 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTADS: Task-Aware Data Selection for Multi-Task Multimodal Pre-Training
Feb 05, 2026Large-scale multimodal pre-trained models like CLIP rely heavily on high-quality training data, yet raw web-crawled datasets are often noisy, misaligned, and redundant, leading to inefficient training and suboptimal generalization. Existing data selection methods are either heuristic-based, suffering from bias and limited diversity, or data-driven but task-agnostic, failing to optimize for multi-task scenarios. To address these gaps, we introduce TADS (Task-Aware Data Selection), a novel framework for multi-task multimodal pre-training that integrates Intrinsic Quality, Task Relevance, and Distributional Diversity into a learnable value function. TADS employs a comprehensive quality assessment system with unimodal and cross-modal operators, quantifies task relevance via interpretable similarity vectors, and optimizes diversity through cluster-based weighting. A feedback-driven meta-learning mechanism adaptively refines the selection strategy based on proxy model performance across multiple downstream tasks. Experiments on CC12M demonstrate that TADS achieves superior zero-shot performance on benchmarks like ImageNet, CIFAR-100, MS-COCO, and Flickr30K, using only 36% of the data while outperforming baselines by an average of 1.0%. This highlights that TADS significantly enhances data efficiency by curating a high-utility subset that yields a much higher performance ceiling within the same computational constraints.
E2PL: Effective and Efficient Prompt Learning for Incomplete Multi-view Multi-Label Class Incremental Learning
Jan 23, 2026Multi-view multi-label classification (MvMLC) is indispensable for modern web applications aggregating information from diverse sources. However, real-world web-scale settings are rife with missing views and continuously emerging classes, which pose significant obstacles to robust learning. Prevailing methods are ill-equipped for this reality, as they either lack adaptability to new classes or incur exponential parameter growth when handling all possible missing-view patterns, severely limiting their scalability in web environments. To systematically address this gap, we formally introduce a novel task, termed \emph{incomplete multi-view multi-label class incremental learning} (IMvMLCIL), which requires models to simultaneously address heterogeneous missing views and dynamic class expansion. To tackle this task, we propose \textsf{E2PL}, an Effective and Efficient Prompt Learning framework for IMvMLCIL. \textsf{E2PL} unifies two novel prompt designs: \emph{task-tailored prompts} for class-incremental adaptation and \emph{missing-aware prompts} for the flexible integration of arbitrary view-missing scenarios. To fundamentally address the exponential parameter explosion inherent in missing-aware prompts, we devise an \emph{efficient prototype tensorization} module, which leverages atomic tensor decomposition to elegantly reduce the prompt parameter complexity from exponential to linear w.r.t. the number of views. We further incorporate a \emph{dynamic contrastive learning} strategy explicitly model the complex dependencies among diverse missing-view patterns, thus enhancing the model's robustness. Extensive experiments on three benchmarks demonstrate that \textsf{E2PL} consistently outperforms state-of-the-art methods in both effectiveness and efficiency. The codes and datasets are available at https://anonymous.4open.science/r/code-for-E2PL.
Video-QTR: Query-Driven Temporal Reasoning Framework for Lightweight Video Understanding
Dec 10, 2025The rapid development of multimodal large-language models (MLLMs) has significantly expanded the scope of visual language reasoning, enabling unified systems to interpret and describe complex visual content. However, applying these models to long-video understanding remains computationally intensive. Dense frame encoding generates excessive visual tokens, leading to high memory consumption, redundant computation, and limited scalability in real-world applications. This inefficiency highlights a key limitation of the traditional process-then-reason paradigm, which analyzes visual streams exhaustively before semantic reasoning. To address this challenge, we introduce Video-QTR (Query-Driven Temporal Reasoning), a lightweight framework that redefines video comprehension as a query-guided reasoning process. Instead of encoding every frame, Video-QTR dynamically allocates perceptual resources based on the semantic intent of the query, creating an adaptive feedback loop between reasoning and perception. Extensive experiments across five benchmarks: MSVD-QA, Activity Net-QA, Movie Chat, and Video MME demonstrate that Video-QTR achieves state-of-the-art performance while reducing input frame consumption by up to 73%. These results confirm that query-driven temporal reasoning provides an efficient and scalable solution for video understanding.
