 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADMM-NN: An Algorithm-Hardware Co-Design Framework of DNNs Using Alternating Direction Method of Multipliers
Dec 31, 2018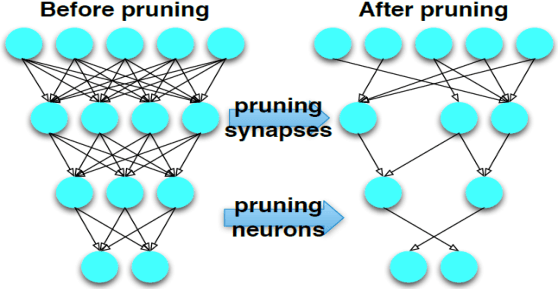
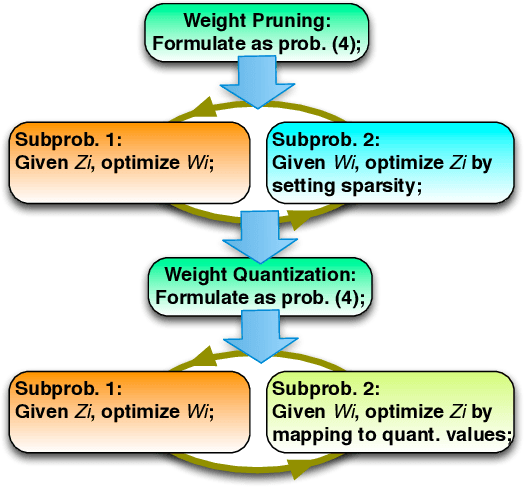
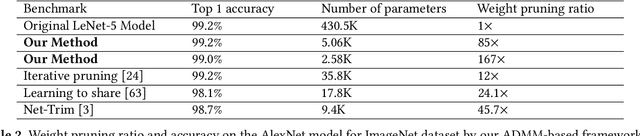
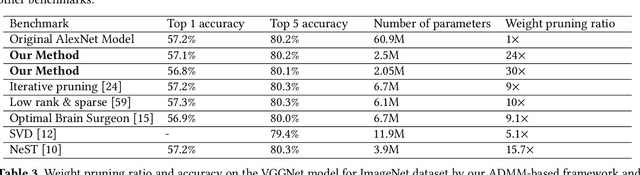
To facilitate efficient embedded and hardware implementations of deep neural networks (DNNs), two important categories of DNN model compression techniques: weight pruning and weight quantization are investigated. The former leverages the redundancy in the number of weights, whereas the latter leverages the redundancy in bit representation of weights. However, there lacks a systematic framework of joint weight pruning and quantization of DNNs, thereby limiting the available model compression ratio. Moreover, the computation reduction, energy efficiency improvement, and hardware performance overhead need to be accounted for besides simply model size reduction. To address these limitations, we present ADMM-NN, the first algorithm-hardware co-optimization framework of DNNs using Alternating Direction Method of Multipliers (ADMM), a powerful technique to deal with non-convex optimization problems with possibly combinatorial constraints. The first part of ADMM-NN is a systematic, joint framework of DNN weight pruning and quantization using ADMM. It can be understood as a smart regularization technique with regularization target dynamically updated in each ADMM iteration, thereby resulting in higher performance in model compression than prior work. The second part is hardware-aware DNN optimizations to facilitate hardware-level implementations. Without accuracy loss, we can achieve 85$\times$ and 24$\times$ pruning on LeNet-5 and AlexNet models, respectively, significantly higher than prior work. The improvement becomes more significant when focusing on computation reductions. Combining weight pruning and quantization, we achieve 1,910$\times$ and 231$\times$ reductions in overall model size on these two benchmarks, when focusing on data storage. Highly promising results are also observed on other representative DNNs such as VGGNet and ResNet-50.
