 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoAgent: Towards Reliable Echocardiography Interpretation with "Eyes","Hands" and "Minds"
Apr 07, 2026Reliable interpretation of echocardiography (Echo) is crucial for assessing cardiac function, which demands clinicians to synchronously orchestrate multiple capabilities, including visual observation (eyes), manual measurement (hands), and expert knowledge learning and reasoning (minds). While current task-specific deep-learning approaches and multimodal large language models have demonstrated promise in assisting Echo analysis through automated segmentation or reasoning, they remain focused on restricted skills, i.e., eyes-hands or eyes-minds, thereby limiting clinical reliability and utility. To address these issues, we propose EchoAgent, an agentic system tailored for end-to-end Echo interpretation, which achieves a fully coordinated eyes-hands-minds workflow that learns, observes, operates, and reasons like a cardiac sonographer. First, we introduce an expertise-driven cognition engine where our agent can automatically assimilate credible Echo guidelines into a structured knowledge base, thus constructing an Echo-customized mind. Second, we devise a hierarchical collaboration toolkit to endow EchoAgent with eyes-hands, which can automatically parse Echo video streams, identify cardiac views, perform anatomical segmentation, and quantitative measurement. Third, we integrate the perceived multimodal evidence with the exclusive knowledge base into an orchestrated reasoning hub to conduct explainable inferences. We evaluate EchoAgent on CAMUS and MIMIC-EchoQA datasets, which cover 48 distinct echocardiographic views spanning 14 cardiac anatomical regions. Experimental results show that EchoAgent achieves optimal performance across diverse structure analyses, yielding overall accuracy of up to 80.00%. Importantly, EchoAgent empowers a single system with abilities to learn, observe, operate and reason like an echocardiologist, which holds great promise for reliable Echo interpretation.
Evaluation Report on MCP Servers
Apr 15, 2025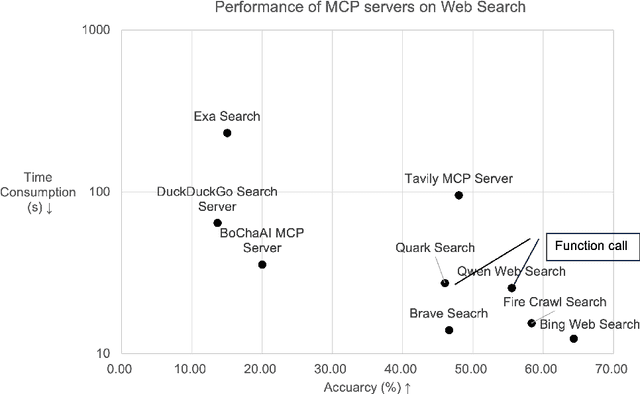

With the rise of LLMs, a large number of Model Context Protocol (MCP) services have emerged since the end of 2024. However, the effectiveness and efficiency of MCP servers have not been well studied. To study these questions, we propose an evaluation framework, called MCPBench. We selected several widely used MCP server and conducted an experimental evaluation on their accuracy, time, and token usage. Our experiments showed that the most effective MCP, Bing Web Search, achieved an accuracy of 64%. Importantly, we found that the accuracy of MCP servers can be substantially enhanced by involving declarative interface. This research paves the way for further investigations into optimized MCP implementations, ultimately leading to better AI-driven applications and data retrieval solutions.
Automatic database description generation for Text-to-SQL
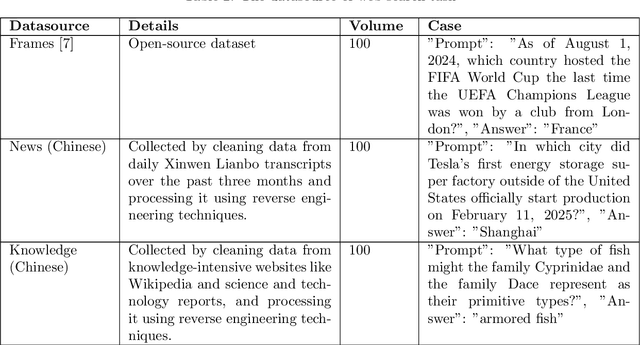
Feb 28, 2025In the context of the Text-to-SQL task, table and column descriptions are crucial for bridging the gap between natural language and database schema. This report proposes a method for automatically generating effective database descriptions when explicit descriptions are unavailable. The proposed method employs a dual-process approach: a coarse-to-fine process, followed by a fine-to-coarse process. The coarse-to-fine approach leverages the inherent knowledge of LLM to guide the understanding process from databases to tables and finally to columns. This approach provides a holistic understanding of the database structure and ensures contextual alignment. Conversely, the fine-to-coarse approach starts at the column level, offering a more accurate and nuanced understanding when stepping back to the table level. Experimental results on the Bird benchmark indicate that using descriptions generated by the proposed improves SQL generation accuracy by 0.93\% compared to not using descriptions, and achieves 37\% of human-level performance. The source code is publicly available at https://github.com/XGenerationLab/XiYan-DBDescGen.
