 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Visual Saliency in Continuous Spike Stream
Mar 10, 2024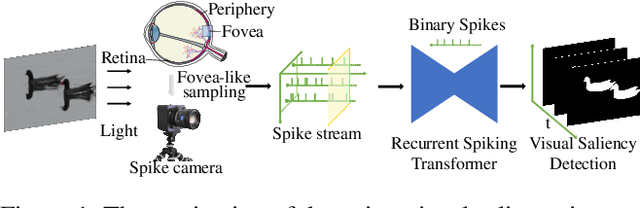



As a bio-inspired vision sensor, the spike camera emulates the operational principles of the fovea, a compact retinal region, by employing spike discharges to encode the accumulation of per-pixel luminance intensity. Leveraging its high temporal resolution and bio-inspired neuromorphic design, the spike camera holds significant promise for advancing computer vision applications. Saliency detection mimics the behavior of human beings and captures the most salient region from the scenes. In this paper, we investigate the visual saliency in the continuous spike stream for the first time. To effectively process the binary spike stream, we propose a Recurrent Spiking Transformer (RST) framework, which is based on a full spiking neural network. Our framework enables the extraction of spatio-temporal features from the continuous spatio-temporal spike stream while maintaining low power consumption. To facilitate the training and validation of our proposed model, we build a comprehensive real-world spike-based visual saliency dataset, enriched with numerous light conditions. Extensive experiments demonstrate the superior performance of our Recurrent Spiking Transformer framework in comparison to other spike neural network-based methods. Our framework exhibits a substantial margin of improvement in capturing and highlighting visual saliency in the spike stream, which not only provides a new perspective for spike-based saliency segmentation but also shows a new paradigm for full SNN-based transformer models. The code and dataset are available at \url{https://github.com/BIT-Vision/SVS}.
Flexible Clustered Federated Learning for Client-Level Data Distribution Shift
Aug 22, 2021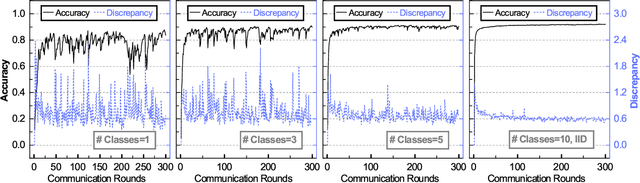
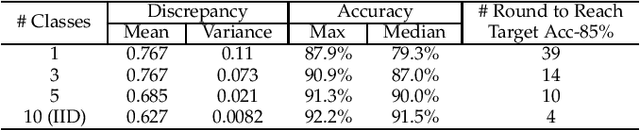
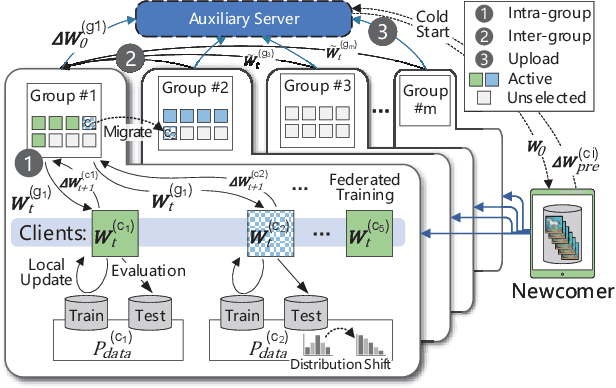
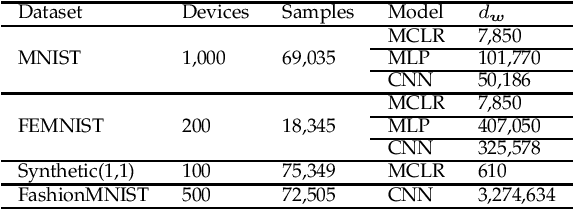
Federated Learning (FL) enables the multiple participating devices to collaboratively contribute to a global neural network model while keeping the training data locally. Unlike the centralized training setting, the non-IID, imbalanced (statistical heterogeneity) and distribution shifted training data of FL is distributed in the federated network, which will increase the divergences between the local models and the global model, further degrading performance. In this paper, we propose a flexible clustered federated learning (CFL) framework named FlexCFL, in which we 1) group the training of clients based on the similarities between the clients' optimization directions for lower training divergence; 2) implement an efficient newcomer device cold start mechanism for framework scalability and practicality; 3) flexibly migrate clients to meet the challenge of client-level data distribution shift. FlexCFL can achieve improvements by dividing joint optimization into groups of sub-optimization and can strike a balance between accuracy and communication efficiency in the distribution shift environment. The convergence and complexity are analyzed to demonstrate the efficiency of FlexCFL. We also evaluate FlexCFL on several open datasets and made comparisons with related CFL frameworks. The results show that FlexCFL can significantly improve absolute test accuracy by +10.6% on FEMNIST compared to FedAvg, +3.5% on FashionMNIST compared to FedProx, +8.4% on MNIST compared to FeSEM. The experiment results show that FlexCFL is also communication efficient in the distribution shift environment.
