 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2PFPCE: Two-Phase Filter Pruning Based on Conditional Entropy
Sep 06, 2018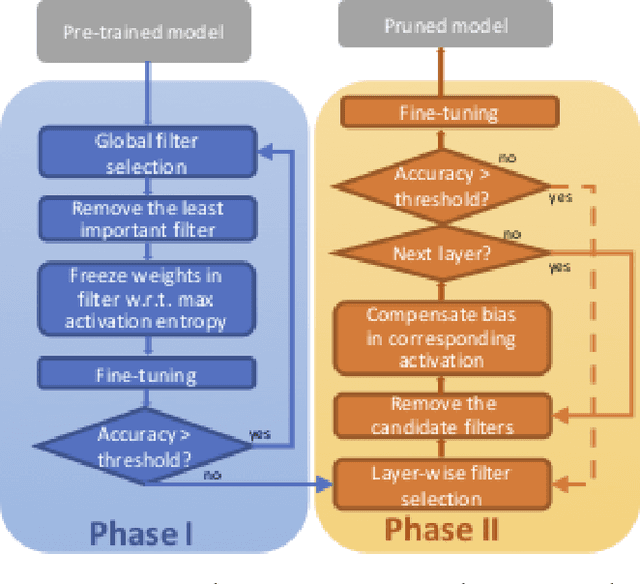
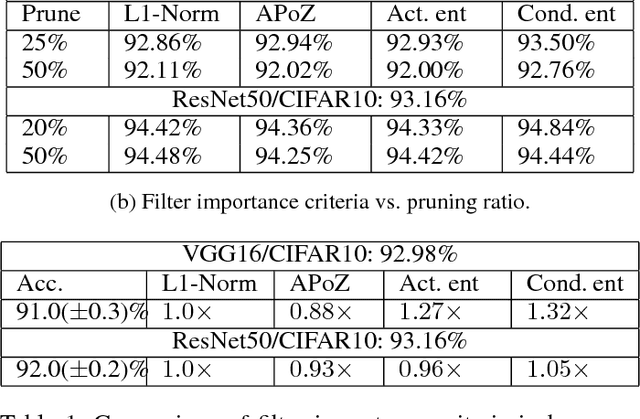
Deep Convolutional Neural Networks~(CNNs) offer remarkable performance of classifications and regressions in many high-dimensional problems and have been widely utilized in real-word cognitive applications. However, high computational cost of CNNs greatly hinder their deployment in resource-constrained applications, real-time systems and edge computing platforms. To overcome this challenge, we propose a novel filter-pruning framework, two-phase filter pruning based on conditional entropy, namely \textit{2PFPCE}, to compress the CNN models and reduce the inference time with marginal performance degradation. In our proposed method, we formulate filter pruning process as an optimization problem and propose a novel filter selection criteria measured by conditional entropy. Based on the assumption that the representation of neurons shall be evenly distributed, we also develop a maximum-entropy filter freeze technique that can reduce over fitting. Two filter pruning strategies -- global and layer-wise strategies, are compared. Our experiment result shows that combining these two strategies can achieve a higher neural network compression ratio than applying only one of them under the same accuracy drop threshold. Two-phase pruning, that is, combining both global and layer-wise strategies, achieves 10 X FLOPs reduction and 46% inference time reduction on VGG-16, with 2% accuracy drop.
