 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: The Current AI Conference Model is Unsustainable! Diagnosing the Crisis of Centralized AI Conference
Aug 06, 2025



Artificial Intelligence (AI) conferences are essential for advancing research, sharing knowledge, and fostering academic community. However, their rapid expansion has rendered the centralized conference model increasingly unsustainable. This paper offers a data-driven diagnosis of a structural crisis that threatens the foundational goals of scientific dissemination, equity, and community well-being. We identify four key areas of strain: (1) scientifically, with per-author publication rates more than doubling over the past decade to over 4.5 papers annually; (2) environmentally, with the carbon footprint of a single conference exceeding the daily emissions of its host city; (3) psychologically, with 71% of online community discourse reflecting negative sentiment and 35% referencing mental health concerns; and (4) logistically, with attendance at top conferences such as NeurIPS 2024 beginning to outpace venue capacity. These pressures point to a system that is misaligned with its core mission. In response, we propose the Community-Federated Conference (CFC) model, which separates peer review, presentation, and networking into globally coordinated but locally organized components, offering a more sustainable, inclusive, and resilient path forward for AI research.
"They've Stolen My GPL-Licensed Model!": Toward Standardized and Transparent Model Licensing
Dec 16, 2024



As model parameter sizes reach the billion-level range and their training consumes zettaFLOPs of computation, components reuse and collaborative development are become increasingly prevalent in the Machine Learning (ML) community. These components, including models, software, and datasets, may originate from various sources and be published under different licenses, which govern the use and distribution of licensed works and their derivatives. However, commonly chosen licenses, such as GPL and Apache, are software-specific and are not clearly defined or bounded in the context of model publishing. Meanwhile, the reused components may also have free-content licenses and model licenses, which pose a potential risk of license noncompliance and rights infringement within the model production workflow. In this paper, we propose addressing the above challenges along two lines: 1) For license analysis, we have developed a new vocabulary for ML workflow management and encoded license rules to enable ontological reasoning for analyzing rights granting and compliance issues. 2) For standardized model publishing, we have drafted a set of model licenses that provide flexible options to meet the diverse needs of model publishing. Our analysis tool is built on Turtle language and Notation3 reasoning engine, envisioned as a first step toward Linked Open Model Production Data. We have also encoded our proposed model licenses into rules and demonstrated the effects of GPL and other commonly used licenses in model publishing, along with the flexibility advantages of our licenses, through comparisons and experiments.
Towards Open Federated Learning Platforms: Survey and Vision from Technical and Legal Perspectives
Jul 05, 2023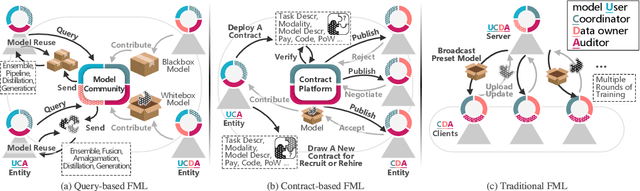
