 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASRL:A robust loss function with potential for development
Apr 09, 2025In this article, we proposed a partition:wise robust loss function based on the previous robust loss function. The characteristics of this loss function are that it achieves high robustness and a wide range of applicability through partition-wise design and adaptive parameter adjustment. Finally, the advantages and development potential of this loss function were verified by applying this loss function to the regression question and using five different datasets (with different dimensions, different sample numbers, and different fields) to compare with the other loss functions. The results of multiple experiments have proven the advantages of our loss function .
Beyond Intermediate States: Explaining Visual Redundancy through Language
Mar 26, 2025Multi-modal Large Langue Models (MLLMs) often process thousands of visual tokens, which consume a significant portion of the context window and impose a substantial computational burden. Prior work has empirically explored visual token pruning methods based on MLLMs' intermediate states (e.g., attention scores). However, they have limitations in precisely defining visual redundancy due to their inability to capture the influence of visual tokens on MLLMs' visual understanding (i.e., the predicted probabilities for textual token candidates). To address this issue, we manipulate the visual input and investigate variations in the textual output from both token-centric and context-centric perspectives, achieving intuitive and comprehensive analysis. Experimental results reveal that visual tokens with low ViT-[cls] association and low text-to-image attention scores can contain recognizable information and significantly contribute to images' overall information. To develop a more reliable method for identifying and pruning redundant visual tokens, we integrate these two perspectives and introduce a context-independent condition to identify redundant prototypes from training images, which probes the redundancy of each visual token during inference. Extensive experiments on single-image, multi-image and video comprehension tasks demonstrate the effectiveness of our method, notably achieving 90% to 110% of the performance while pruning 80% to 90% of visual tokens.
VidBot: Learning Generalizable 3D Actions from In-the-Wild 2D Human Videos for Zero-Shot Robotic Manipulation
Mar 10, 2025


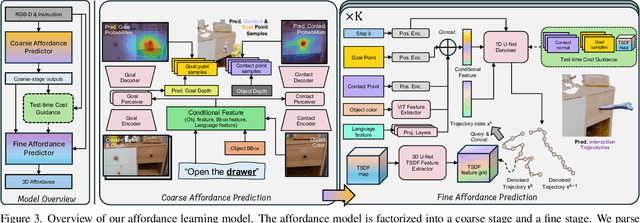
Future robots are envisioned as versatile systems capable of performing a variety of household tasks. The big question remains, how can we bridge the embodiment gap while minimizing physical robot learning, which fundamentally does not scale well. We argue that learning from in-the-wild human videos offers a promising solution for robotic manipulation tasks, as vast amounts of relevant data already exist on the internet. In this work, we present VidBot, a framework enabling zero-shot robotic manipulation using learned 3D affordance from in-the-wild monocular RGB-only human videos. VidBot leverages a pipeline to extract explicit representations from them, namely 3D hand trajectories from videos, combining a depth foundation model with structure-from-motion techniques to reconstruct temporally consistent, metric-scale 3D affordance representations agnostic to embodiments. We introduce a coarse-to-fine affordance learning model that first identifies coarse actions from the pixel space and then generates fine-grained interaction trajectories with a diffusion model, conditioned on coarse actions and guided by test-time constraints for context-aware interaction planning, enabling substantial generalization to novel scenes and embodiments. Extensive experiments demonstrate the efficacy of VidBot, which significantly outperforms counterparts across 13 manipulation tasks in zero-shot settings and can be seamlessly deployed across robot systems in real-world environments. VidBot paves the way for leveraging everyday human videos to make robot learning more scalable.