Walking the Schrödinger Bridge: A Direct Trajectory for Text-to-3D Generation
Nov 06, 2025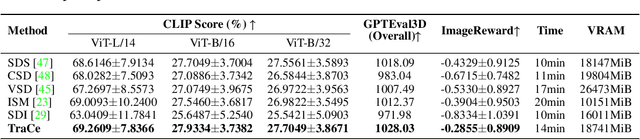
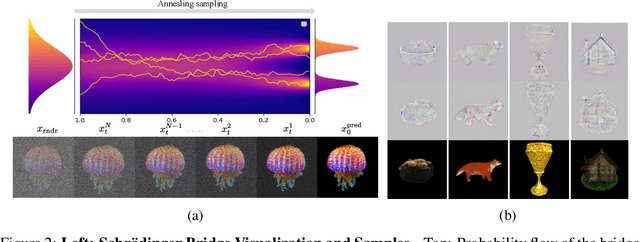

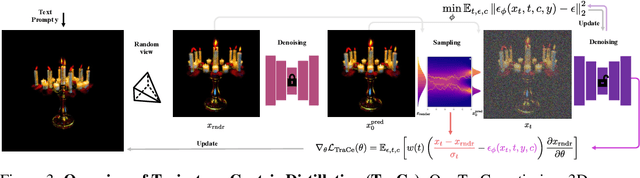
Recent advancements in optimization-based text-to-3D generation heavily rely on distilling knowledge from pre-trained text-to-image diffusion models using techniques like Score Distillation Sampling (SDS), which often introduce artifacts such as over-saturation and over-smoothing into the generated 3D assets. In this paper, we address this essential problem by formulating the generation process as learning an optimal, direct transport trajectory between the distribution of the current rendering and the desired target distribution, thereby enabling high-quality generation with smaller Classifier-free Guidance (CFG) values. At first, we theoretically establish SDS as a simplified instance of the Schrödinger Bridge framework. We prove that SDS employs the reverse process of an Schrödinger Bridge, which, under specific conditions (e.g., a Gaussian noise as one end), collapses to SDS's score function of the pre-trained diffusion model. Based upon this, we introduce Trajectory-Centric Distillation (TraCe), a novel text-to-3D generation framework, which reformulates the mathematically trackable framework of Schrödinger Bridge to explicitly construct a diffusion bridge from the current rendering to its text-conditioned, denoised target, and trains a LoRA-adapted model on this trajectory's score dynamics for robust 3D optimization. Comprehensive experiments demonstrate that TraCe consistently achieves superior quality and fidelity to state-of-the-art techniques.
SatFusion: A Unified Framework for Enhancing Satellite IoT Images via Multi-Temporal and Multi-Source Data Fusion
Oct 09, 2025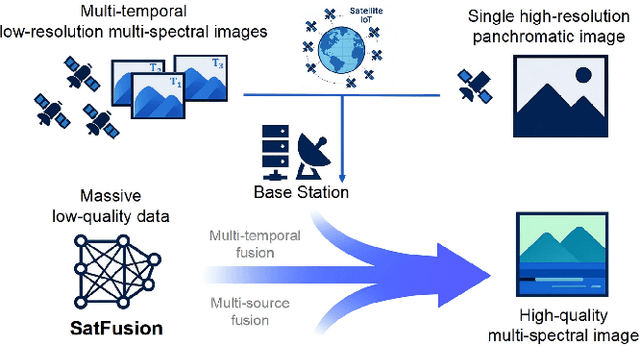
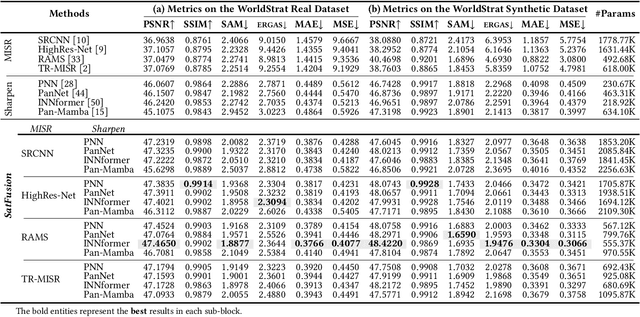
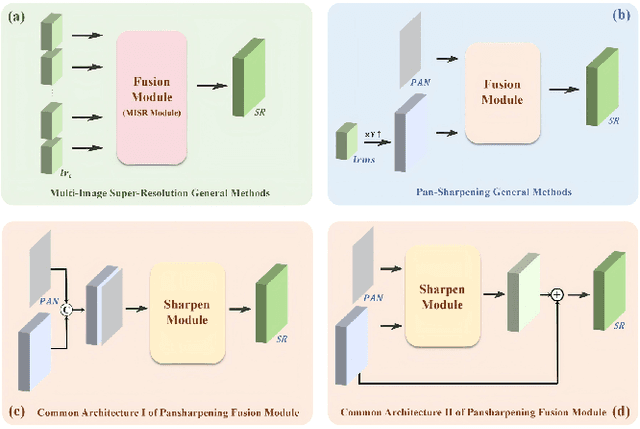
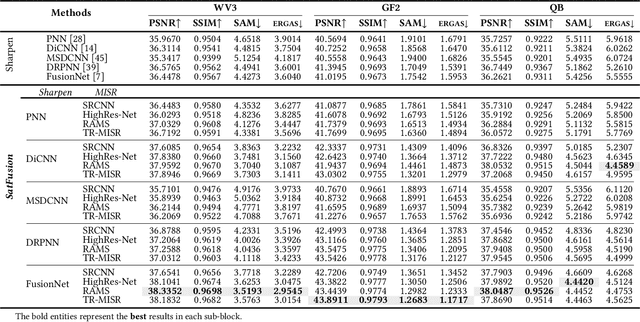
With the rapid advancement of the digital society, the proliferation of satellites in the Satellite Internet of Things (Sat-IoT) has led to the continuous accumulation of large-scale multi-temporal and multi-source images across diverse application scenarios. However, existing methods fail to fully exploit the complementary information embedded in both temporal and source dimensions. For example, Multi-Image Super-Resolution (MISR) enhances reconstruction quality by leveraging temporal complementarity across multiple observations, yet the limited fine-grained texture details in input images constrain its performance. Conversely, pansharpening integrates multi-source images by injecting high-frequency spatial information from panchromatic data, but typically relies on pre-interpolated low-resolution inputs and assumes noise-free alignment, making it highly sensitive to noise and misregistration. To address these issues, we propose SatFusion: A Unified Framework for Enhancing Satellite IoT Images via Multi-Temporal and Multi-Source Data Fusion. Specifically, SatFusion first employs a Multi-Temporal Image Fusion (MTIF) module to achieve deep feature alignment with the panchromatic image. Then, a Multi-Source Image Fusion (MSIF) module injects fine-grained texture information from the panchromatic data. Finally, a Fusion Composition module adaptively integrates the complementary advantages of both modalities while dynamically refining spectral consistency, supervised by a weighted combination of multiple loss functions. Extensive experiments on the WorldStrat, WV3, QB, and GF2 datasets demonstrate that SatFusion significantly improves fusion quality, robustness under challenging conditions, and generalizability to real-world Sat-IoT scenarios. The code is available at: https://github.com/dllgyufei/SatFusion.git.