E-RNN: Design Optimization for Efficient Recurrent Neural Networks in FPGAs
Dec 12, 2018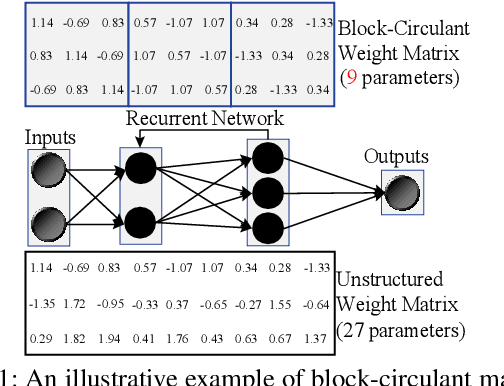
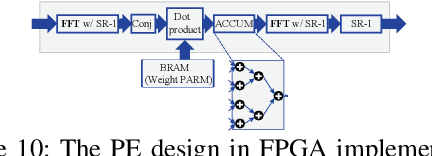
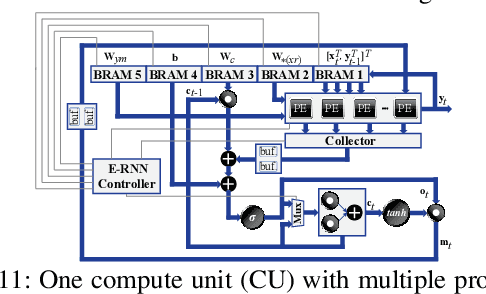
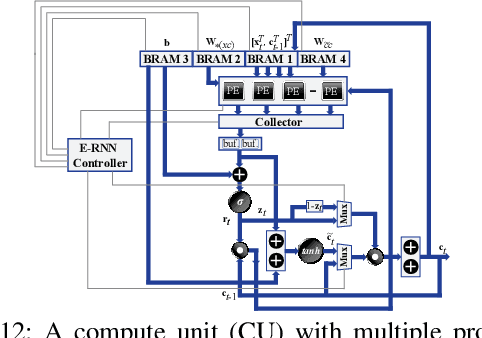
Recurrent Neural Networks (RNNs) are becoming increasingly important for time series-related applications which require efficient and real-time implementations. The two major types are Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks. It is a challenging task to have real-time, efficient, and accurate hardware RNN implementations because of the high sensitivity to imprecision accumulation and the requirement of special activation function implementations. A key limitation of the prior works is the lack of a systematic design optimization framework of RNN model and hardware implementations, especially when the block size (or compression ratio) should be jointly optimized with RNN type, layer size, etc. In this paper, we adopt the block-circulant matrix-based framework, and present the Efficient RNN (E-RNN) framework for FPGA implementations of the Automatic Speech Recognition (ASR) application. The overall goal is to improve performance/energy efficiency under accuracy requirement. We use the alternating direction method of multipliers (ADMM) technique for more accurate block-circulant training, and present two design explorations providing guidance on block size and reducing RNN training trials. Based on the two observations, we decompose E-RNN in two phases: Phase I on determining RNN model to reduce computation and storage subject to accuracy requirement, and Phase II on hardware implementations given RNN model, including processing element design/optimization, quantization, activation implementation, etc. Experimental results on actual FPGA deployments show that E-RNN achieves a maximum energy efficiency improvement of 37.4$\times$ compared with ESE, and more than 2$\times$ compared with C-LSTM, under the same accuracy.
2PFPCE: Two-Phase Filter Pruning Based on Conditional Entropy
Sep 06, 2018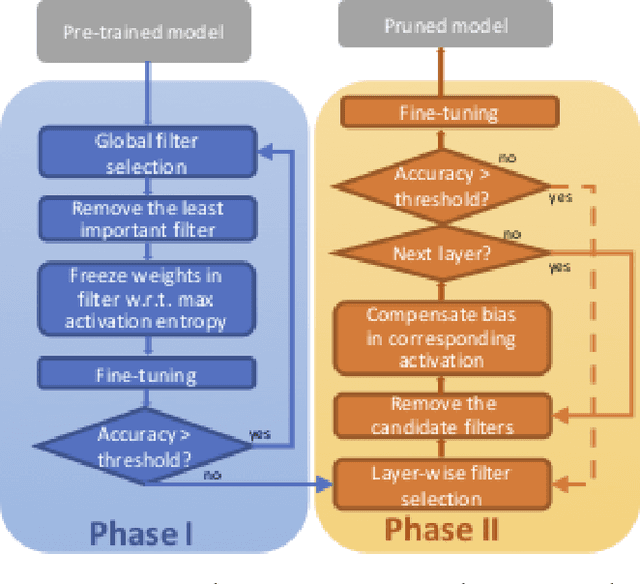
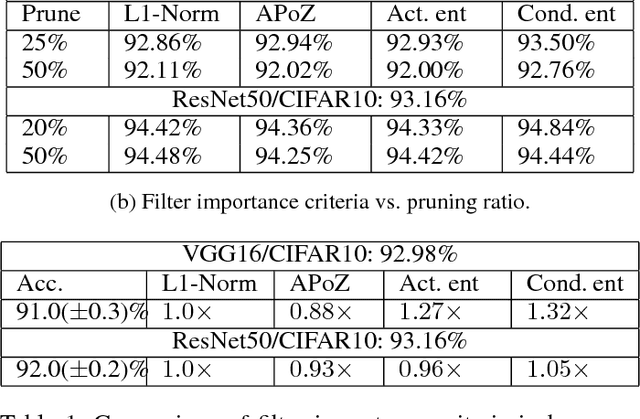
Deep Convolutional Neural Networks~(CNNs) offer remarkable performance of classifications and regressions in many high-dimensional problems and have been widely utilized in real-word cognitive applications. However, high computational cost of CNNs greatly hinder their deployment in resource-constrained applications, real-time systems and edge computing platforms. To overcome this challenge, we propose a novel filter-pruning framework, two-phase filter