 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Robustness of Indoor Robotic Navigation with Free-Space Segmentation Models Against Adversarial Attacks
Feb 13, 2024Endeavors in indoor robotic navigation rely on the accuracy of segmentation models to identify free space in RGB images. However, deep learning models are vulnerable to adversarial attacks, posing a significant challenge to their real-world deployment. In this study, we identify vulnerabilities within the hidden layers of neural networks and introduce a practical approach to reinforce traditional adversarial training. Our method incorporates a novel distance loss function, minimizing the gap between hidden layers in clean and adversarial images. Experiments demonstrate satisfactory performance in improving the model's robustness against adversarial perturbations.
Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
Jul 22, 2023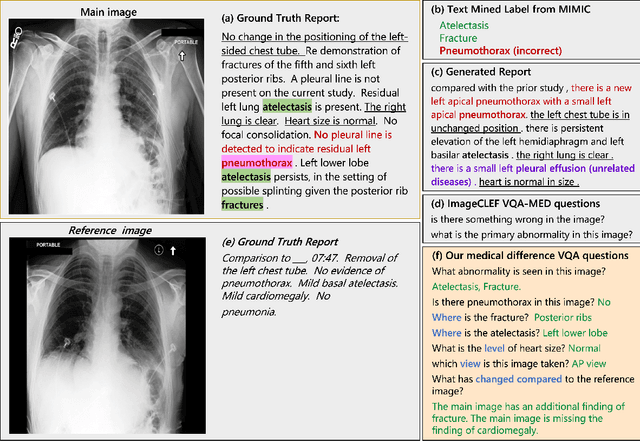

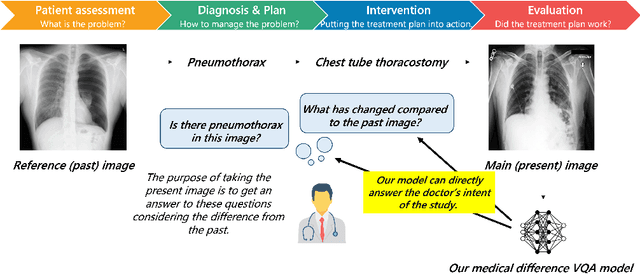
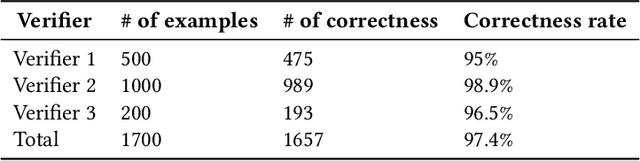
To contribute to automating the medical vision-language model, we propose a novel Chest-Xray Difference Visual Question Answering (VQA) task. Given a pair of main and reference images, this task attempts to answer several questions on both diseases and, more importantly, the differences between them. This is consistent with the radiologist's diagnosis practice that compares the current image with the reference before concluding the report. We collect a new dataset, namely MIMIC-Diff-VQA, including 700,703 QA pairs from 164,324 pairs of main and reference images. Compared to existing medical VQA datasets, our questions are tailored to the Assessment-Diagnosis-Intervention-Evaluation treatment procedure used by clinical professionals. Meanwhile, we also propose a novel expert knowledge-aware graph representation learning model to address this task. The proposed baseline model leverages expert knowledge such as anatomical structure prior, semantic, and spatial knowledge to construct a multi-relationship graph, representing the image differences between two images for the image difference VQA task. The dataset and code can be found at https://github.com/Holipori/MIMIC-Diff-VQA. We believe this work would further push forward the medical vision language model.