LightRouter: Towards Efficient LLM Collaboration with Minimal Overhead
May 22, 2025The rapid advancement of large language models has unlocked remarkable capabilities across a diverse array of natural language processing tasks. However, the considerable differences among available LLMs-in terms of cost, performance, and computational demands-pose significant challenges for users aiming to identify the most suitable model for specific tasks. In this work, we present LightRouter, a novel framework designed to systematically select and integrate a small subset of LLMs from a larger pool, with the objective of jointly optimizing both task performance and cost efficiency. LightRouter leverages an adaptive selection mechanism to identify models that require only a minimal number of boot tokens, thereby reducing costs, and further employs an effective integration strategy to combine their outputs. Extensive experiments across multiple benchmarks demonstrate that LightRouter matches or outperforms widely-used ensemble baselines, achieving up to a 25% improvement in accuracy. Compared with leading high-performing models, LightRouter achieves comparable performance while reducing inference costs by up to 27%. Importantly, our framework operates without any prior knowledge of individual models and relies exclusively on inexpensive, lightweight models. This work introduces a practical approach for efficient LLM selection and provides valuable insights into optimal strategies for model combination.
SeMi: When Imbalanced Semi-Supervised Learning Meets Mining Hard Examples
Jan 10, 2025



Semi-Supervised Learning (SSL) can leverage abundant unlabeled data to boost model performance. However, the class-imbalanced data distribution in real-world scenarios poses great challenges to SSL, resulting in performance degradation. Existing class-imbalanced semi-supervised learning (CISSL) methods mainly focus on rebalancing datasets but ignore the potential of using hard examples to enhance performance, making it difficult to fully harness the power of unlabeled data even with sophisticated algorithms. To address this issue, we propose a method that enhances the performance of Imbalanced Semi-Supervised Learning by Mining Hard Examples (SeMi). This method distinguishes the entropy differences among logits of hard and easy examples, thereby identifying hard examples and increasing the utility of unlabeled data, better addressing the imbalance problem in CISSL. In addition, we maintain a class-balanced memory bank with confidence decay for storing high-confidence embeddings to enhance the pseudo-labels' reliability. Although our method is simple, it is effective and seamlessly integrates with existing approaches. We perform comprehensive experiments on standard CISSL benchmarks and experimentally demonstrate that our proposed SeMi outperforms existing state-of-the-art methods on multiple benchmarks, especially in reversed scenarios, where our best result shows approximately a 54.8\% improvement over the baseline methods.