CSAFL: A Clustered Semi-Asynchronous Federated Learning Framework
Apr 16, 2021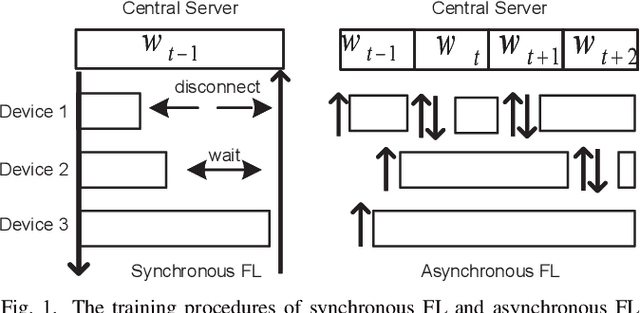
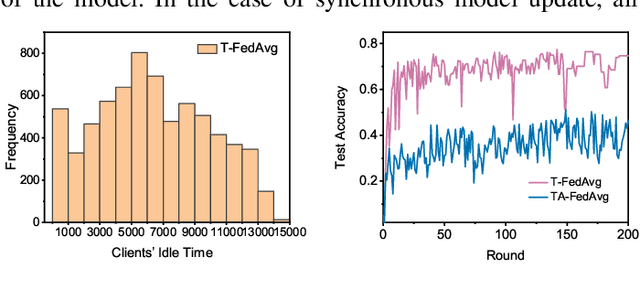
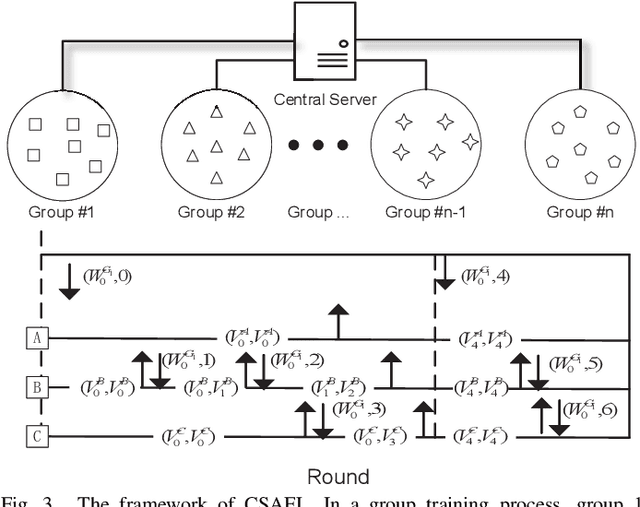
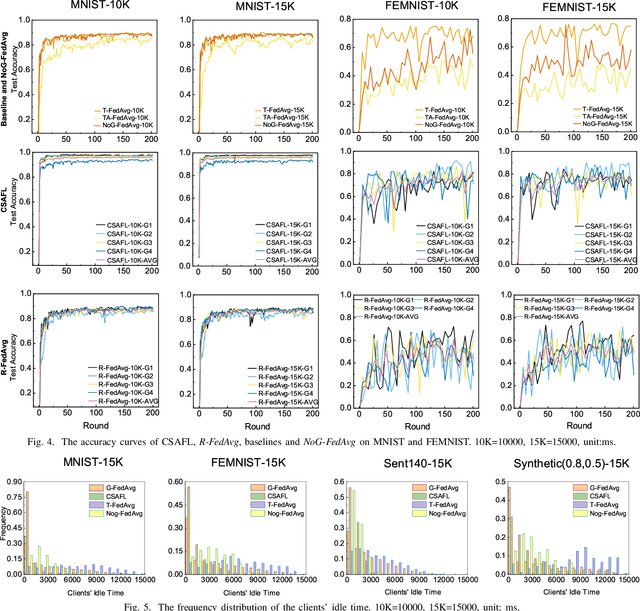
Federated learning (FL) is an emerging distributed machine learning paradigm that protects privacy and tackles the problem of isolated data islands. At present, there are two main communication strategies of FL: synchronous FL and asynchronous FL. The advantages of synchronous FL are that the model has high precision and fast convergence speed. However, this synchronous communication strategy has the risk that the central server waits too long for the devices, namely, the straggler effect which has a negative impact on some time-critical applications. Asynchronous FL has a natural advantage in mitigating the straggler effect, but there are threats of model quality degradation and server crash. Therefore, we combine the advantages of these two strategies to propose a clustered semi-asynchronous federated learning (CSAFL) framework. We evaluate CSAFL based on four imbalanced federated datasets in a non-IID setting and compare CSAFL to the baseline methods. The experimental results show that CSAFL significantly improves test accuracy by more than +5% on the four datasets compared to TA-FedAvg. In particular, CSAFL improves absolute test accuracy by +34.4% on non-IID FEMNIST compared to TA-FedAvg.