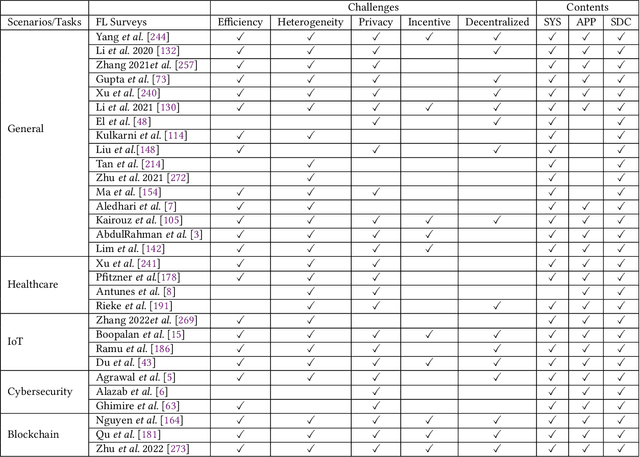
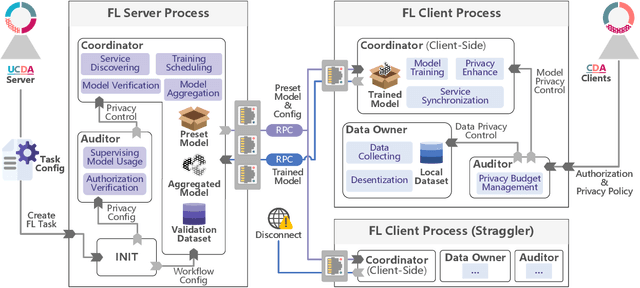

Traditional Federated Learning (FL) follows a server-domincated cooperation paradigm which narrows the application scenarios of FL and decreases the enthusiasm of data holders to participate. To fully unleash the potential of FL, we advocate rethinking the design of current FL frameworks and extending it to a more generalized concept: Open Federated Learning Platforms. We propose two reciprocal cooperation frameworks for FL to achieve this: query-based FL and contract-based FL. In this survey, we conduct a comprehensive review of the feasibility of constructing an open FL platform from both technical and legal perspectives. We begin by reviewing the definition of FL and summarizing its inherent limitations, including server-client coupling, low model reusability, and non-public. In the query-based FL platform, which is an open model sharing and reusing platform empowered by the community for model mining, we explore a wide range of valuable topics, including the availability of up-to-date model repositories for model querying, legal compliance analysis between different model licenses, and copyright issues and intellectual property protection in model reusing. In particular, we introduce a novel taxonomy to streamline the analysis of model license compatibility in FL studies that involve batch model reusing methods, including combination, amalgamation, distillation, and generation. This taxonomy provides a systematic framework for identifying the corresponding clauses of licenses and facilitates the identification of potential legal implications and restrictions when reusing models. Through this survey, we uncover the the current dilemmas faced by FL and advocate for the development of sustainable open FL platforms. We aim to provide guidance for establishing such platforms in the future, while identifying potential problems and challenges that need to be addressed.
Data-Free Diversity-Based Ensemble Selection For One-Shot Federated Learning in Machine Learning Model Market
Feb 23, 2023



The emerging availability of trained machine learning models has put forward the novel concept of Machine Learning Model Market in which one can harness the collective intelligence of multiple well-trained models to improve the performance of the resultant model through one-shot federated learning and ensemble learning in a data-free manner. However, picking the models available in the market for ensemble learning is time-consuming, as using all the models is not always the best approach. It is thus crucial to have an effective ensemble selection strategy that can find a good subset of the base models for the ensemble. Conventional ensemble selection techniques are not applicable, as we do not have access to the local datasets of the parties in the federated learning setting. In this paper, we present a novel Data-Free Diversity-Based method called DeDES to address the ensemble selection problem for models generated by one-shot federated learning in practical applications such as model markets. Experiments showed that our method can achieve both better performance and higher efficiency over 5 datasets and 4 different model structures under the different data-partition strategies.
