 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATOM: Instantiating Budget-Controllable Multi-Agent Collaboration via Nucleus-Electron Hierarchy
May 25, 2026Large Language Model (LLM)-based multi-agent systems rely on optimized collaboration topologies to balance performance and communication costs. However, current methods struggle with the inherent stability-extensibility trade-off and often misalign computational budgets with query difficulty. We propose \textsc{ATOM}, an adaptive framework that generates budget-controllable collaboration graphs via a novel task-driven reinforcement learning paradigm. Inspired by atomic structures, \textsc{ATOM} employs a nucleus-electron hierarchy: it maintains a stable, offline-learned collaboration backbone (the nucleus) while dynamically activating query-conditioned agents (electrons) during inference. Crucially, a complexity-aware budgeting strategy aligns resource consumption with task demands by estimating query difficulty to strictly regulate electron instantiation. Extensive experiments across six diverse benchmarks demonstrate that \textsc{ATOM} achieves state-of-the-art performance while improving token efficiency by up to $30\%$ compared to strong baselines.
Video-QTR: Query-Driven Temporal Reasoning Framework for Lightweight Video Understanding
Dec 10, 2025The rapid development of multimodal large-language models (MLLMs) has significantly expanded the scope of visual language reasoning, enabling unified systems to interpret and describe complex visual content. However, applying these models to long-video understanding remains computationally intensive. Dense frame encoding generates excessive visual tokens, leading to high memory consumption, redundant computation, and limited scalability in real-world applications. This inefficiency highlights a key limitation of the traditional process-then-reason paradigm, which analyzes visual streams exhaustively before semantic reasoning. To address this challenge, we introduce Video-QTR (Query-Driven Temporal Reasoning), a lightweight framework that redefines video comprehension as a query-guided reasoning process. Instead of encoding every frame, Video-QTR dynamically allocates perceptual resources based on the semantic intent of the query, creating an adaptive feedback loop between reasoning and perception. Extensive experiments across five benchmarks: MSVD-QA, Activity Net-QA, Movie Chat, and Video MME demonstrate that Video-QTR achieves state-of-the-art performance while reducing input frame consumption by up to 73%. These results confirm that query-driven temporal reasoning provides an efficient and scalable solution for video understanding.
Multi-Modal One-Shot Federated Ensemble Learning for Medical Data with Vision Large Language Model
Jan 06, 2025



Federated learning (FL) has attracted considerable interest in the medical domain due to its capacity to facilitate collaborative model training while maintaining data privacy. However, conventional FL methods typically necessitate multiple communication rounds, leading to significant communication overhead and delays, especially in environments with limited bandwidth. One-shot federated learning addresses these issues by conducting model training and aggregation in a single communication round, thereby reducing communication costs while preserving privacy. Among these, one-shot federated ensemble learning combines independently trained client models using ensemble techniques such as voting, further boosting performance in non-IID data scenarios. On the other hand, existing machine learning methods in healthcare predominantly use unimodal data (e.g., medical images or textual reports), which restricts their diagnostic accuracy and comprehensiveness. Therefore, the integration of multi-modal data is proposed to address these shortcomings. In this paper, we introduce FedMME, an innovative one-shot multi-modal federated ensemble learning framework that utilizes multi-modal data for medical image analysis. Specifically, FedMME capitalizes on vision large language models to produce textual reports from medical images, employs a BERT model to extract textual features from these reports, and amalgamates these features with visual features to improve diagnostic accuracy. Experimental results show that our method demonstrated superior performance compared to existing one-shot federated learning methods in healthcare scenarios across four datasets with various data distributions. For instance, it surpasses existing one-shot federated learning approaches by more than 17.5% in accuracy on the RSNA dataset when applying a Dirichlet distribution with ($\alpha$ = 0.3).
Data-Free Federated Class Incremental Learning with Diffusion-Based Generative Memory
May 22, 2024Federated Class Incremental Learning (FCIL) is a critical yet largely underexplored issue that deals with the dynamic incorporation of new classes within federated learning (FL). Existing methods often employ generative adversarial networks (GANs) to produce synthetic images to address privacy concerns in FL. However, GANs exhibit inherent instability and high sensitivity, compromising the effectiveness of these methods. In this paper, we introduce a novel data-free federated class incremental learning framework with diffusion-based generative memory (DFedDGM) to mitigate catastrophic forgetting by generating stable, high-quality images through diffusion models. We design a new balanced sampler to help train the diffusion models to alleviate the common non-IID problem in FL, and introduce an entropy-based sample filtering technique from an information theory perspective to enhance the quality of generative samples. Finally, we integrate knowledge distillation with a feature-based regularization term for better knowledge transfer. Our framework does not incur additional communication costs compared to the baseline FedAvg method. Extensive experiments across multiple datasets demonstrate that our method significantly outperforms existing baselines, e.g., over a 4% improvement in average accuracy on the Tiny-ImageNet dataset.
