 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$D^2Prune$: Sparsifying Large Language Models via Dual Taylor Expansion and Attention Distribution Awareness
Jan 14, 2026Large language models (LLMs) face significant deployment challenges due to their massive computational demands. % While pruning offers a promising compression solution, existing methods suffer from two critical limitations: (1) They neglect activation distribution shifts between calibration data and test data, resulting in inaccurate error estimations; (2) They overlook the long-tail distribution characteristics of activations in the attention module. To address these limitations, this paper proposes a novel pruning method, $D^2Prune$. First, we propose a dual Taylor expansion-based method that jointly models weight and activation perturbations for precise error estimation, leading to precise pruning mask selection and weight updating and facilitating error minimization during pruning. % Second, we propose an attention-aware dynamic update strategy that preserves the long-tail attention pattern by jointly minimizing the KL divergence of attention distributions and the reconstruction error. Extensive experiments show that $D^2Prune$ consistently outperforms SOTA methods across various LLMs (e.g., OPT-125M, LLaMA2/3, and Qwen3). Moreover, the dynamic attention update mechanism also generalizes well to ViT-based vision models like DeiT, achieving superior accuracy on ImageNet-1K.
Improving DNN Fault Tolerance using Weight Pruning and Differential Crossbar Mapping for ReRAM-based Edge AI
Jun 18, 2021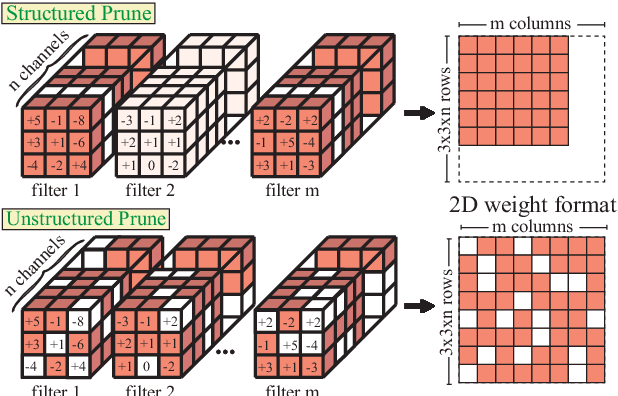
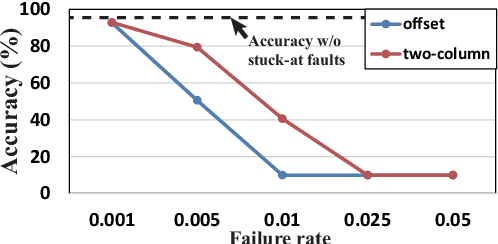
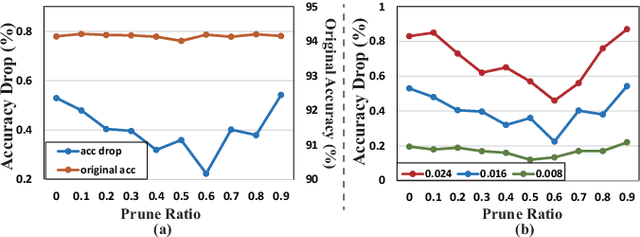
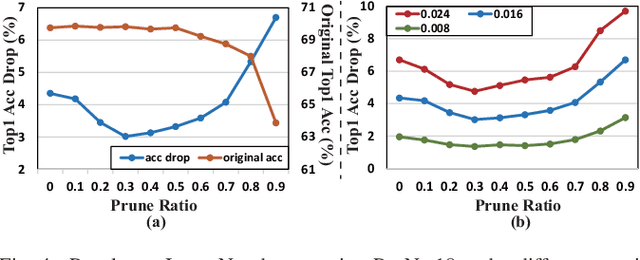
Recent research demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in deep neural networks (DNNs). However, hardware failure, such as stuck-at-fault defects, is one of the main concerns that impedes the ReRAM devices to be a feasible solution for real implementations. The existing solutions to address this issue usually require an optimization to be conducted for each individual device, which is impractical for mass-produced products (e.g., IoT devices). In this paper, we rethink the value of weight pruning in ReRAM-based DNN design from the perspective of model fault tolerance. And a differential mapping scheme is proposed to improve the fault tolerance under a high stuck-on fault rate. Our method can tolerate almost an order of magnitude higher failure rate than the traditional two-column method in representative DNN tasks. More importantly, our method does not require extra hardware cost compared to the traditional two-column mapping scheme. The improvement is universal and does not require the optimization process for each individual device.