Flexible Clustered Federated Learning for Client-Level Data Distribution Shift
Aug 22, 2021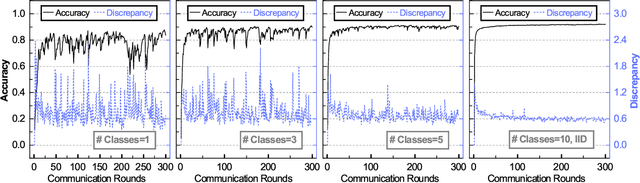
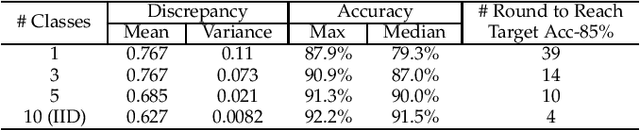
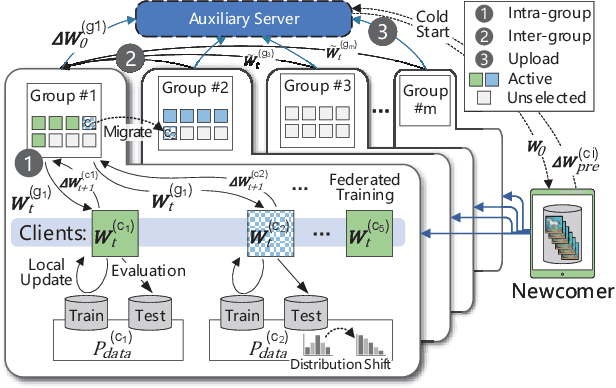
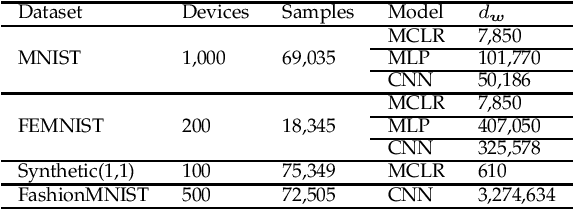
Federated Learning (FL) enables the multiple participating devices to collaboratively contribute to a global neural network model while keeping the training data locally. Unlike the centralized training setting, the non-IID, imbalanced (statistical heterogeneity) and distribution shifted training data of FL is distributed in the federated network, which will increase the divergences between the local models and the global model, further degrading performance. In this paper, we propose a flexible clustered federated learning (CFL) framework named FlexCFL, in which we 1) group the training of clients based on the similarities between the clients' optimization directions for lower training divergence; 2) implement an efficient newcomer device cold start mechanism for framework scalability and practicality; 3) flexibly migrate clients to meet the challenge of client-level data distribution shift. FlexCFL can achieve improvements by dividing joint optimization into groups of sub-optimization and can strike a balance between accuracy and communication efficiency in the distribution shift environment. The convergence and complexity are analyzed to demonstrate the efficiency of FlexCFL. We also evaluate FlexCFL on several open datasets and made comparisons with related CFL frameworks. The results show that FlexCFL can significantly improve absolute test accuracy by +10.6% on FEMNIST compared to FedAvg, +3.5% on FashionMNIST compared to FedProx, +8.4% on MNIST compared to FeSEM. The experiment results show that FlexCFL is also communication efficient in the distribution shift environment.
