 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Sleep Staging Leveraging Source-free Unsupervised Domain Adaptation
Dec 11, 2024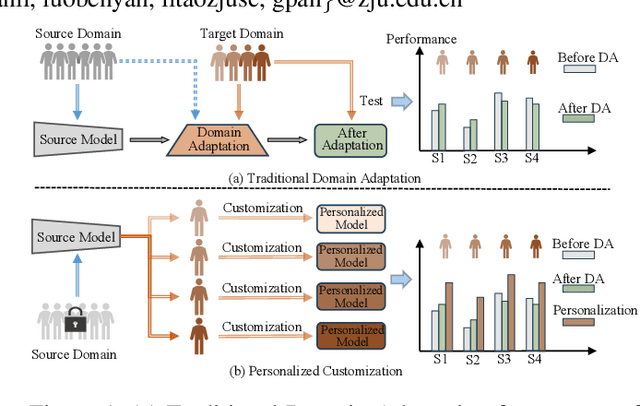



Sleep staging is crucial for assessing sleep quality and diagnosing related disorders. Recent deep learning models for automatic sleep staging using polysomnography often suffer from poor generalization to new subjects because they are trained and tested on the same labeled datasets, overlooking individual differences. To tackle this issue, we propose a novel Source-Free Unsupervised Individual Domain Adaptation (SF-UIDA) framework. This two-step adaptation scheme allows the model to effectively adjust to new unlabeled individuals without needing source data, facilitating personalized customization in clinical settings. Our framework has been applied to three established sleep staging models and tested on three public datasets, achieving state-of-the-art performance.
CBraMod: A Criss-Cross Brain Foundation Model for EEG Decoding
Dec 10, 2024



Electroencephalography (EEG) is a non-invasive technique to measure and record brain electrical activity, widely used in various BCI and healthcare applications. Early EEG decoding methods rely on supervised learning, limited by specific tasks and datasets, hindering model performance and generalizability. With the success of large language models, there is a growing body of studies focusing on EEG foundation models. However, these studies still leave challenges: Firstly, most of existing EEG foundation models employ full EEG modeling strategy. It models the spatial and temporal dependencies between all EEG patches together, but ignores that the spatial and temporal dependencies are heterogeneous due to the unique structural characteristics of EEG signals. Secondly, existing EEG foundation models have limited generalizability on a wide range of downstream BCI tasks due to varying formats of EEG data, making it challenging to adapt to. To address these challenges, we propose a novel foundation model called CBraMod. Specifically, we devise a criss-cross transformer as the backbone to thoroughly leverage the structural characteristics of EEG signals, which can model spatial and temporal dependencies separately through two parallel attention mechanisms. And we utilize an asymmetric conditional positional encoding scheme which can encode positional information of EEG patches and be easily adapted to the EEG with diverse formats. CBraMod is pre-trained on a very large corpus of EEG through patch-based masked EEG reconstruction. We evaluate CBraMod on up to 10 downstream BCI tasks (12 public datasets). CBraMod achieves the state-of-the-art performance across the wide range of tasks, proving its strong capability and generalizability. The source code is publicly available at \url{https://github.com/wjq-learning/CBraMod}.
RpBERT: A Text-image Relation Propagation-based BERT Model for Multimodal NER
Feb 05, 2021

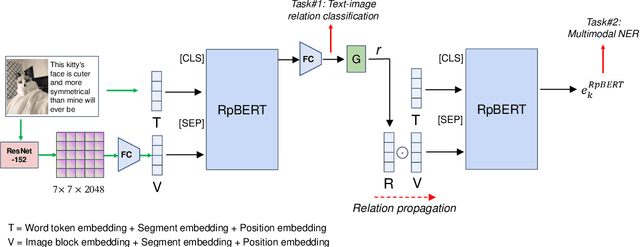

Recently multimodal named entity recognition (MNER) has utilized images to improve the accuracy of NER in tweets. However, most of the multimodal methods use attention mechanisms to extract visual clues regardless of whether the text and image are relevant. Practically, the irrelevant text-image pairs account for a large proportion in tweets. The visual clues that are unrelated to the texts will exert uncertain or even negative effects on multimodal model learning. In this paper, we introduce a method of text-image relation propagation into the multimodal BERT model. We integrate soft or hard gates to select visual clues and propose a multitask algorithm to train on the MNER datasets. In the experiments, we deeply analyze the changes in visual attention before and after the use of text-image relation propagation. Our model achieves state-of-the-art performance on the MNER datasets.