FedSAE: A Novel Self-Adaptive Federated Learning Framework in Heterogeneous Systems
Apr 15, 2021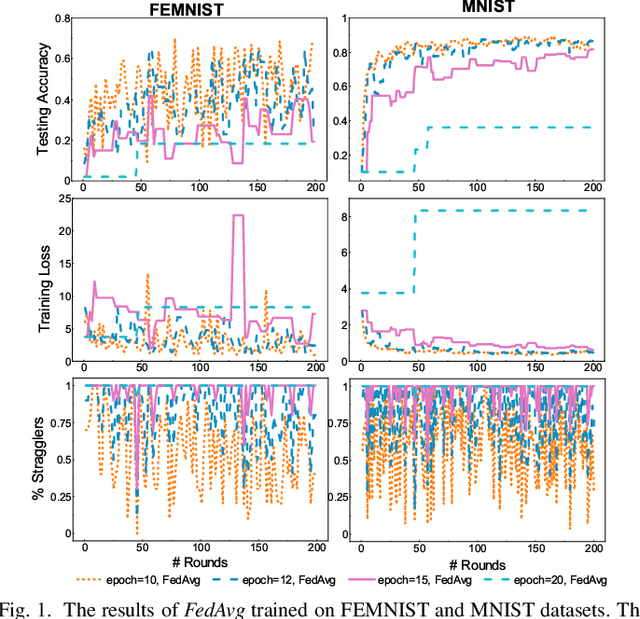
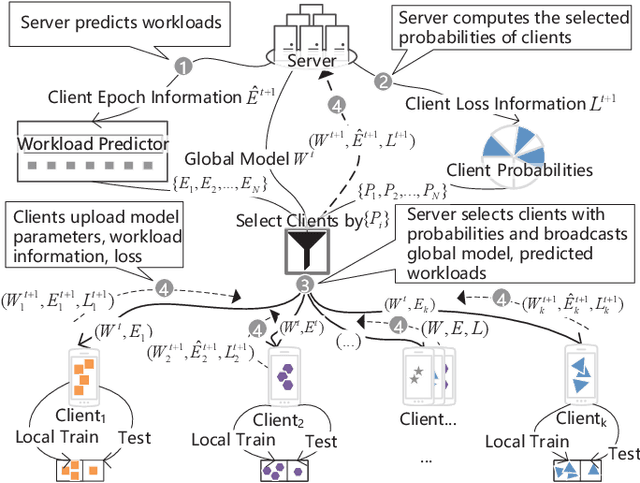
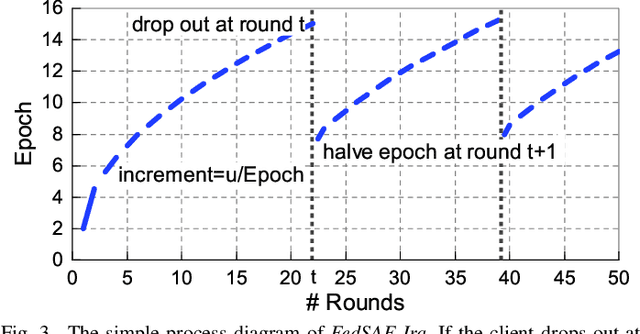
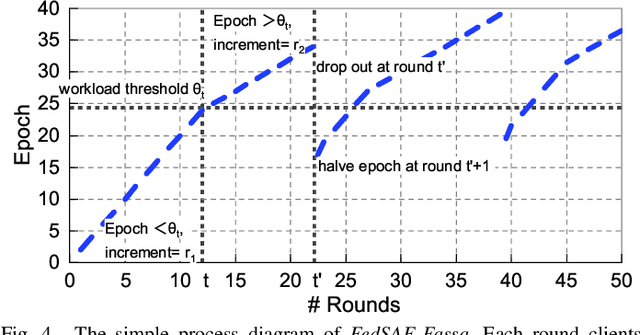
Federated Learning (FL) is a novel distributed machine learning which allows thousands of edge devices to train model locally without uploading data concentrically to the server. But since real federated settings are resource-constrained, FL is encountered with systems heterogeneity which causes a lot of stragglers directly and then leads to significantly accuracy reduction indirectly. To solve the problems caused by systems heterogeneity, we introduce a novel self-adaptive federated framework FedSAE which adjusts the training task of devices automatically and selects participants actively to alleviate the performance degradation. In this work, we 1) propose FedSAE which leverages the complete information of devices' historical training tasks to predict the affordable training workloads for each device. In this way, FedSAE can estimate the reliability of each device and self-adaptively adjust the amount of training load per client in each round. 2) combine our framework with Active Learning to self-adaptively select participants. Then the framework accelerates the convergence of the global model. In our framework, the server evaluates devices' value of training based on their training loss. Then the server selects those clients with bigger value for the global model to reduce communication overhead. The experimental result indicates that in a highly heterogeneous system, FedSAE converges faster than FedAvg, the vanilla FL framework. Furthermore, FedSAE outperforms than FedAvg on several federated datasets - FedSAE improves test accuracy by 26.7% and reduces stragglers by 90.3% on average.