CSAFL: A Clustered Semi-Asynchronous Federated Learning Framework
Apr 16, 2021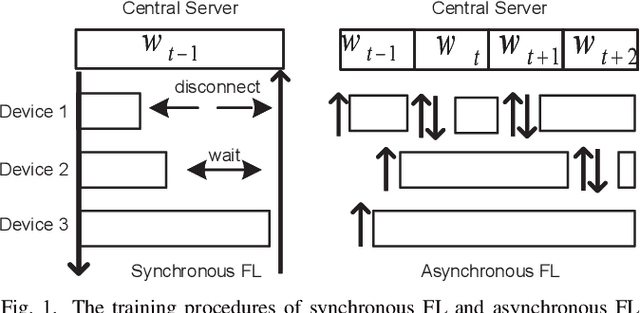
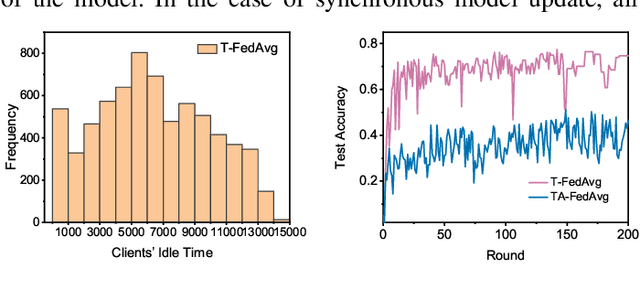
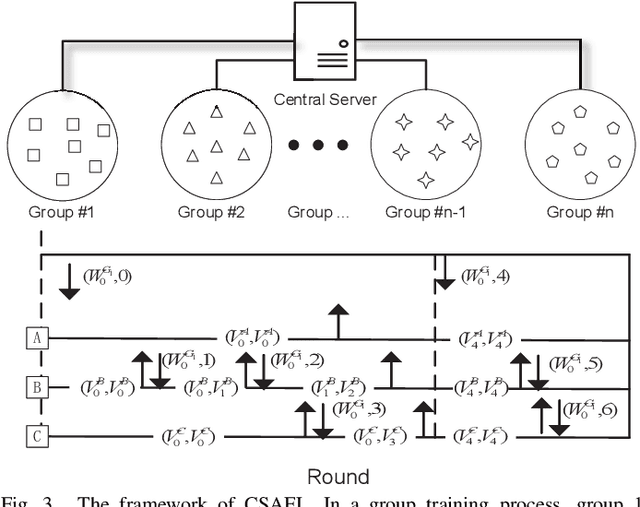
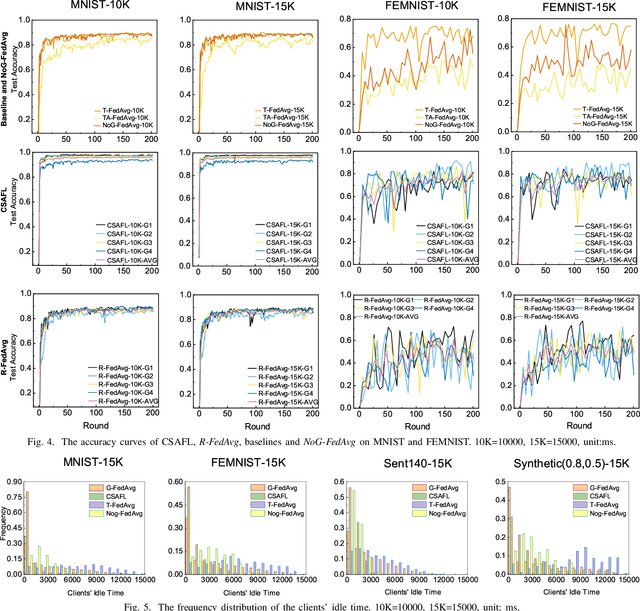
Federated learning (FL) is an emerging distributed machine learning paradigm that protects privacy and tackles the problem of isolated data islands. At present, there are two main communication strategies of FL: synchronous FL and asynchronous FL. The advantages of synchronous FL are that the model has high precision and fast convergence speed. However, this synchronous communication strategy has the risk that the central server waits too long for the devices, namely, the straggler effect which has a negative impact on some time-critical applications. Asynchronous FL has a natural advantage in mitigating the straggler effect, but there are threats of model quality degradation and server crash. Therefore, we combine the advantages of these two strategies to propose a clustered semi-asynchronous federated learning (CSAFL) framework. We evaluate CSAFL based on four imbalanced federated datasets in a non-IID setting and compare CSAFL to the baseline methods. The experimental results show that CSAFL significantly improves test accuracy by more than +5% on the four datasets compared to TA-FedAvg. In particular, CSAFL improves absolute test accuracy by +34.4% on non-IID FEMNIST compared to TA-FedAvg.