One-Shot Sequential Federated Learning for Non-IID Data by Enhancing Local Model Diversity
Apr 18, 2024Traditional federated learning mainly focuses on parallel settings (PFL), which can suffer significant communication and computation costs. In contrast, one-shot and sequential federated learning (SFL) have emerged as innovative paradigms to alleviate these costs. However, the issue of non-IID (Independent and Identically Distributed) data persists as a significant challenge in one-shot and SFL settings, exacerbated by the restricted communication between clients. In this paper, we improve the one-shot sequential federated learning for non-IID data by proposing a local model diversity-enhancing strategy. Specifically, to leverage the potential of local model diversity for improving model performance, we introduce a local model pool for each client that comprises diverse models generated during local training, and propose two distance measurements to further enhance the model diversity and mitigate the effect of non-IID data. Consequently, our proposed framework can improve the global model performance while maintaining low communication costs. Extensive experiments demonstrate that our method exhibits superior performance to existing one-shot PFL methods and achieves better accuracy compared with state-of-the-art one-shot SFL methods on both label-skew and domain-shift tasks (e.g., 6%+ accuracy improvement on the CIFAR-10 dataset).
Data-Free Diversity-Based Ensemble Selection For One-Shot Federated Learning in Machine Learning Model Market
Feb 23, 2023



The emerging availability of trained machine learning models has put forward the novel concept of Machine Learning Model Market in which one can harness the collective intelligence of multiple well-trained models to improve the performance of the resultant model through one-shot federated learning and ensemble learning in a data-free manner. However, picking the models available in the market for ensemble learning is time-consuming, as using all the models is not always the best approach. It is thus crucial to have an effective ensemble selection strategy that can find a good subset of the base models for the ensemble. Conventional ensemble selection techniques are not applicable, as we do not have access to the local datasets of the parties in the federated learning setting. In this paper, we present a novel Data-Free Diversity-Based method called DeDES to address the ensemble selection problem for models generated by one-shot federated learning in practical applications such as model markets. Experiments showed that our method can achieve both better performance and higher efficiency over 5 datasets and 4 different model structures under the different data-partition strategies.
A Latent Feelings-aware RNN Model for User Churn Prediction with Behavioral Data
Nov 06, 2019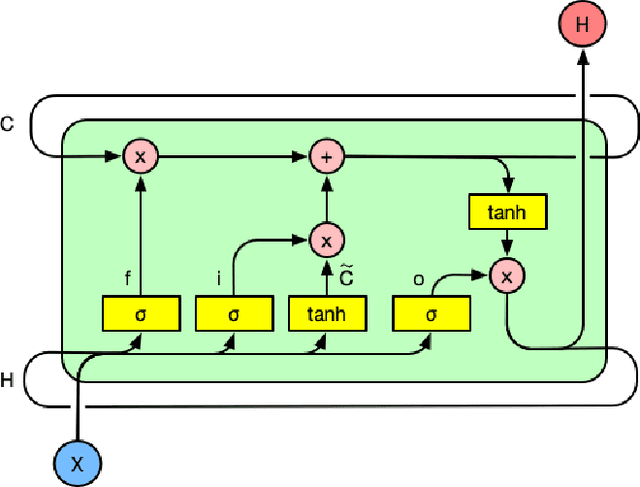
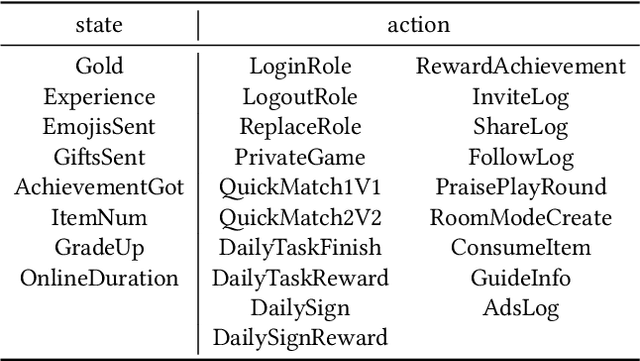
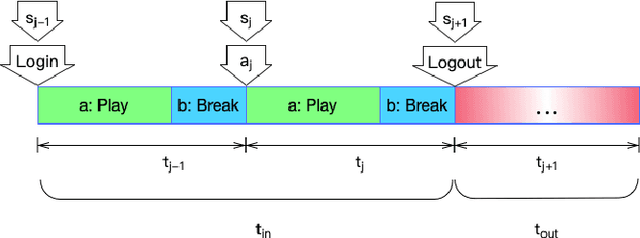
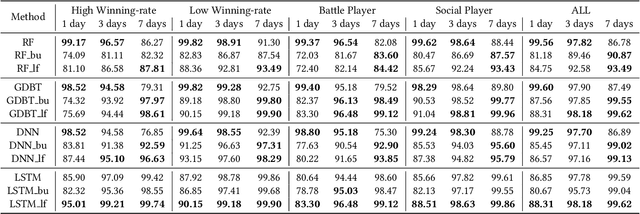
Predicting user churn and taking personalized measures to retain users is a set of common and effective practices for online game operators. However, different from the traditional user churn relevant researches that can involve demographic, economic, and behavioral data, most online games can only obtain logs of user behavior and have no access to users' latent feelings. There are mainly two challenges in this work: 1. The latent feelings, which cannot be directly observed in this work, need to be estimated and verified; 2. User churn needs to be predicted with only behavioral data. In this work, a Recurrent Neural Network(RNN) called LaFee (Latent Feeling) is proposed, which can get the users' latent feelings while predicting user churn. Besides, we proposed a method named BMM-UCP (Behavior-based Modeling Method for User Churn Prediction) to help models predict user churn with only behavioral data. The latent feelings are names as satisfaction and aspiration in this work. We designed experiments on a real dataset and the results show that our methods outperform baselines and are more suitable for long-term sequential learning. The latent feelings learned are fully discussed and proven meaningful.