Reinforced Large Language Model is a formal theorem prover
Feb 13, 2025To take advantage of Large Language Model in theorem formalization and proof, we propose a reinforcement learning framework to iteratively optimize the pretrained LLM by rolling out next tactics and comparing them with the expected ones. The experiment results show that it helps to achieve a higher accuracy compared with directly fine-tuned LLM.
CBraMod: A Criss-Cross Brain Foundation Model for EEG Decoding
Dec 10, 2024



Electroencephalography (EEG) is a non-invasive technique to measure and record brain electrical activity, widely used in various BCI and healthcare applications. Early EEG decoding methods rely on supervised learning, limited by specific tasks and datasets, hindering model performance and generalizability. With the success of large language models, there is a growing body of studies focusing on EEG foundation models. However, these studies still leave challenges: Firstly, most of existing EEG foundation models employ full EEG modeling strategy. It models the spatial and temporal dependencies between all EEG patches together, but ignores that the spatial and temporal dependencies are heterogeneous due to the unique structural characteristics of EEG signals. Secondly, existing EEG foundation models have limited generalizability on a wide range of downstream BCI tasks due to varying formats of EEG data, making it challenging to adapt to. To address these challenges, we propose a novel foundation model called CBraMod. Specifically, we devise a criss-cross transformer as the backbone to thoroughly leverage the structural characteristics of EEG signals, which can model spatial and temporal dependencies separately through two parallel attention mechanisms. And we utilize an asymmetric conditional positional encoding scheme which can encode positional information of EEG patches and be easily adapted to the EEG with diverse formats. CBraMod is pre-trained on a very large corpus of EEG through patch-based masked EEG reconstruction. We evaluate CBraMod on up to 10 downstream BCI tasks (12 public datasets). CBraMod achieves the state-of-the-art performance across the wide range of tasks, proving its strong capability and generalizability. The source code is publicly available at \url{https://github.com/wjq-learning/CBraMod}.
XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL
Nov 13, 2024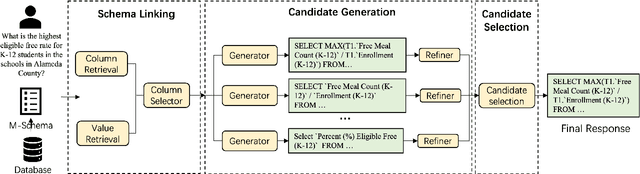
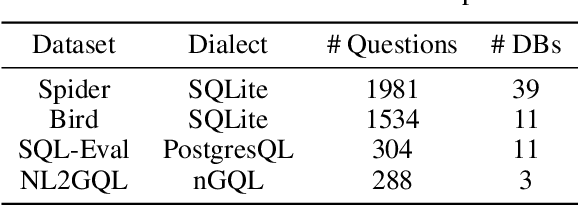


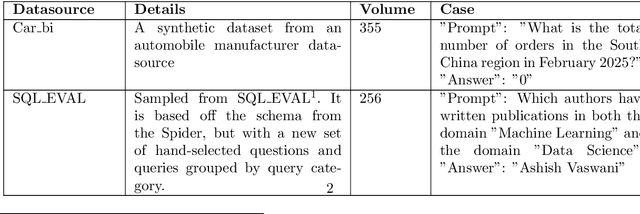
To tackle the challenges of large language model performance in natural language to SQL tasks, we introduce XiYan-SQL, an innovative framework that employs a multi-generator ensemble strategy to improve candidate generation. We introduce M-Schema, a semi-structured schema representation method designed to enhance the understanding of database structures. To enhance the quality and diversity of generated candidate SQL queries, XiYan-SQL integrates the significant potential of in-context learning (ICL) with the precise control of supervised fine-tuning. On one hand, we propose a series of training strategies to fine-tune models to generate high-quality candidates with diverse preferences. On the other hand, we implement the ICL approach with an example selection method based on named entity recognition to prevent overemphasis on entities. The refiner optimizes each candidate by correcting logical or syntactical errors. To address the challenge of identifying the best candidate, we fine-tune a selection model to distinguish nuances of candidate SQL queries. The experimental results on multiple dialect datasets demonstrate the robustness of XiYan-SQL in addressing challenges across different scenarios. Overall, our proposed XiYan-SQL achieves the state-of-the-art execution accuracy of 89.65% on the Spider test set, 69.86% on SQL-Eval, 41.20% on NL2GQL, and a competitive score of 72.23% on the Bird development benchmark. The proposed framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods.