FedSAE: A Novel Self-Adaptive Federated Learning Framework in Heterogeneous Systems
Apr 15, 2021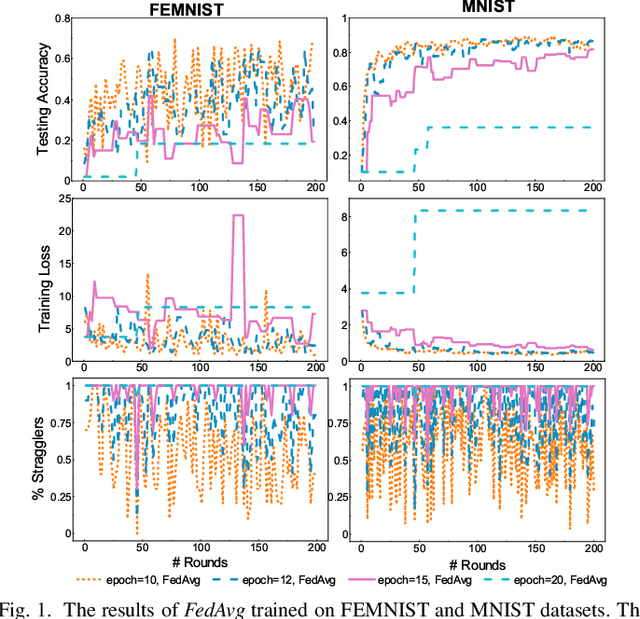
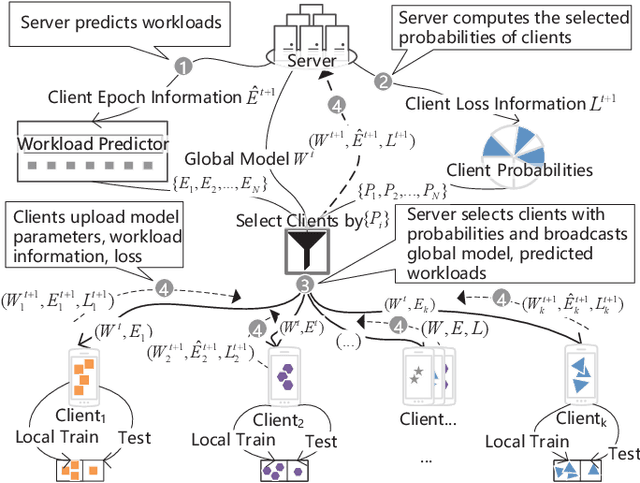
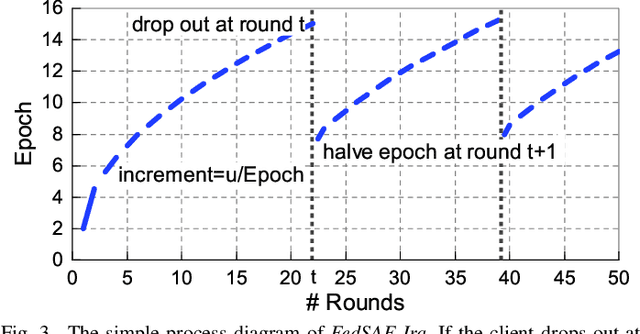
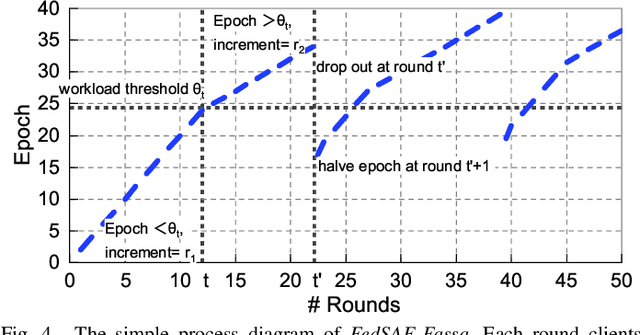
Federated Learning (FL) is a novel distributed machine learning which allows thousands of edge devices to train model locally without uploading data concentrically to the server. But since real federated settings are resource-constrained, FL is encountered with systems heterogeneity which causes a lot of stragglers directly and then leads to significantly accuracy reduction indirectly. To solve the problems caused by systems heterogeneity, we introduce a novel self-adaptive federated framework FedSAE which adjusts the training task of devices automatically and selects participants actively to alleviate the performance degradation. In this work, we 1) propose FedSAE which leverages the complete information of devices' historical training tasks to predict the affordable training workloads for each device. In this way, FedSAE can estimate the reliability of each device and self-adaptively adjust the amount of training load per client in each round. 2) combine our framework with Active Learning to self-adaptively select participants. Then the framework accelerates the convergence of the global model. In our framework, the server evaluates devices' value of training based on their training loss. Then the server selects those clients with bigger value for the global model to reduce communication overhead. The experimental result indicates that in a highly heterogeneous system, FedSAE converges faster than FedAvg, the vanilla FL framework. Furthermore, FedSAE outperforms than FedAvg on several federated datasets - FedSAE improves test accuracy by 26.7% and reduces stragglers by 90.3% on average.
