 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2PFPCE: Two-Phase Filter Pruning Based on Conditional Entropy
Paper and Code
Sep 06, 2018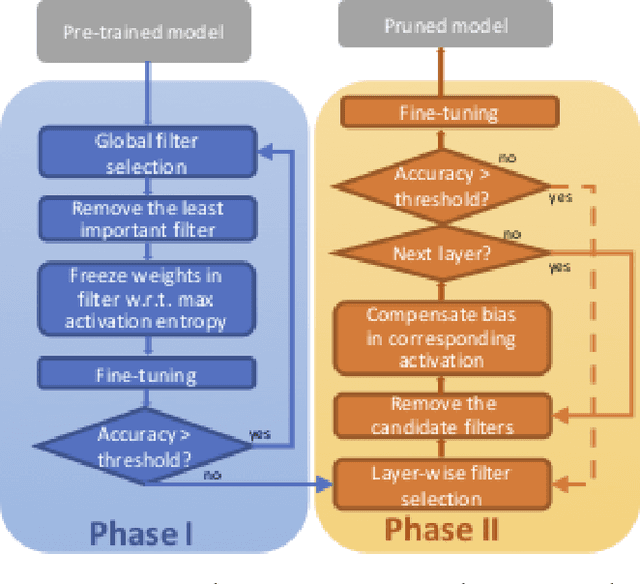
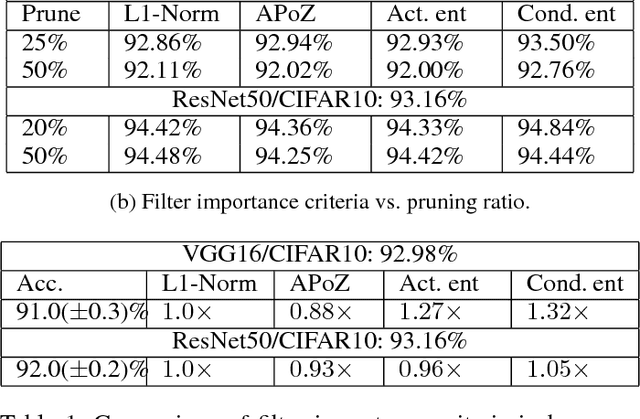
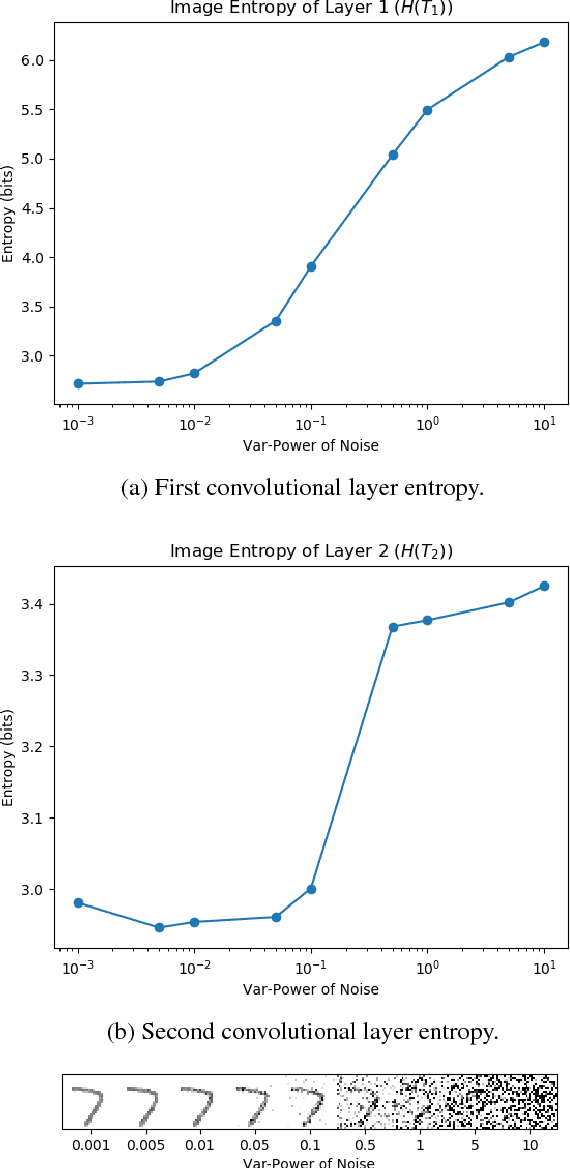
Deep Convolutional Neural Networks~(CNNs) offer remarkable performance of classifications and regressions in many high-dimensional problems and have been widely utilized in real-word cognitive applications. However, high computational cost of CNNs greatly hinder their deployment in resource-constrained applications, real-time systems and edge computing platforms. To overcome this challenge, we propose a novel filter-pruning framework, two-phase filter pruning based on conditional entropy, namely \textit{2PFPCE}, to compress the CNN models and reduce the inference time with marginal performance degradation. In our proposed method, we formulate filter pruning process as an optimization problem and propose a novel filter selection criteria measured by conditional entropy. Based on the assumption that the representation of neurons shall be evenly distributed, we also develop a maximum-entropy filter freeze technique that can reduce over fitting. Two filter pruning strategies -- global and layer-wise strategies, are compared. Our experiment result shows that combining these two strategies can achieve a higher neural network compression ratio than applying only one of them under the same accuracy drop threshold. Two-phase pruning, that is, combining both global and layer-wise strategies, achieves 10 X FLOPs reduction and 46% inference time reduction on VGG-16, with 2% accuracy drop.