Deep Neural Network Capacity
Feb 18, 2018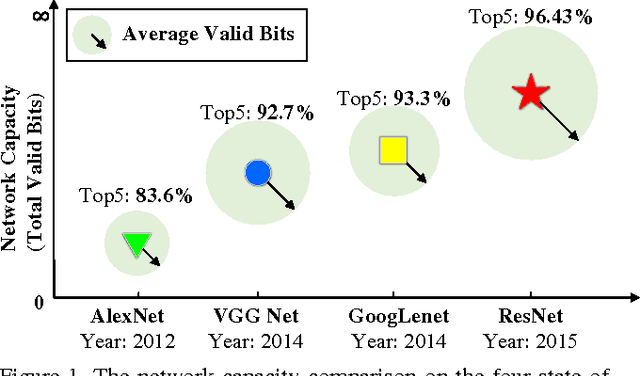
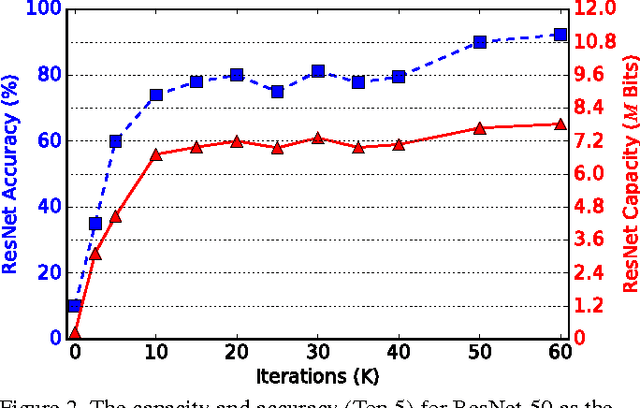
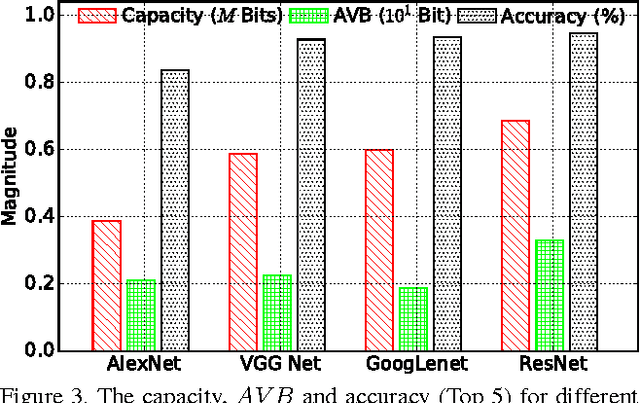
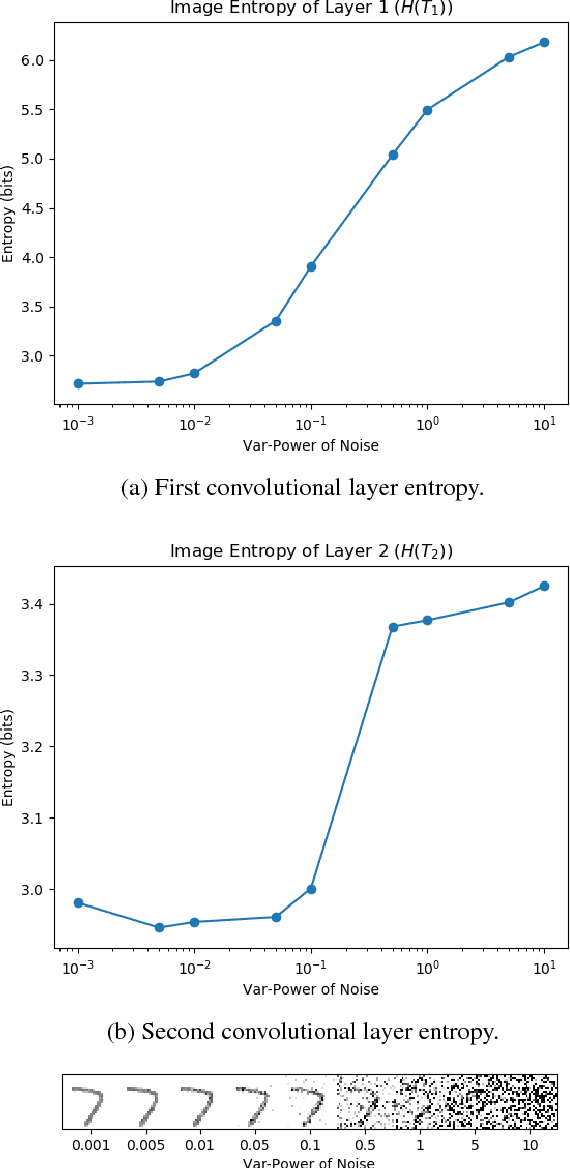
In recent years, deep neural network exhibits its powerful superiority on information discrimination in many computer vision applications. However, the capacity of deep neural network architecture is still a mystery to the researchers. Intuitively, larger capacity of neural network can always deposit more information to improve the discrimination ability of the model. But, the learnable parameter scale is not feasible to estimate the capacity of deep neural network. Due to the overfitting, directly increasing hidden nodes number and hidden layer number are already demonstrated not necessary to effectively increase the network discrimination ability. In this paper, we propose a novel measurement, named "total valid bits", to evaluate the capacity of deep neural networks for exploring how to quantitatively understand the deep learning and the insights behind its super performance. Specifically, our scheme to retrieve the total valid bits incorporates the skilled techniques in both training phase and inference phase. In the network training, we design decimal weight regularization and 8-bit forward quantization to obtain the integer-oriented network representations. Moreover, we develop adaptive-bitwidth and non-uniform quantization strategy in the inference phase to find the neural network capacity, total valid bits. By allowing zero bitwidth, our adaptive-bitwidth quantization can execute the model reduction and valid bits finding simultaneously. In our extensive experiments, we first demonstrate that our total valid bits is a good indicator of neural network capacity. We also analyze the impact on network capacity from the network architecture and advanced training skills, such as dropout and batch normalization.