 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Budget-Driven Hardware Optimization for Deep Convolutional Neural Networks using Stochastic Computing
May 10, 2018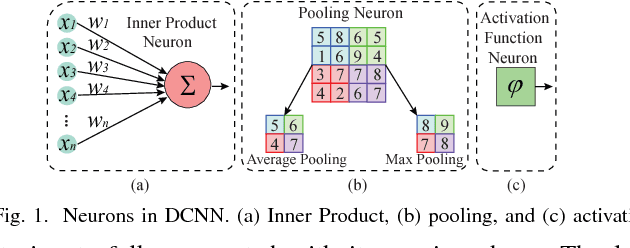
Recently, Deep Convolutional Neural Network (DCNN) has achieved tremendous success in many machine learning applications. Nevertheless, the deep structure has brought significant increases in computation complexity. Largescale deep learning systems mainly operate in high-performance server clusters, thus restricting the application extensions to personal or mobile devices. Previous works on GPU and/or FPGA acceleration for DCNNs show increasing speedup, but ignore other constraints, such as area, power, and energy. Stochastic Computing (SC), as a unique data representation and processing technique, has the potential to enable the design of fully parallel and scalable hardware implementations of large-scale deep learning systems. This paper proposed an automatic design allocation algorithm driven by budget requirement considering overall accuracy performance. This systematic method enables the automatic design of a DCNN where all design parameters are jointly optimized. Experimental results demonstrate that proposed algorithm can achieve a joint optimization of all design parameters given the comprehensive budget of a DCNN.
Hardware-Driven Nonlinear Activation for Stochastic Computing Based Deep Convolutional Neural Networks
Mar 12, 2017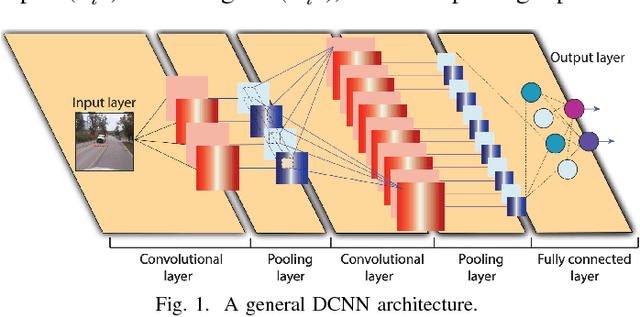
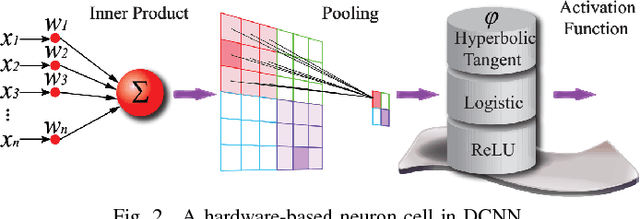
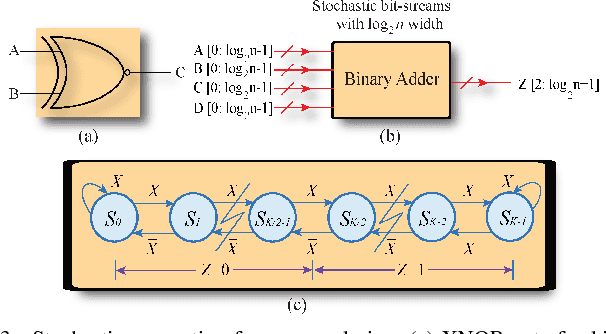

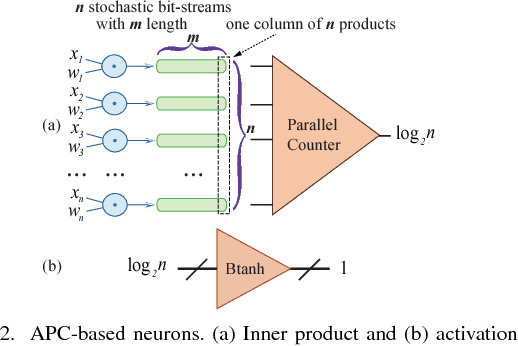
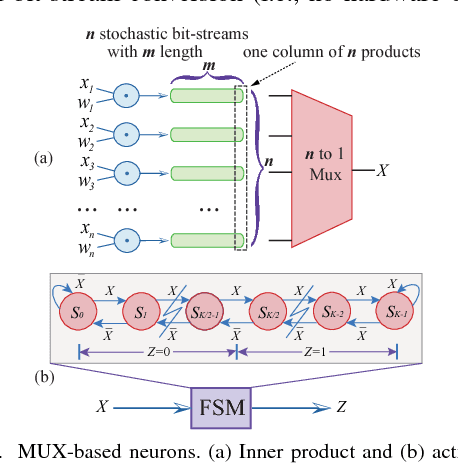
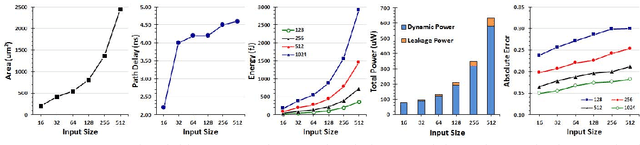
Recently, Deep Convolutional Neural Networks (DCNNs) have made unprecedented progress, achieving the accuracy close to, or even better than human-level perception in various tasks. There is a timely need to map the latest software DCNNs to application-specific hardware, in order to achieve orders of magnitude improvement in performance, energy efficiency and compactness. Stochastic Computing (SC), as a low-cost alternative to the conventional binary computing paradigm, has the potential to enable massively parallel and highly scalable hardware implementation of DCNNs. One major challenge in SC based DCNNs is designing accurate nonlinear activation functions, which have a significant impact on the network-level accuracy but cannot be implemented accurately by existing SC computing blocks. In this paper, we design and optimize SC based neurons, and we propose highly accurate activation designs for the three most frequently used activation functions in software DCNNs, i.e, hyperbolic tangent, logistic, and rectified linear units. Experimental results on LeNet-5 using MNIST dataset demonstrate that compared with a binary ASIC hardware DCNN, the DCNN with the proposed SC neurons can achieve up to 61X, 151X, and 2X improvement in terms of area, power, and energy, respectively, at the cost of small precision degradation.In addition, the SC approach achieves up to 21X and 41X of the area, 41X and 72X of the power, and 198200X and 96443X of the energy, compared with CPU and GPU approaches, respectively, while the error is increased by less than 3.07%. ReLU activation is suggested for future SC based DCNNs considering its superior performance under a small bit stream length.