DARB: A Density-Aware Regular-Block Pruning for Deep Neural Networks
Nov 20, 2019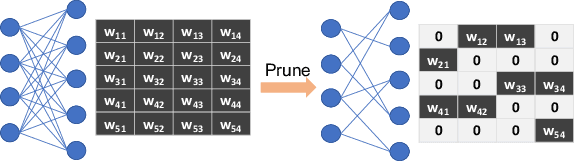
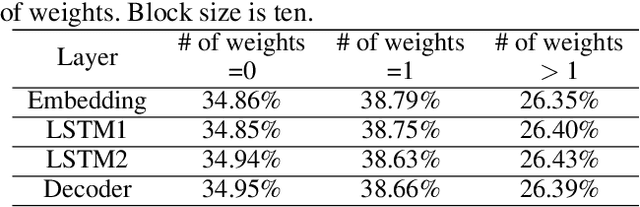
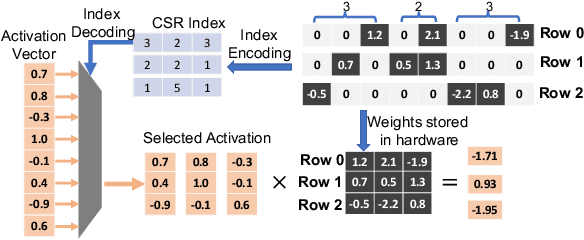
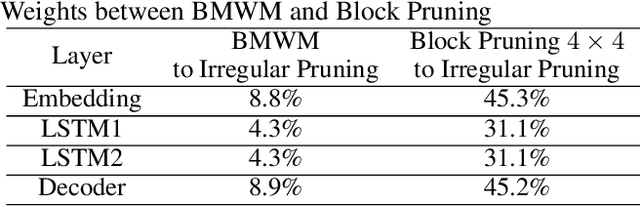
The rapidly growing parameter volume of deep neural networks (DNNs) hinders the artificial intelligence applications on resource constrained devices, such as mobile and wearable devices. Neural network pruning, as one of the mainstream model compression techniques, is under extensive study to reduce the number of parameters and computations. In contrast to irregular pruning that incurs high index storage and decoding overhead, structured pruning techniques have been proposed as the promising solutions. However, prior studies on structured pruning tackle the problem mainly from the perspective of facilitating hardware implementation, without analyzing the characteristics of sparse neural networks. The neglect on the study of sparse neural networks causes inefficient trade-off between regularity and pruning ratio. Consequently, the potential of structurally pruning neural networks is not sufficiently mined. In this work, we examine the structural characteristics of the irregularly pruned weight matrices, such as the diverse redundancy of different rows, the sensitivity of different rows to pruning, and the positional characteristics of retained weights. By leveraging the gained insights as a guidance, we first propose the novel block-max weight masking (BMWM) method, which can effectively retain the salient weights while imposing high regularity to the weight matrix. As a further optimization, we propose a density-adaptive regular-block (DARB) pruning that outperforms prior structured pruning work with high pruning ratio and decoding efficiency. Our experimental results show that DARB can achieve 13$\times$ to 25$\times$ pruning ratio, which are 2.8$\times$ to 4.3$\times$ improvements than the state-of-the-art counterparts on multiple neural network models and tasks. Moreover, DARB can achieve 14.3$\times$ decoding efficiency than block pruning with higher pruning ratio.