CSAFL: A Clustered Semi-Asynchronous Federated Learning Framework
Apr 16, 2021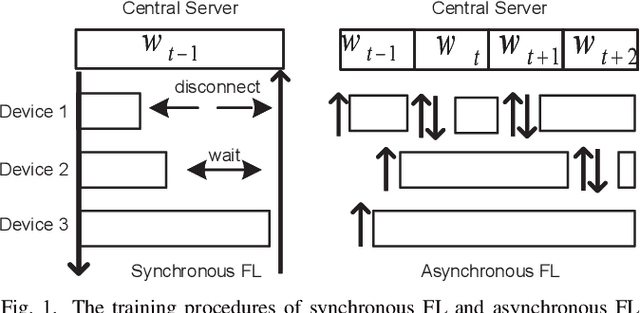
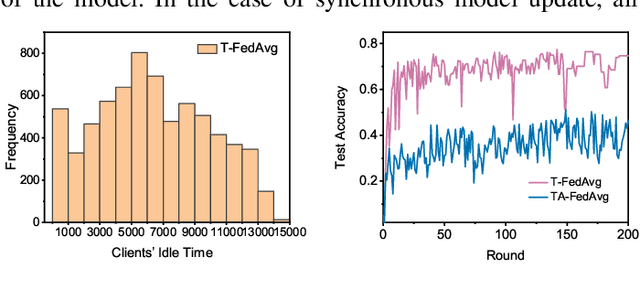
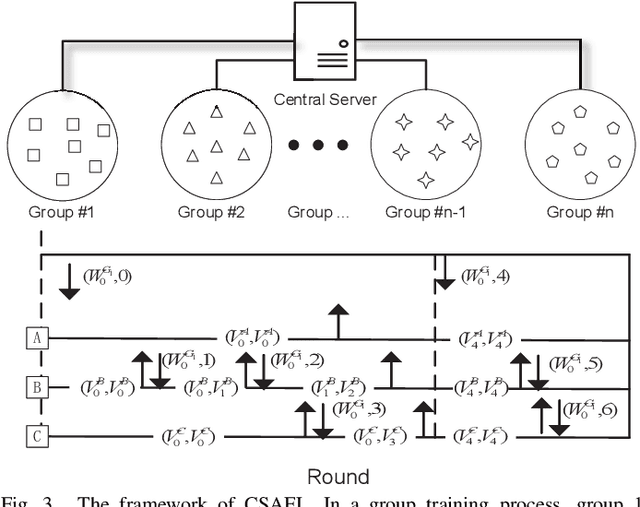
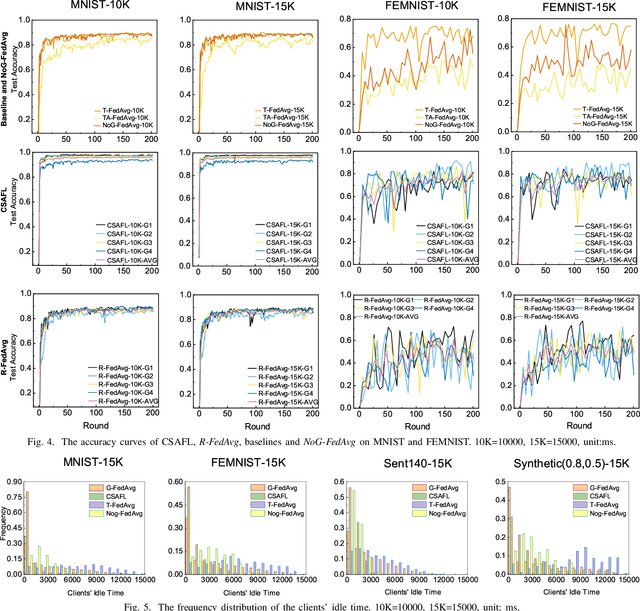
Federated learning (FL) is an emerging distributed machine learning paradigm that protects privacy and tackles the problem of isolated data islands. At present, there are two main communication strategies of FL: synchronous FL and asynchronous FL. The advantages of synchronous FL are that the model has high precision and fast convergence speed. However, this synchronous communication strategy has the risk that the central server waits too long for the devices, namely, the straggler effect which has a negative impact on some time-critical applications. Asynchronous FL has a natural advantage in mitigating the straggler effect, but there are threats of model quality degradation and server crash. Therefore, we combine the advantages of these two strategies to propose a clustered semi-asynchronous federated learning (CSAFL) framework. We evaluate CSAFL based on four imbalanced federated datasets in a non-IID setting and compare CSAFL to the baseline methods. The experimental results show that CSAFL significantly improves test accuracy by more than +5% on the four datasets compared to TA-FedAvg. In particular, CSAFL improves absolute test accuracy by +34.4% on non-IID FEMNIST compared to TA-FedAvg.
