves adaptive draft length for different scenarios, which effectively alleviates the mutual waiting problem. Moreover, we theoretically demonstrate that the mean accepted tokens of PEARL is more than existing \textit{draft-then-verify} works. Experiments on various text generation benchmarks demonstrate the effectiveness of our \name, leading to a superior speedup performance up to \textbf{3.79$\times$} and \textbf{1.52$\times$}, compared to auto-regressive decoding and vanilla speculative decoding, respectively.