pruning based on conditional entropy, namely \textit{2PFPCE}, to compress the CNN models and reduce the inference time with marginal performance degradation. In our proposed method, we formulate filter pruning process as an optimization problem and propose a novel filter selection criteria measured by conditional entropy. Based on the assumption that the representation of neurons shall be evenly distributed, we also develop a maximum-entropy filter freeze technique that can reduce over fitting. Two filter pruning strategies -- global and layer-wise strategies, are compared. Our experiment result shows that combining these two strategies can achieve a higher neural network compression ratio than applying only one of them under the same accuracy drop threshold. Two-phase pruning, that is, combining both global and layer-wise strategies, achieves 10 X FLOPs reduction and 46% inference time reduction on VGG-16, with 2% accuracy drop.
C3PO: Database and Benchmark for Early-stage Malicious Activity Detection in 3D Printing
Aug 02, 2018
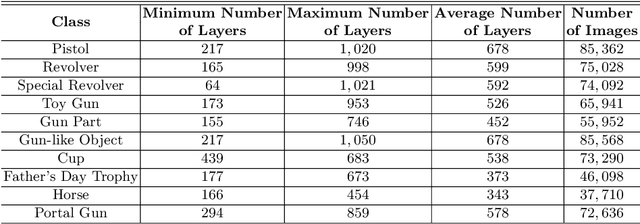

Increasing malicious users have sought practices to leverage 3D printing technology to produce unlawful tools in criminal activities. Current regulations are inadequate to deal with the rapid growth of 3D printers. It is of vital importance to enable 3D printers to identify the objects to be printed, so that the manufacturing procedure of an illegal weapon can be terminated at the early stage. Deep learning yields significant rises in performance in the object recognition tasks. However, the lack of large-scale databases in 3D printing domain stalls the advancement of automatic illegal weapon recognition. This paper presents a new 3D printing image database, namely C3PO, which compromises two subsets for the different system working scenarios. We extract images from the numerical control programming code files of 22 3D models, and then categorize the images into 10 distinct labels. The first set consists of 62,200 images which represent the object projections on the three planes in a Cartesian coordinate system. And the second sets consists of sequences of total 671,677 images to simulate the cameras' captures of the printed objects. Importantly, we demonstrate that the weapons can be recognized in either scenario using deep learning based approaches using our proposed database. % We also use the trained deep models to build a prototype of object-aware 3D printer. The quantitative results are promising, and the future exploration of the database and the crime prevention in 3D printing are demanding tasks.