FedGroup: Ternary Cosine Similarity-based Clustered Federated Learning Framework toward High Accuracy in Heterogeneous Data
Oct 15, 2020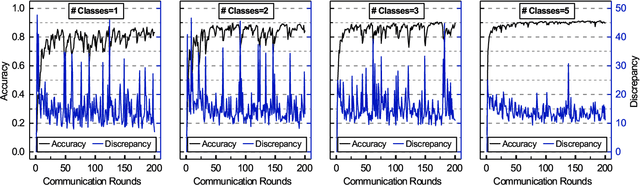
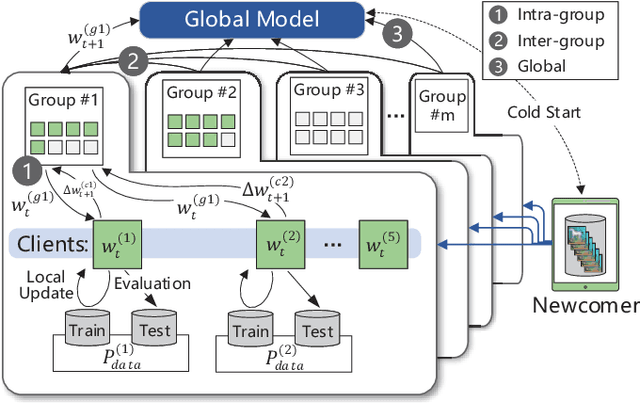
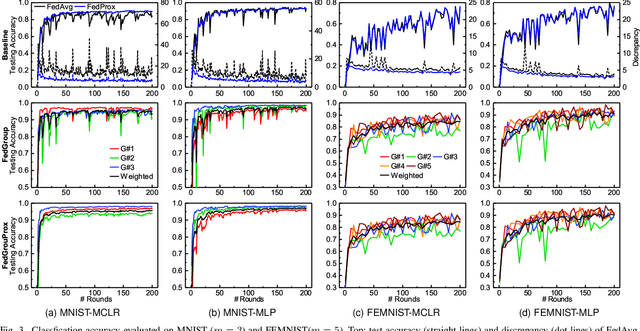
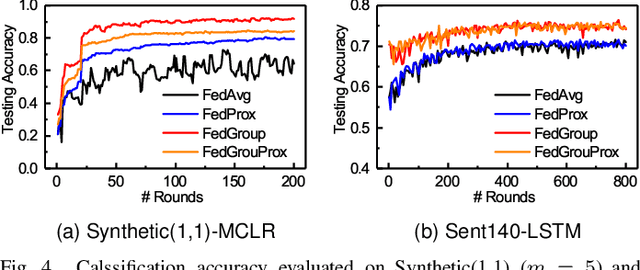
Federated Learning (FL) enables the multiple participating devices to collaboratively contribute to a global neural network model while keeping the training data locally. Unlike the centralized training setting, the non-IID and imbalanced (statistical heterogeneity) training data of FL is distributed in the federated network, which will increase the divergences between the local models and global model and further degrade the performance. In this paper, we propose a novel federated learning framework FedGroup based on a similarity-based clustering strategy, in which we 1) group the training of clients based on the similarities between the clients' optimize directions; 2) reduce the complexity of high-dimension low-sample size (HDLSS) parameter updates data clustering by decomposing the direction vectors to derive the ternary cosine similarity. FedGroup can achieve improvements by dividing joint optimization into groups of sub-optimization, and can be combined with FedProx, the state-of-the-art federated optimization algorithm. We evaluate FedGroup and FedGrouProx (combined with FedProx) on several open datasets. The experimental results show that our proposed frameworks significantly improving absolute test accuracy by +14.7% on FEMNIST compared to FedAvg, +5.4% on Sentiment140 compared to FedProx.