FedSAE: A Novel Self-Adaptive Federated Learning Framework in Heterogeneous Systems
Apr 15, 2021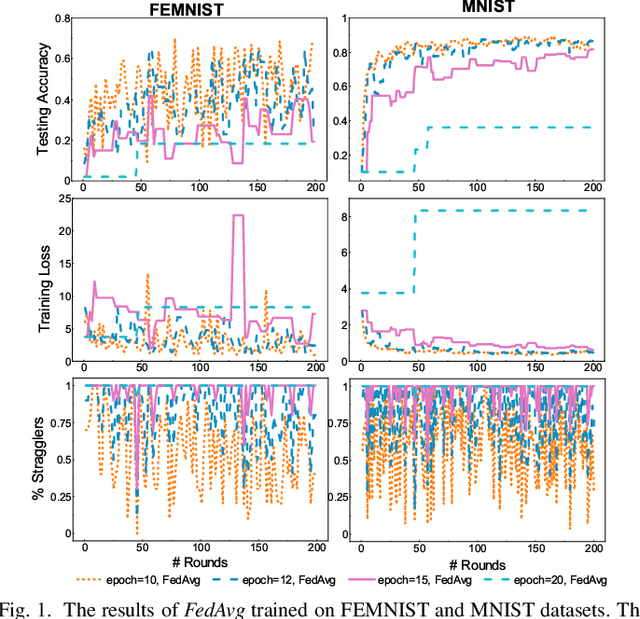
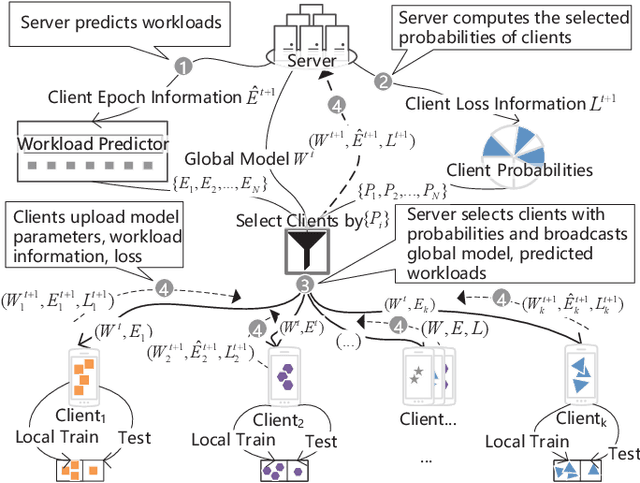
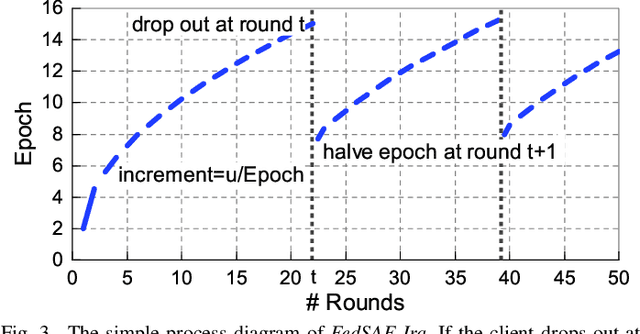
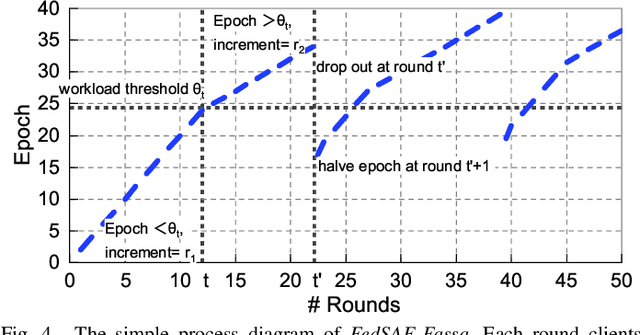
Federated Learning (FL) is a novel distributed machine learning which allows thousands of edge devices to train model locally without uploading data concentrically to the server. But since real federated settings are resource-constrained, FL is encountered with systems heterogeneity which causes a lot of stragglers directly and then leads to significantly accuracy reduction indirectly. To solve the problems caused by systems heterogeneity, we introduce a novel self-adaptive federated framework FedSAE which adjusts the training task of devices automatically and selects participants actively to alleviate the performance degradation. In this work, we 1) propose FedSAE which leverages the complete information of devices' historical training tasks to predict the affordable training workloads for each device. In this way, FedSAE can estimate the reliability of each device and self-adaptively adjust the amount of training load per client in each round. 2) combine our framework with Active Learning to self-adaptively select participants. Then the framework accelerates the convergence of the global model. In our framework, the server evaluates devices' value of training based on their training loss. Then the server selects those clients with bigger value for the global model to reduce communication overhead. The experimental result indicates that in a highly heterogeneous system, FedSAE converges faster than FedAvg, the vanilla FL framework. Furthermore, FedSAE outperforms than FedAvg on several federated datasets - FedSAE improves test accuracy by 26.7% and reduces stragglers by 90.3% on average.