A Stochastic-Computing based Deep Learning Framework using Adiabatic Quantum-Flux-Parametron SuperconductingTechnology
Jul 22, 2019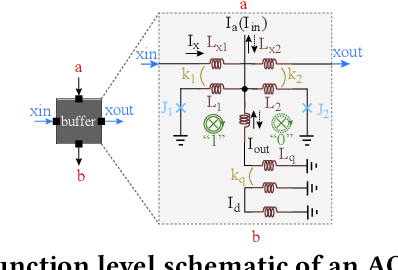
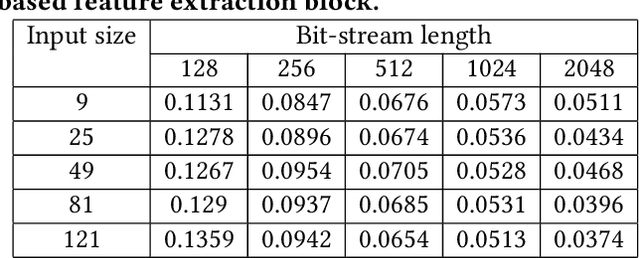
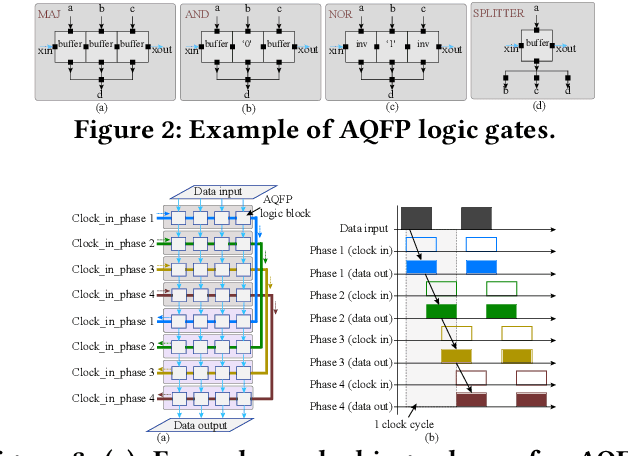
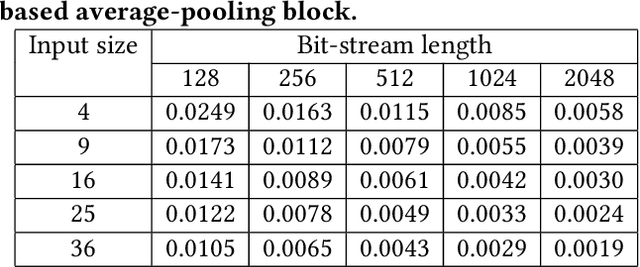
The Adiabatic Quantum-Flux-Parametron (AQFP) superconducting technology has been recently developed, which achieves the highest energy efficiency among superconducting logic families, potentially huge gain compared with state-of-the-art CMOS. In 2016, the successful fabrication and testing of AQFP-based circuits with the scale of 83,000 JJs have demonstrated the scalability and potential of implementing large-scale systems using AQFP. As a result, it will be promising for AQFP in high-performance computing and deep space applications, with Deep Neural Network (DNN) inference acceleration as an important example. Besides ultra-high energy efficiency, AQFP exhibits two unique characteristics: the deep pipelining nature since each AQFP logic gate is connected with an AC clock signal, which increases the difficulty to avoid RAW hazards; the second is the unique opportunity of true random number generation (RNG) using a single AQFP buffer, far more efficient than RNG in CMOS. We point out that these two characteristics make AQFP especially compatible with the \emph{stochastic computing} (SC) technique, which uses a time-independent bit sequence for value representation, and is compatible with the deep pipelining nature. Further, the application of SC has been investigated in DNNs in prior work, and the suitability has been illustrated as SC is more compatible with approximate computations. This work is the first to develop an SC-based DNN acceleration framework using AQFP technology.
