 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstraea: Self-balancing Federated Learning for Improving Classification Accuracy of Mobile Deep Learning Applications
Paper and Code
Jul 02, 2019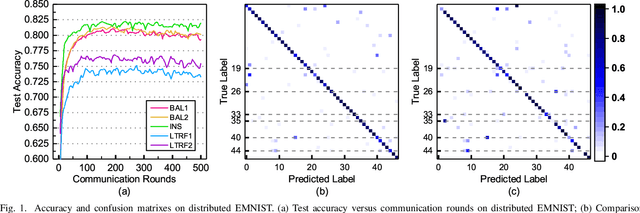
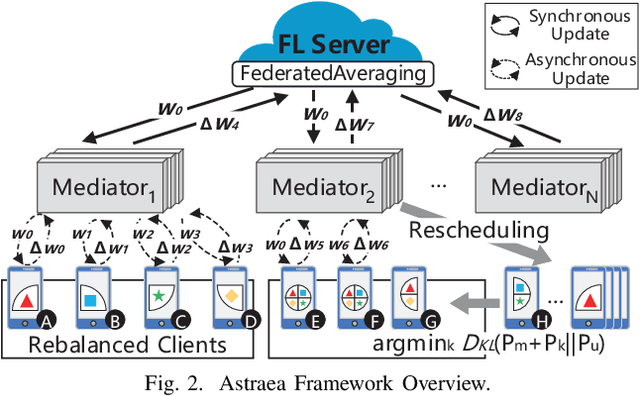
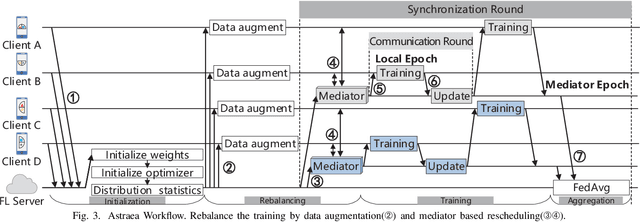
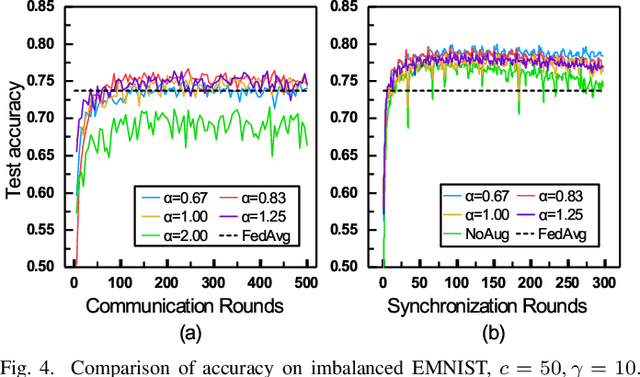
Federated learning (FL) is a distributed deep learning method which enables multiple participants, such as mobile phones and IoT devices, to contribute a neural network model while their private training data remains in local devices. This distributed approach is promising in the edge computing system where have a large corpus of decentralized data and require high privacy. However, unlike the common training dataset, the data distribution of the edge computing system is imbalanced which will introduce biases in the model training and cause a decrease in accuracy of federated learning applications. In this paper, we demonstrate that the imbalanced distributed training data will cause accuracy degradation in FL. To counter this problem, we build a self-balancing federated learning framework call Astraea, which alleviates the imbalances by 1) Global data distribution based data augmentation, and 2) Mediator based multi-client rescheduling. Compared with FedAvg, the state-of-the-art FL algorithm, Astraea shows +5.59% and +5.89% improvement of top-1 accuracy on the imbalanced EMNIST and imbalanced CINIC-10 datasets, respectively. Meanwhile, the communication traffic of Astraea can be 92% lower than that of FedAvg.