MoMQ: Mixture-of-Experts Enhances Multi-Dialect Query Generation across Relational and Non-Relational Databases
Oct 24, 2024



The improvement in translating natural language to structured query language (SQL) can be attributed to the advancements in large language models (LLMs). Open-source LLMs, tailored for specific database dialects such as MySQL, have shown great performance. However, cloud service providers are looking for a unified database manager service (e.g., Cosmos DB from Azure, Amazon Aurora from AWS, Lindorm from AlibabaCloud) that can support multiple dialects. This requirement has led to the concept of multi-dialect query generation, which presents challenges to LLMs. These challenges include syntactic differences among dialects and imbalanced data distribution across multiple dialects. To tackle these challenges, we propose MoMQ, a novel Mixture-of-Experts-based multi-dialect query generation framework across both relational and non-relational databases. MoMQ employs a dialect expert group for each dialect and a multi-level routing strategy to handle dialect-specific knowledge, reducing interference during query generation. Additionally, a shared expert group is introduced to address data imbalance, facilitating the transfer of common knowledge from high-resource dialects to low-resource ones. Furthermore, we have developed a high-quality multi-dialect query generation benchmark that covers relational and non-relational databases such as MySQL, PostgreSQL, Cypher for Neo4j, and nGQL for NebulaGraph. Extensive experiments have shown that MoMQ performs effectively and robustly even in resource-imbalanced scenarios.
Towards Loose-Fitting Garment Animation via Generative Model of Deformation Decomposition
Dec 22, 2023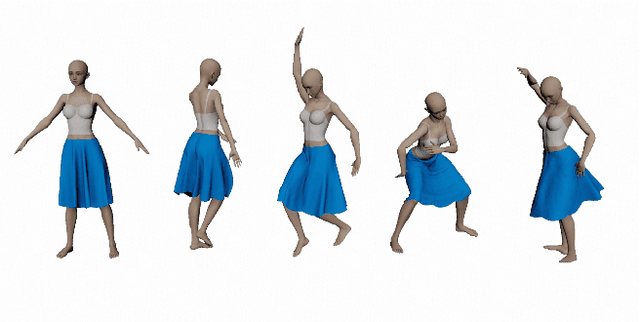
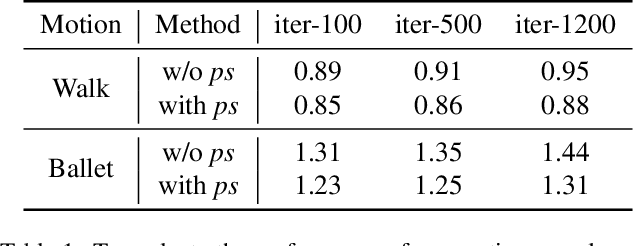
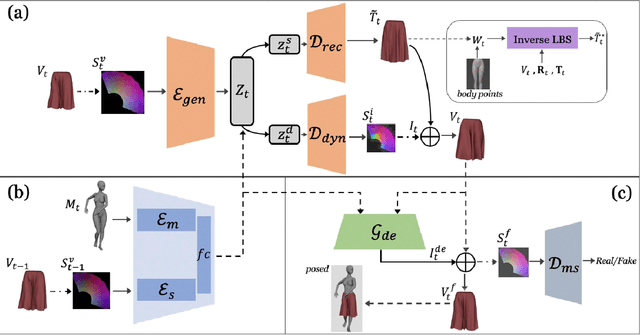
Existing data-driven methods for garment animation, usually driven by linear skinning, although effective on tight garments, do not handle loose-fitting garments with complex deformations well. To address these limitations, we develop a garment generative model based on deformation decomposition to efficiently simulate loose garment deformation without directly using linear skinning. Specifically, we learn a garment generative space with the proposed generative model, where we decouple the latent representation into unposed deformed garments and dynamic offsets during the decoding stage. With explicit garment deformations decomposition, our generative model is able to generate complex pose-driven deformations on canonical garment shapes. Furthermore, we learn to transfer the body motions and previous state of the garment to the latent space to regenerate dynamic results. In addition, we introduce a detail enhancement module in an adversarial training setup to learn high-frequency wrinkles. We demonstrate our method outperforms state-of-the-art data-driven alternatives through extensive experiments and show qualitative and quantitative analysis of results.
