 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stochastic-Computing based Deep Learning Framework using Adiabatic Quantum-Flux-Parametron SuperconductingTechnology
Jul 22, 2019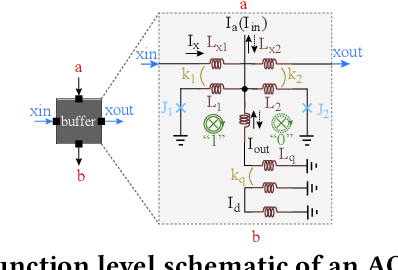
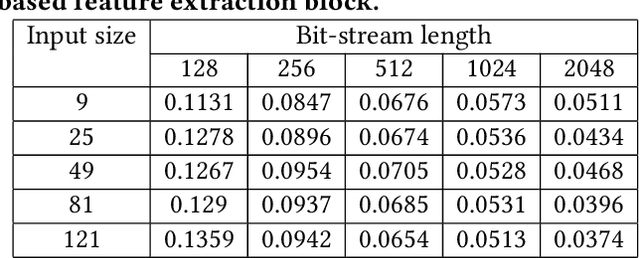
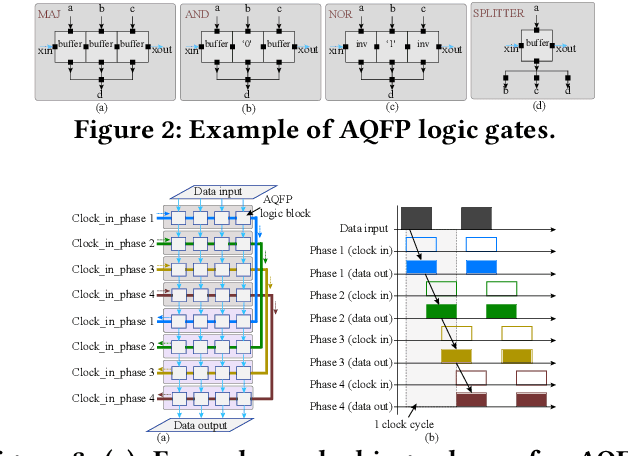
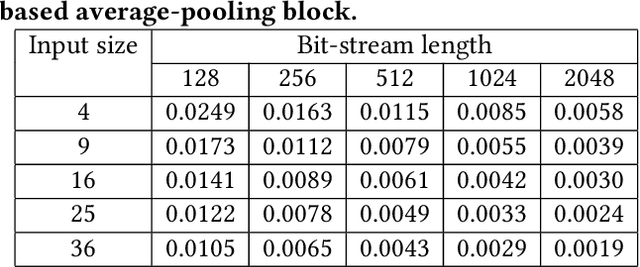
The Adiabatic Quantum-Flux-Parametron (AQFP) superconducting technology has been recently developed, which achieves the highest energy efficiency among superconducting logic families, potentially huge gain compared with state-of-the-art CMOS. In 2016, the successful fabrication and testing of AQFP-based circuits with the scale of 83,000 JJs have demonstrated the scalability and potential of implementing large-scale systems using AQFP. As a result, it will be promising for AQFP in high-performance computing and deep space applications, with Deep Neural Network (DNN) inference acceleration as an important example. Besides ultra-high energy efficiency, AQFP exhibits two unique characteristics: the deep pipelining nature since each AQFP logic gate is connected with an AC clock signal, which increases the difficulty to avoid RAW hazards; the second is the unique opportunity of true random number generation (RNG) using a single AQFP buffer, far more efficient than RNG in CMOS. We point out that these two characteristics make AQFP especially compatible with the \emph{stochastic computing} (SC) technique, which uses a time-independent bit sequence for value representation, and is compatible with the deep pipelining nature. Further, the application of SC has been investigated in DNNs in prior work, and the suitability has been illustrated as SC is more compatible with approximate computations. This work is the first to develop an SC-based DNN acceleration framework using AQFP technology.
VIBNN: Hardware Acceleration of Bayesian Neural Networks
Feb 02, 2018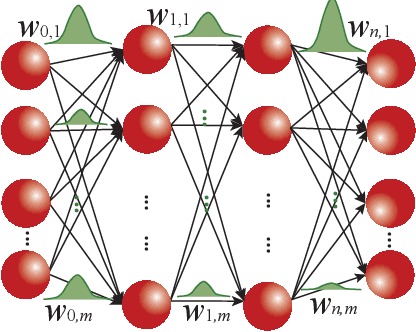
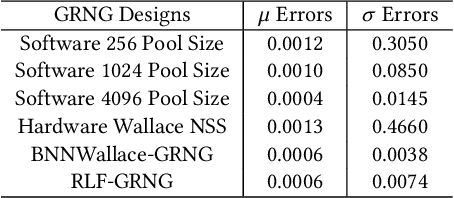
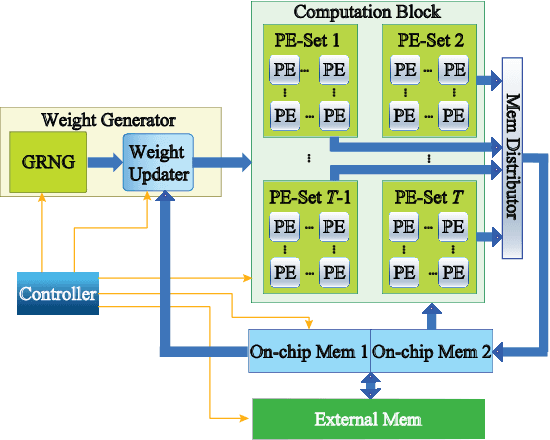
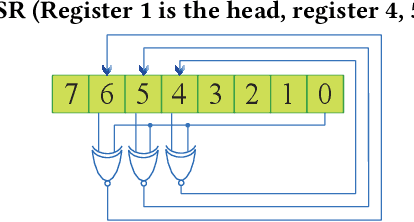
Bayesian Neural Networks (BNNs) have been proposed to address the problem of model uncertainty in training and inference. By introducing weights associated with conditioned probability distributions, BNNs are capable of resolving the overfitting issue commonly seen in conventional neural networks and allow for small-data training, through the variational inference process. Frequent usage of Gaussian random variables in this process requires a properly optimized Gaussian Random Number Generator (GRNG). The high hardware cost of conventional GRNG makes the hardware implementation of BNNs challenging. In this paper, we propose VIBNN, an FPGA-based hardware accelerator design for variational inference on BNNs. We explore the design space for massive amount of Gaussian variable sampling tasks in BNNs. Specifically, we introduce two high performance Gaussian (pseudo) random number generators: the RAM-based Linear Feedback Gaussian Random Number Generator (RLF-GRNG), which is inspired by the properties of binomial distribution and linear feedback logics; and the Bayesian Neural Network-oriented Wallace Gaussian Random Number Generator. To achieve high scalability and efficient memory access, we propose a deep pipelined accelerator architecture with fast execution and good hardware utilization. Experimental results demonstrate that the proposed VIBNN implementations on an FPGA can achieve throughput of 321,543.4 Images/s and energy efficiency upto 52,694.8 Images/J while maintaining similar accuracy as its software counterpart.