HACD: Harnessing Attribute Semantics and Mesoscopic Structure for Community Detection
Nov 04, 2024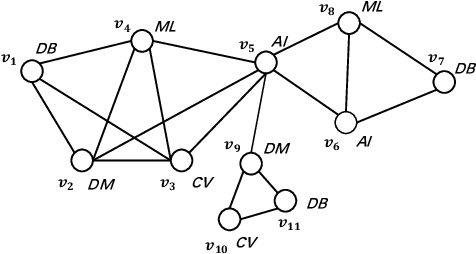
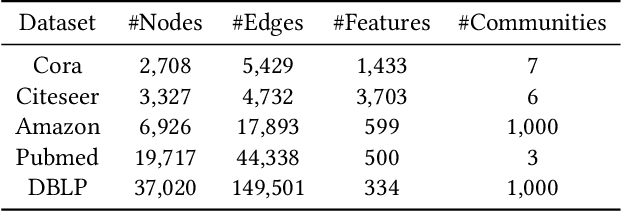
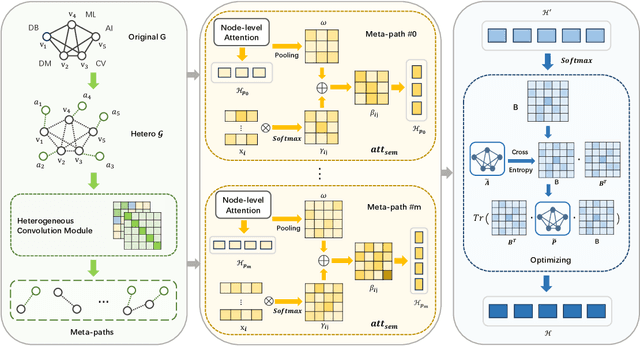
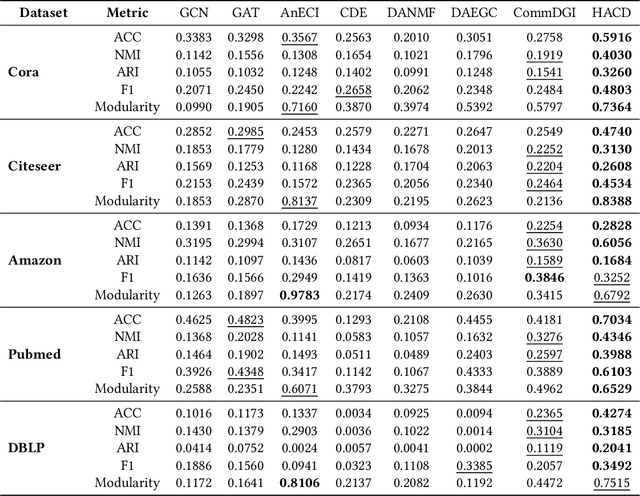
Community detection plays a pivotal role in uncovering closely connected subgraphs, aiding various real-world applications such as recommendation systems and anomaly detection. With the surge of rich information available for entities in real-world networks, the community detection problem in attributed networks has attracted widespread attention. While previous research has effectively leveraged network topology and attribute information for attributed community detection, these methods overlook two critical issues: (i) the semantic similarity between node attributes within the community, and (ii) the inherent mesoscopic structure, which differs from the pairwise connections of the micro-structure. To address these limitations, we propose HACD, a novel attributed community detection model based on heterogeneous graph attention networks. HACD treats node attributes as another type of node, constructs attributed networks into heterogeneous graph structures and employs attribute-level attention mechanisms to capture semantic similarity. Furthermore, HACD introduces a community membership function to explore mesoscopic community structures, enhancing the robustness of detected communities. Extensive experiments demonstrate the effectiveness and efficiency of HACD, outperforming state-of-the-art methods in attributed community detection tasks. Our code is publicly available at https://github.com/Anniran1/HACD1-wsdm.
Visuo-Tactile Exploration of Unknown Rigid 3D Curvatures by Vision-Augmented Unified Force-Impedance Control
Aug 26, 2024



Despite recent advancements in torque-controlled tactile robots, integrating them into manufacturing settings remains challenging, particularly in complex environments. Simplifying robotic skill programming for non-experts is crucial for increasing robot deployment in manufacturing. This work proposes an innovative approach, Vision-Augmented Unified Force-Impedance Control (VA-UFIC), aimed at intuitive visuo-tactile exploration of unknown 3D curvatures. VA-UFIC stands out by seamlessly integrating vision and tactile data, enabling the exploration of diverse contact shapes in three dimensions, including point contacts, flat contacts with concave and convex curvatures, and scenarios involving contact loss. A pivotal component of our method is a robust online contact alignment monitoring system that considers tactile error, local surface curvature, and orientation, facilitating adaptive adjustments of robot stiffness and force regulation during exploration. We introduce virtual energy tanks within the control framework to ensure safety and stability, effectively addressing inherent safety concerns in visuo-tactile exploration. Evaluation using a Franka Emika research robot demonstrates the efficacy of VA-UFIC in exploring unknown 3D curvatures while adhering to arbitrarily defined force-motion policies. By seamlessly integrating vision and tactile sensing, VA-UFIC offers a promising avenue for intuitive exploration of complex environments, with potential applications spanning manufacturing, inspection, and beyond.