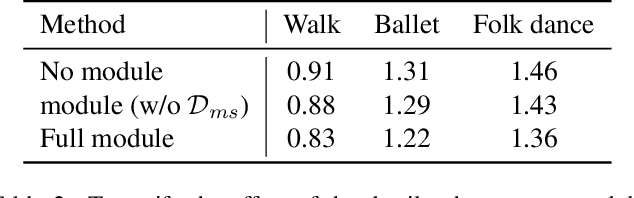
Furthest Reasoning with Plan Assessment: Stable Reasoning Path with Retrieval-Augmented Large Language Models
Sep 22, 2023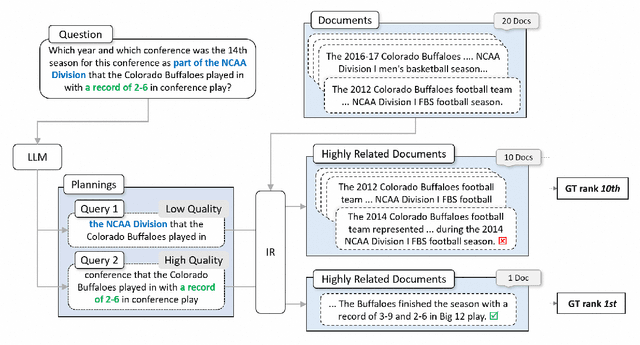
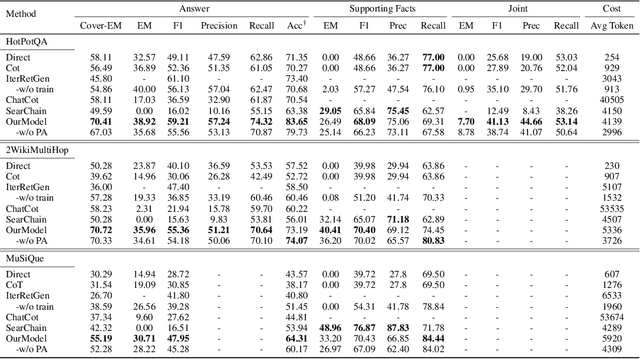
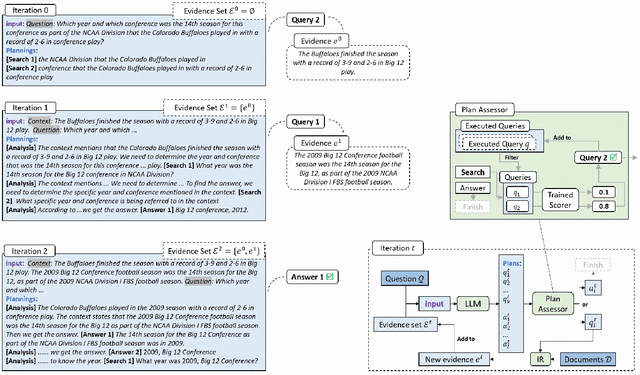
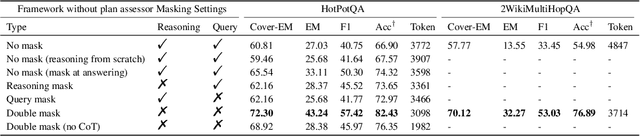
Large Language Models (LLMs), acting as a powerful reasoner and generator, exhibit extraordinary performance across various natural language tasks, such as question answering (QA). Among these tasks, Multi-Hop Question Answering (MHQA) stands as a widely discussed category, necessitating seamless integration between LLMs and the retrieval of external knowledge. Existing methods employ LLM to generate reasoning paths and plans, and utilize IR to iteratively retrieve related knowledge, but these approaches have inherent flaws. On one hand, Information Retriever (IR) is hindered by the low quality of generated queries by LLM. On the other hand, LLM is easily misguided by the irrelevant knowledge by IR. These inaccuracies, accumulated by the iterative interaction between IR and LLM, lead to a disaster in effectiveness at the end. To overcome above barriers, in this paper, we propose a novel pipeline for MHQA called Furthest-Reasoning-with-Plan-Assessment (FuRePA), including an improved framework (Furthest Reasoning) and an attached module (Plan Assessor). 1) Furthest reasoning operates by masking previous reasoning path and generated queries for LLM, encouraging LLM generating chain of thought from scratch in each iteration. This approach enables LLM to break the shackle built by previous misleading thoughts and queries (if any). 2) The Plan Assessor is a trained evaluator that selects an appropriate plan from a group of candidate plans proposed by LLM. Our methods are evaluated on three highly recognized public multi-hop question answering datasets and outperform state-of-the-art on most metrics (achieving a 10%-12% in answer accuracy).