ADMM-NN: An Algorithm-Hardware Co-Design Framework of DNNs Using Alternating Direction Method of Multipliers
Dec 31, 2018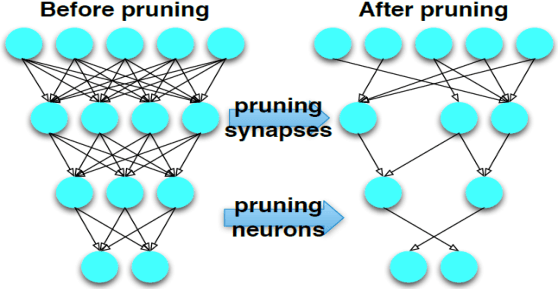
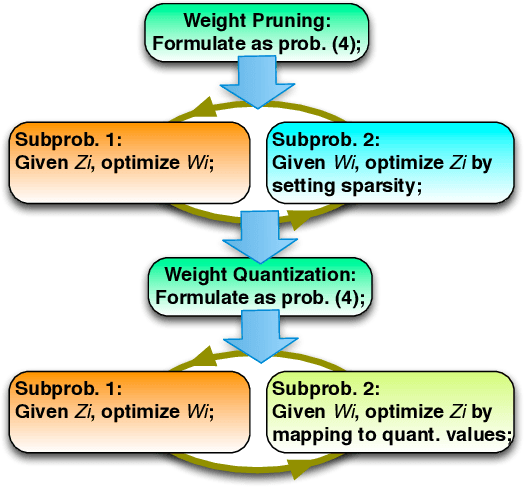
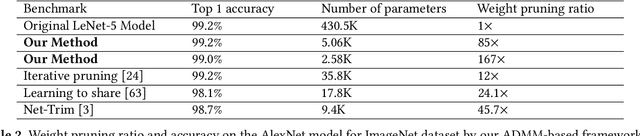
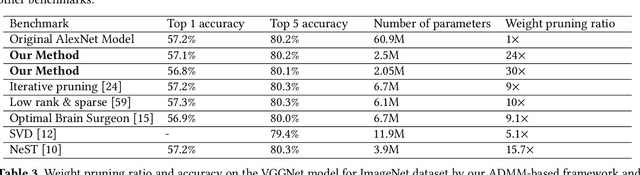
To facilitate efficient embedded and hardware implementations of deep neural networks (DNNs), two important categories of DNN model compression techniques: weight pruning and weight quantization are investigated. The former leverages the redundancy in the number of weights, whereas the latter leverages the redundancy in bit representation of weights. However, there lacks a systematic framework of joint weight pruning and quantization of DNNs, thereby limiting the available model compression ratio. Moreover, the computation reduction, energy efficiency improvement, and hardware performance overhead need to be accounted for besides simply model size reduction. To address these limitations, we present ADMM-NN, the first algorithm-hardware co-optimization framework of DNNs using Alternating Direction Method of Multipliers (ADMM), a powerful technique to deal with non-convex optimization problems with possibly combinatorial constraints. The first part of ADMM-NN is a systematic, joint framework of DNN weight pruning and quantization using ADMM. It can be understood as a smart regularization technique with regularization target dynamically updated in each ADMM iteration, thereby resulting in higher performance in model compression than prior work. The second part is hardware-aware DNN optimizations to facilitate hardware-level implementations. Without accuracy loss, we can achieve 85$\times$ and 24$\times$ pruning on LeNet-5 and AlexNet models, respectively, significantly higher than prior work. The improvement becomes more significant when focusing on computation reductions. Combining weight pruning and quantization, we achieve 1,910$\times$ and 231$\times$ reductions in overall model size on these two benchmarks, when focusing on data storage. Highly promising results are also observed on other representative DNNs such as VGGNet and ResNet-50.
Towards Budget-Driven Hardware Optimization for Deep Convolutional Neural Networks using Stochastic Computing
May 10, 2018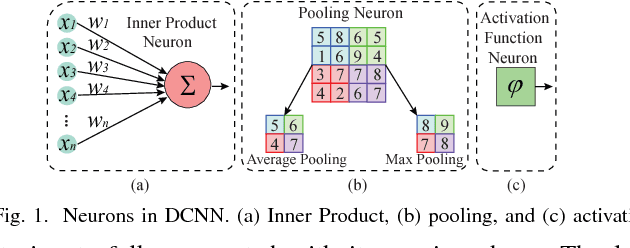
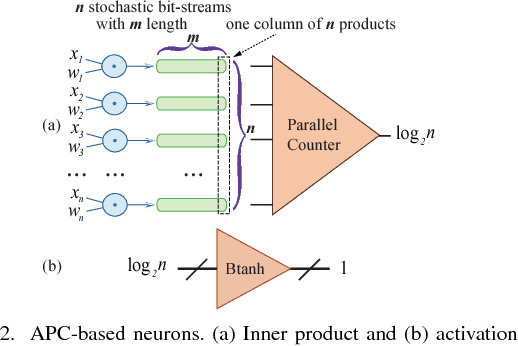
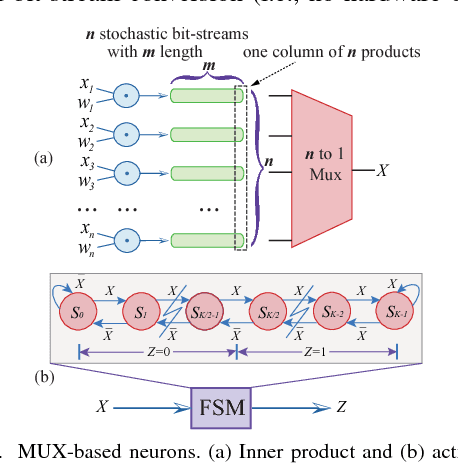
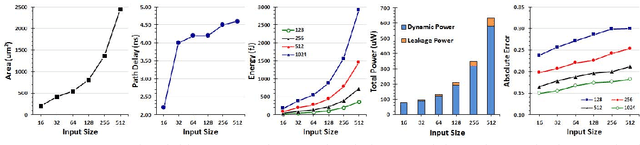
Recently, Deep Convolutional Neural Network (DCNN) has achieved tremendous success in many machine learning applications. Nevertheless, the deep structure has brought significant increases in computation complexity. Largescale deep learning systems mainly operate in high-performance server clusters, thus restricting the application extensions to personal or mobile devices. Previous works on GPU and/or FPGA acceleration for DCNNs show increasing speedup, but ignore other constraints, such as area, power, and energy. Stochastic Computing (SC), as a unique data representation and processing technique, has the potential to enable the design of fully parallel and scalable hardware implementations of large-scale deep learning systems. This paper proposed an automatic design allocation algorithm driven by budget requirement considering overall accuracy performance. This systematic method enables the automatic design of a DCNN where all design parameters are jointly optimized. Experimental results demonstrate that proposed algorithm can achieve a joint optimization of all design parameters given the comprehensive budget of a DCNN.