Image Dataset for Visual Objects Classification in 3D Printing
Mar 22, 2018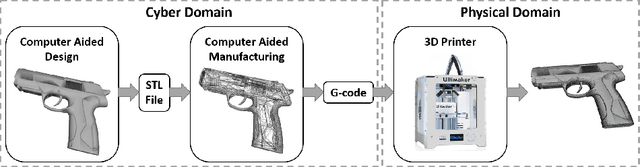

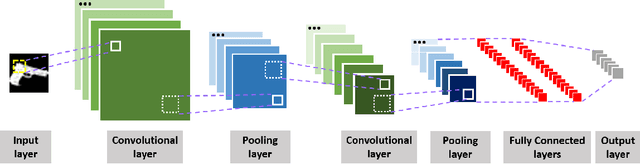
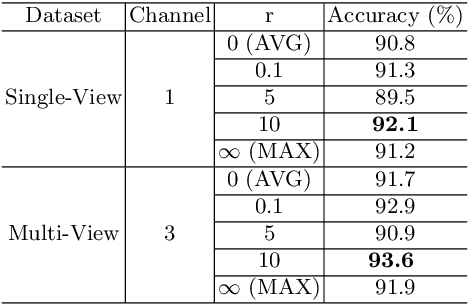
The rapid development in additive manufacturing (AM), also known as 3D printing, has brought about potential risk and security issues along with significant benefits. In order to enhance the security level of the 3D printing process, the present research aims to detect and recognize illegal components using deep learning. In this work, we collected a dataset of 61,340 2D images (28x28 for each image) of 10 classes including guns and other non-gun objects, corresponding to the projection results of the original 3D models. To validate the dataset, we train a convolutional neural network (CNN) model for gun classification which can achieve 98.16% classification accuracy.
Deep Neural Network Capacity
Feb 18, 2018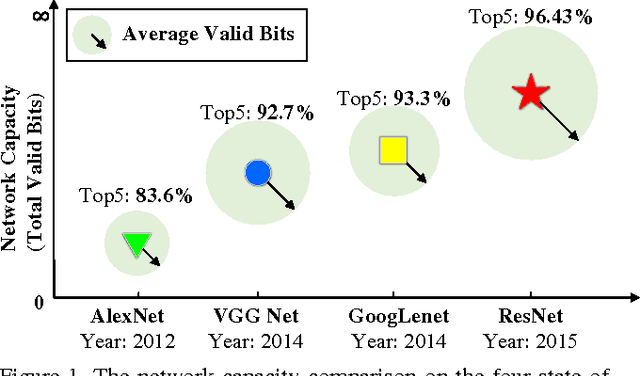
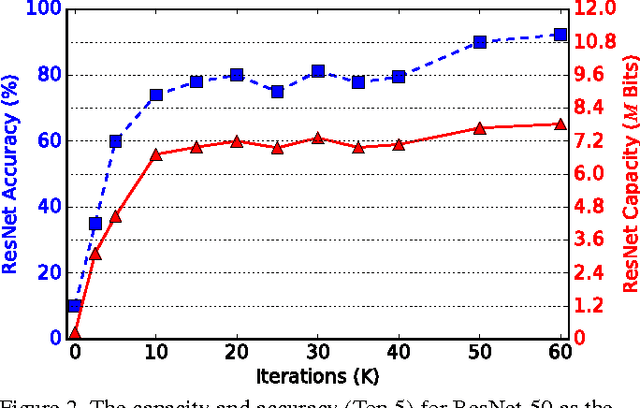
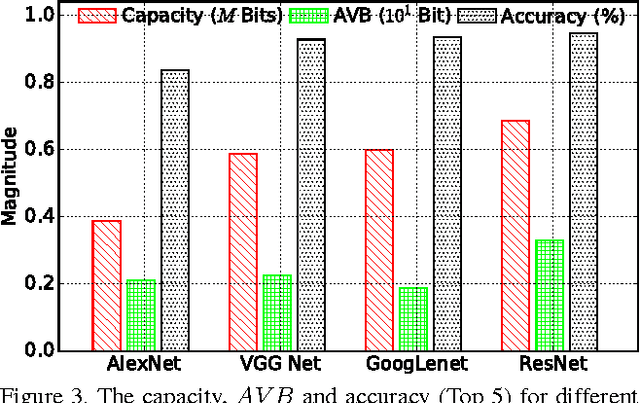
In recent years, deep neural network exhibits its powerful superiority on information discrimination in many computer vision applications. However, the capacity of deep neural network architecture is still a mystery to the researchers. Intuitively, larger capacity of neural network can always deposit more information to improve the discrimination ability of the model. But, the learnable parameter scale is not feasible to estimate the capacity of deep neural network. Due to the overfitting, directly increasing hidden nodes number and hidden layer number are already demonstrated not necessary to effectively increase the network discrimination ability. In this paper, we propose a novel measurement, named "total valid bits", to evaluate the capacity of deep neural networks for exploring how to quantitatively understand the deep learning and the insights behind its super performance. Specifically, our scheme to retrieve the total valid bits incorporates the skilled techniques in both training phase and inference phase. In the network training, we design decimal weight regularization and 8-bit forward quantization to obtain the integer-oriented network representations. Moreover, we develop adaptive-bitwidth and non-uniform quantization strategy in the inference phase to find the neural network capacity, total valid bits. By allowing zero bitwidth, our adaptive-bitwidth quantization can execute the model reduction and valid bits finding simultaneously. In our extensive experiments, we first demonstrate that our total valid bits is a good indicator of neural network capacity. We also analyze the impact on network capacity from the network architecture and advanced training skills, such as dropout and batch normalization.