JCDNet: Joint of Common and Definite phases Network for Weakly Supervised Temporal Action Localization
Mar 30, 2023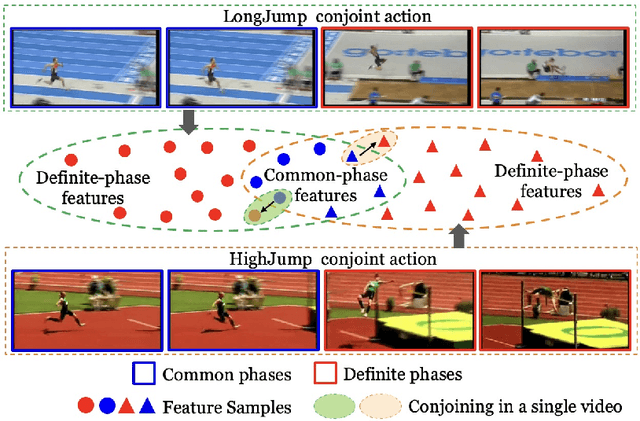
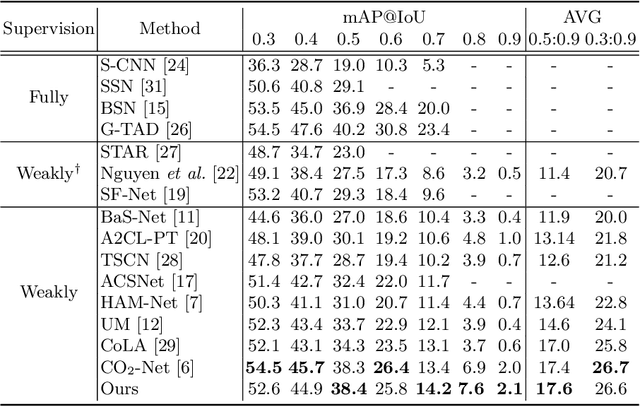
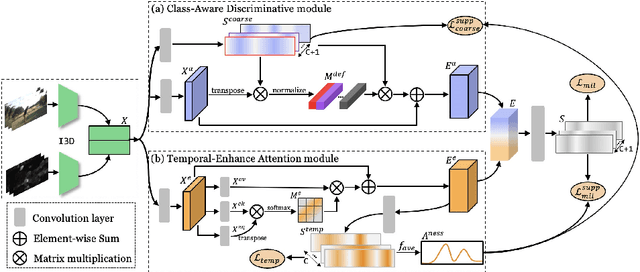
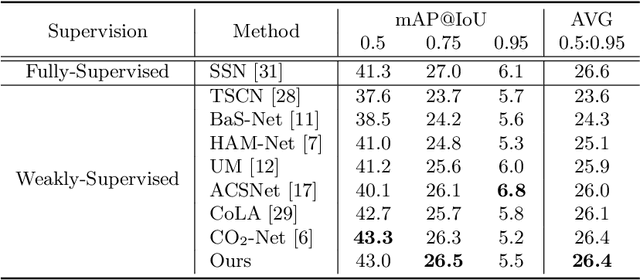
Weakly-supervised temporal action localization aims to localize action instances in untrimmed videos with only video-level supervision. We witness that different actions record common phases, e.g., the run-up in the HighJump and LongJump. These different actions are defined as conjoint actions, whose rest parts are definite phases, e.g., leaping over the bar in a HighJump. Compared with the common phases, the definite phases are more easily localized in existing researches. Most of them formulate this task as a Multiple Instance Learning paradigm, in which the common phases are tended to be confused with the background, and affect the localization completeness of the conjoint actions. To tackle this challenge, we propose a Joint of Common and Definite phases Network (JCDNet) by improving feature discriminability of the conjoint actions. Specifically, we design a Class-Aware Discriminative module to enhance the contribution of the common phases in classification by the guidance of the coarse definite-phase features. Besides, we introduce a temporal attention module to learn robust action-ness scores via modeling temporal dependencies, distinguishing the common phases from the background. Extensive experiments on three datasets (THUMOS14, ActivityNetv1.2, and a conjoint-action subset) demonstrate that JCDNet achieves competitive performance against the state-of-the-art methods. Keywords: weakly-supervised learning, temporal action localization, conjoint action