FedGroup: Ternary Cosine Similarity-based Clustered Federated Learning Framework toward High Accuracy in Heterogeneous Data
Oct 15, 2020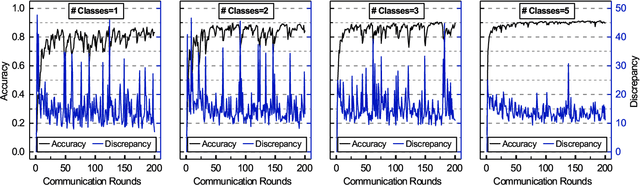
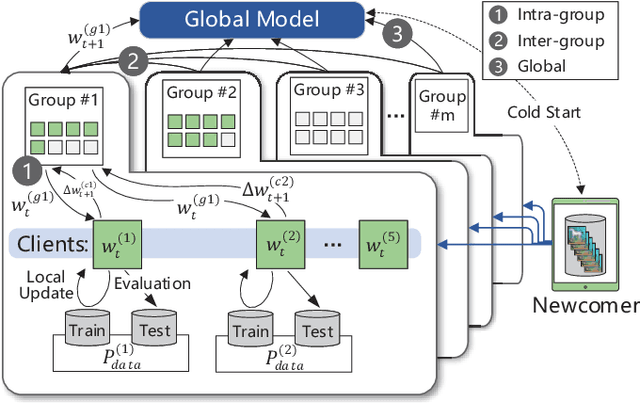
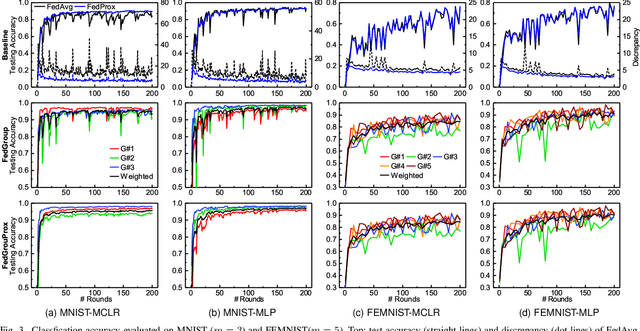
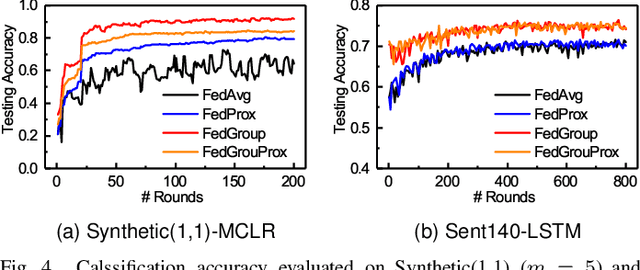
Federated Learning (FL) enables the multiple participating devices to collaboratively contribute to a global neural network model while keeping the training data locally. Unlike the centralized training setting, the non-IID and imbalanced (statistical heterogeneity) training data of FL is distributed in the federated network, which will increase the divergences between the local models and global model and further degrade the performance. In this paper, we propose a novel federated learning framework FedGroup based on a similarity-based clustering strategy, in which we 1) group the training of clients based on the similarities between the clients' optimize directions; 2) reduce the complexity of high-dimension low-sample size (HDLSS) parameter updates data clustering by decomposing the direction vectors to derive the ternary cosine similarity. FedGroup can achieve improvements by dividing joint optimization into groups of sub-optimization, and can be combined with FedProx, the state-of-the-art federated optimization algorithm. We evaluate FedGroup and FedGrouProx (combined with FedProx) on several open datasets. The experimental results show that our proposed frameworks significantly improving absolute test accuracy by +14.7% on FEMNIST compared to FedAvg, +5.4% on Sentiment140 compared to FedProx.