Tactile-Morph Skills: Energy-Based Control Meets Data-Driven Learning
Aug 23, 2024Robotic manipulation is essential for modernizing factories and automating industrial tasks like polishing, which require advanced tactile abilities. These robots must be easily set up, safely work with humans, learn tasks autonomously, and transfer skills to similar tasks. Addressing these needs, we introduce the tactile-morph skill framework, which integrates unified force-impedance control with data-driven learning. Our system adjusts robot movements and force application based on estimated energy levels for the desired trajectory and force profile, ensuring safety by stopping if energy allocated for the control runs out. Using a Temporal Convolutional Network, we estimate the energy distribution for a given motion and force profile, enabling skill transfer across different tasks and surfaces. Our approach maintains stability and performance even on unfamiliar geometries with similar friction characteristics, demonstrating improved accuracy, zero-shot transferable performance, and enhanced safety in real-world scenarios. This framework promises to enhance robotic capabilities in industrial settings, making intelligent robots more accessible and valuable.
Task-Aware Dynamic Transformer for Efficient Arbitrary-Scale Image Super-Resolution
Aug 16, 2024



Arbitrary-scale super-resolution (ASSR) aims to learn a single model for image super-resolution at arbitrary magnifying scales. Existing ASSR networks typically comprise an off-the-shelf scale-agnostic feature extractor and an arbitrary scale upsampler. These feature extractors often use fixed network architectures to address different ASSR inference tasks, each of which is characterized by an input image and an upsampling scale. However, this overlooks the difficulty variance of super-resolution on different inference scenarios, where simple images or small SR scales could be resolved with less computational effort than difficult images or large SR scales. To tackle this difficulty variability, in this paper, we propose a Task-Aware Dynamic Transformer (TADT) as an input-adaptive feature extractor for efficient image ASSR. Our TADT consists of a multi-scale feature extraction backbone built upon groups of Multi-Scale Transformer Blocks (MSTBs) and a Task-Aware Routing Controller (TARC). The TARC predicts the inference paths within feature extraction backbone, specifically selecting MSTBs based on the input images and SR scales. The prediction of inference path is guided by a new loss function to trade-off the SR accuracy and efficiency. Experiments demonstrate that, when working with three popular arbitrary-scale upsamplers, our TADT achieves state-of-the-art ASSR performance when compared with mainstream feature extractors, but with relatively fewer computational costs. The code will be publicly released.
Fusion-Correction Network for Single-Exposure Correction and Multi-Exposure Fusion
Mar 05, 2022
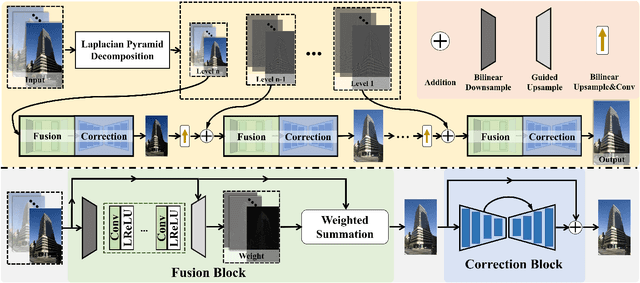


The photographs captured by digital cameras usually suffer from over-exposure or under-exposure problems. The Single-Exposure Correction (SEC) and Multi-Exposure Fusion (MEF) are two widely studied image processing tasks for image exposure enhancement. However, current SEC and MEF methods ignore the internal correlation between SEC and MEF, and are proposed under distinct frameworks. What's more, most MEF methods usually fail at processing a sequence containing only under-exposed or over-exposed images. To alleviate these problems, in this paper, we develop an integrated framework to simultaneously tackle the SEC and MEF tasks. Built upon the Laplacian Pyramid (LP) decomposition, we propose a novel Fusion-Correction Network (FCNet) to fuse and correct an image sequence sequentially in a multi-level scheme. In each LP level, the image sequence is feed into a Fusion block and a Correction block for consecutive image fusion and exposure correction. The corrected image is upsampled and re-composed with the high-frequency detail components in next-level, producing the base sequence for the next-level blocks. Experiments on the benchmark dataset demonstrate that our FCNet is effective on both the SEC and MEF tasks.