Human Gender Classification: A Review
Mar 16, 2016
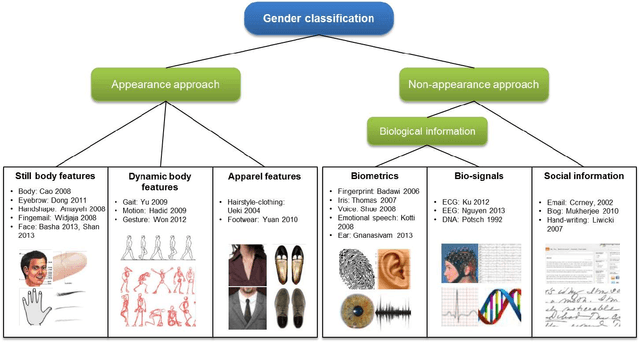
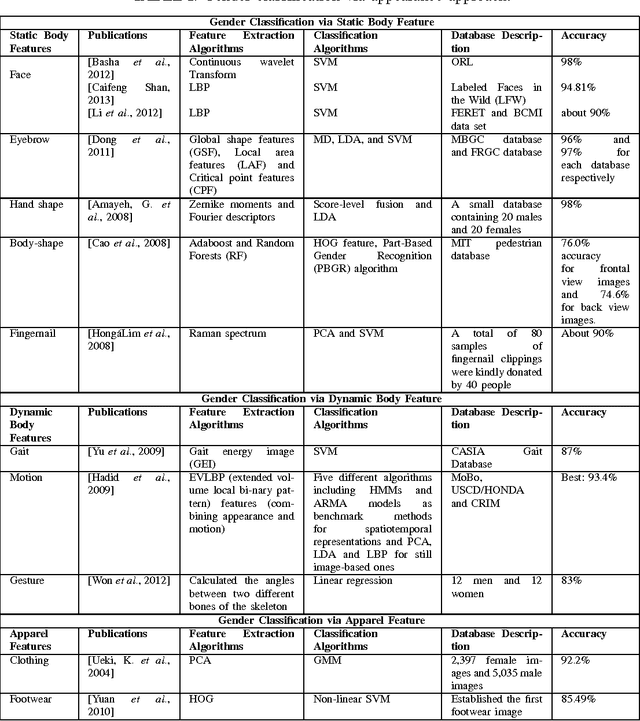
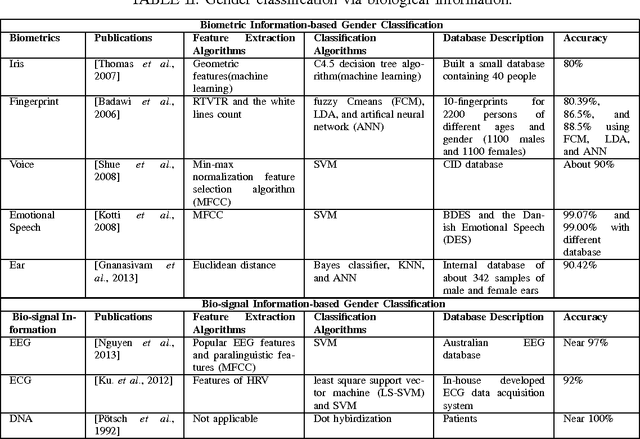
Gender contains a wide range of information regarding to the characteristics difference between male and female. Successful gender recognition is essential and critical for many applications in the commercial domains such as applications of human-computer interaction and computer-aided physiological or psychological analysis. Some have proposed various approaches for automatic gender classification using the features derived from human bodies and/or behaviors. First, this paper introduces the challenge and application for gender classification research. Then, the development and framework of gender classification are described. Besides, we compare these state-of-the-art approaches, including vision-based methods, biological information-based method, and social network information-based method, to provide a comprehensive review in the area of gender classification. In mean time, we highlight the strength and discuss the limitation of each method. Finally, this review also discusses several promising applications for the future work.