Astraea: Self-balancing Federated Learning for Improving Classification Accuracy of Mobile Deep Learning Applications
Jul 02, 2019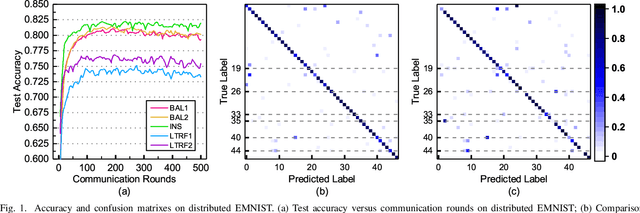
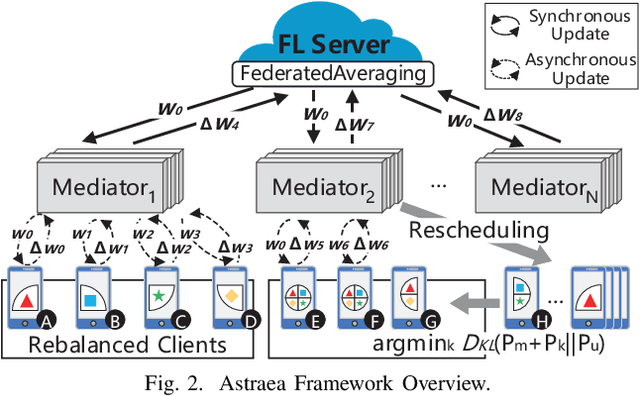
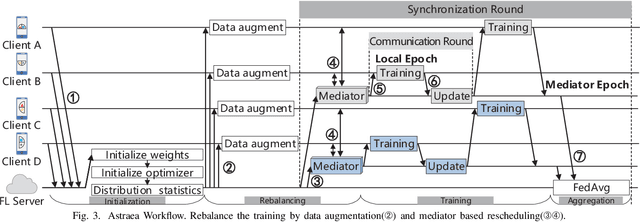
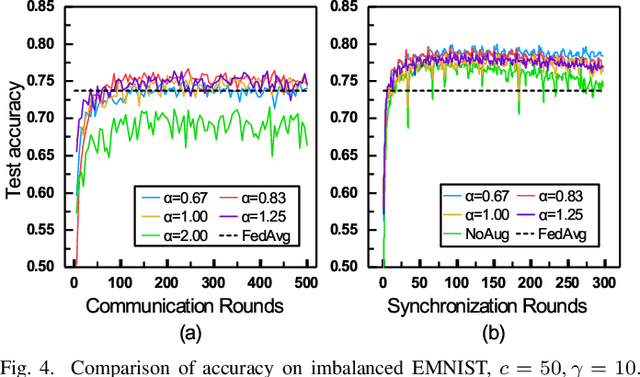
Federated learning (FL) is a distributed deep learning method which enables multiple participants, such as mobile phones and IoT devices, to contribute a neural network model while their private training data remains in local devices. This distributed approach is promising in the edge computing system where have a large corpus of decentralized data and require high privacy. However, unlike the common training dataset, the data distribution of the edge computing system is imbalanced which will introduce biases in the model training and cause a decrease in accuracy of federated learning applications. In this paper, we demonstrate that the imbalanced distributed training data will cause accuracy degradation in FL. To counter this problem, we build a self-balancing federated learning framework call Astraea, which alleviates the imbalances by 1) Global data distribution based data augmentation, and 2) Mediator based multi-client rescheduling. Compared with FedAvg, the state-of-the-art FL algorithm, Astraea shows +5.59% and +5.89% improvement of top-1 accuracy on the imbalanced EMNIST and imbalanced CINIC-10 datasets, respectively. Meanwhile, the communication traffic of Astraea can be 92% lower than that of FedAvg.