Structured Weight Matrices-Based Hardware Accelerators in Deep Neural Networks: FPGAs and ASICs
Mar 28, 2018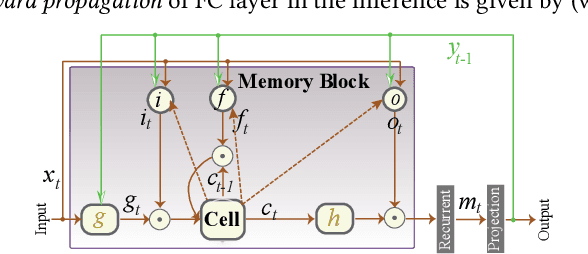
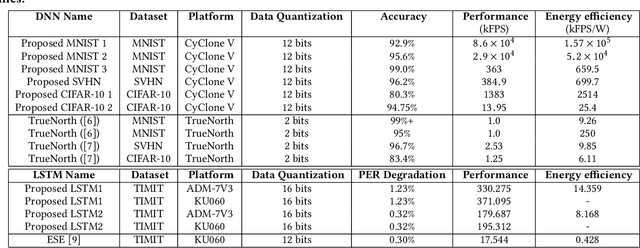
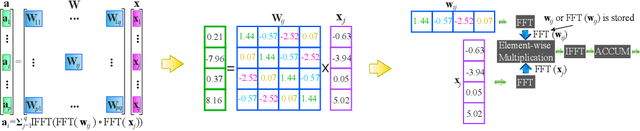

Both industry and academia have extensively investigated hardware accelerations. In this work, to address the increasing demands in computational capability and memory requirement, we propose structured weight matrices (SWM)-based compression techniques for both \emph{field programmable gate array} (FPGA) and \emph{application-specific integrated circuit} (ASIC) implementations. In algorithm part, SWM-based framework adopts block-circulant matrices to achieve a fine-grained tradeoff between accuracy and compression ratio. The SWM-based technique can reduce computational complexity from O($n^2$) to O($n\log n$) and storage complexity from O($n^2$) to O($n$) for each layer and both training and inference phases. For FPGA implementations on deep convolutional neural networks (DCNNs), we achieve at least 152X and 72X improvement in performance and energy efficiency, respectively using the SWM-based framework, compared with the baseline of IBM TrueNorth processor under same accuracy constraints using the data set of MNIST, SVHN, and CIFAR-10. For FPGA implementations on long short term memory (LSTM) networks, the proposed SWM-based LSTM can achieve up to 21X enhancement in performance and 33.5X gains in energy efficiency compared with the baseline accelerator. For ASIC implementations, the SWM-based ASIC design exhibits impressive advantages in terms of power, throughput, and energy efficiency. Experimental results indicate that this method is greatly suitable for applying DNNs onto both FPGAs and mobile/IoT devices.
An Area and Energy Efficient Design of Domain-Wall Memory-Based Deep Convolutional Neural Networks using Stochastic Computing
Feb 03, 2018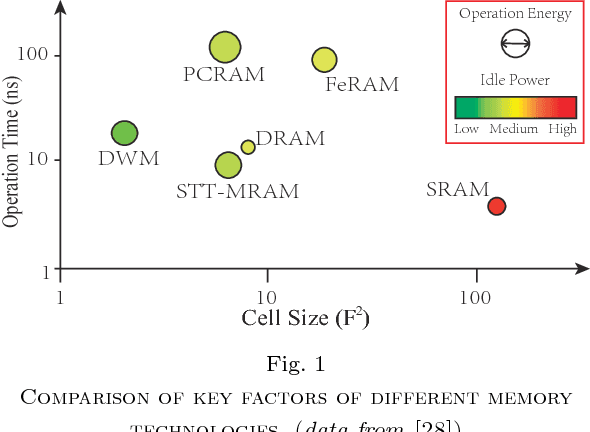
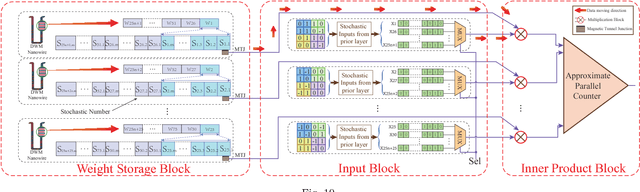
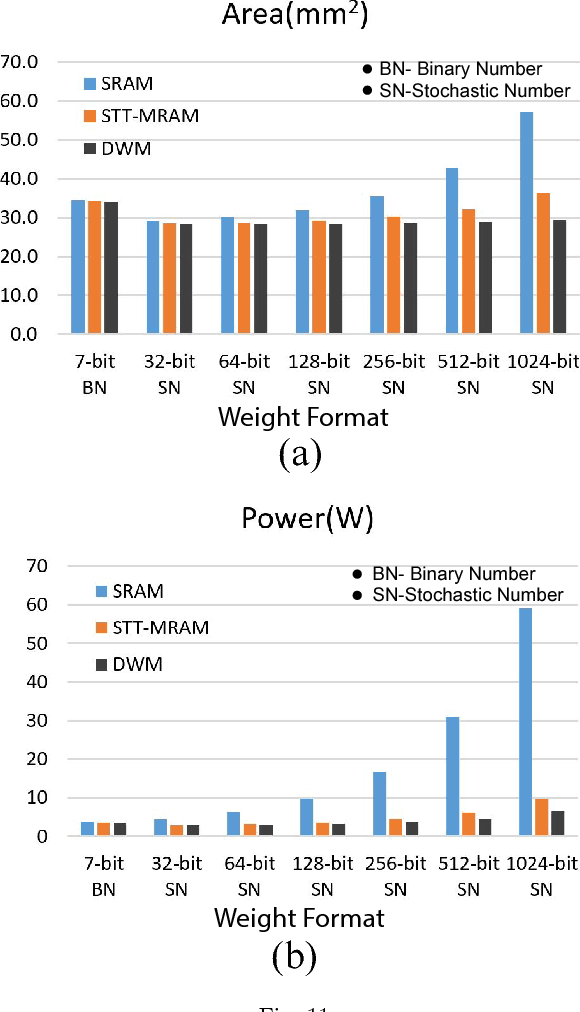
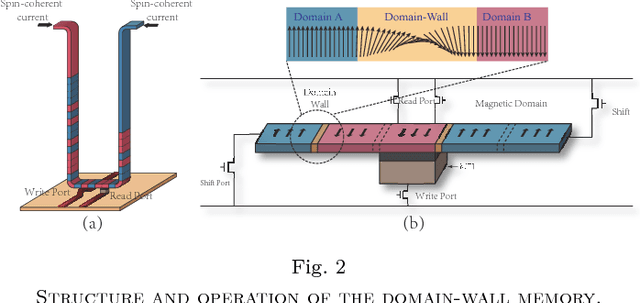
With recent trend of wearable devices and Internet of Things (IoTs), it becomes attractive to develop hardware-based deep convolutional neural networks (DCNNs) for embedded applications, which require low power/energy consumptions and small hardware footprints. Recent works demonstrated that the Stochastic Computing (SC) technique can radically simplify the hardware implementation of arithmetic units and has the potential to satisfy the stringent power requirements in embedded devices. However, in these works, the memory design optimization is neglected for weight storage, which will inevitably result in large hardware cost. Moreover, if conventional volatile SRAM or DRAM cells are utilized for weight storage, the weights need to be re-initialized whenever the DCNN platform is re-started. In order to overcome these limitations, in this work we adopt an emerging non-volatile Domain-Wall Memory (DWM), which can achieve ultra-high density, to replace SRAM for weight storage in SC-based DCNNs. We propose DW-CNN, the first comprehensive design optimization framework of DWM-based weight storage method. We derive the optimal memory type, precision, and organization, as well as whether to store binary or stochastic numbers. We present effective resource sharing scheme for DWM-based weight storage in the convolutional and fully-connected layers of SC-based DCNNs to achieve a desirable balance among area, power (energy) consumption, and application-level accuracy.