Interpretable Medical Image Visual Question Answering via Multi-Modal Relationship Graph Learning
Feb 19, 2023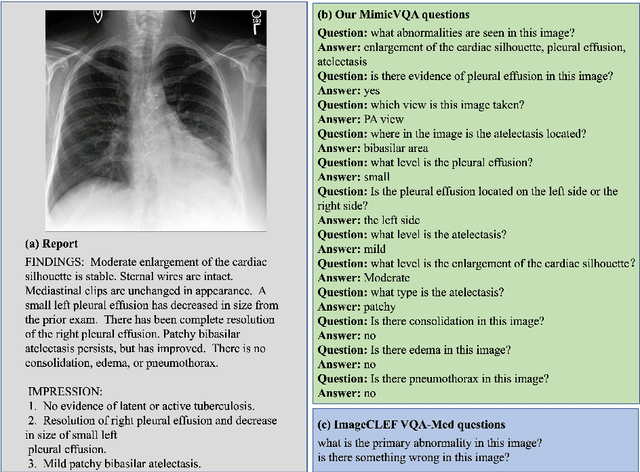
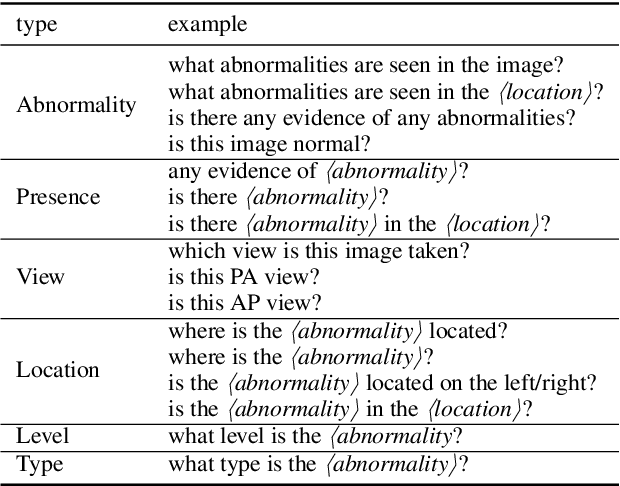
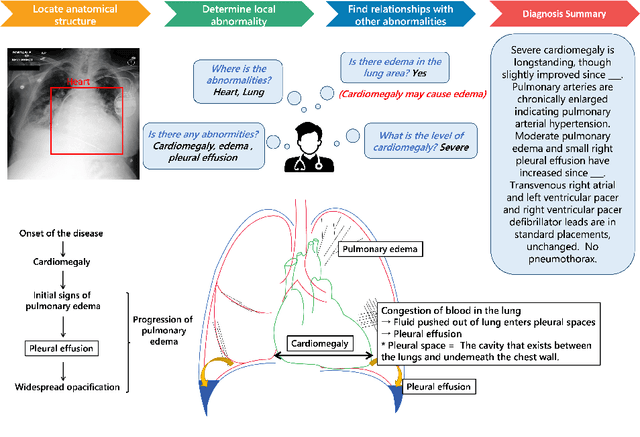
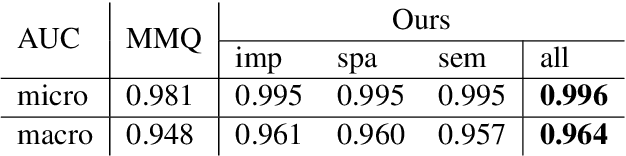
Medical visual question answering (VQA) aims to answer clinically relevant questions regarding input medical images. This technique has the potential to improve the efficiency of medical professionals while relieving the burden on the public health system, particularly in resource-poor countries. Existing medical VQA methods tend to encode medical images and learn the correspondence between visual features and questions without exploiting the spatial, semantic, or medical knowledge behind them. This is partially because of the small size of the current medical VQA dataset, which often includes simple questions. Therefore, we first collected a comprehensive and large-scale medical VQA dataset, focusing on chest X-ray images. The questions involved detailed relationships, such as disease names, locations, levels, and types in our dataset. Based on this dataset, we also propose a novel baseline method by constructing three different relationship graphs: spatial relationship, semantic relationship, and implicit relationship graphs on the image regions, questions, and semantic labels. The answer and graph reasoning paths are learned for different questions.
A Privacy-Preserving Unsupervised Domain Adaptation Framework for Clinical Text Analysis
Jan 18, 2022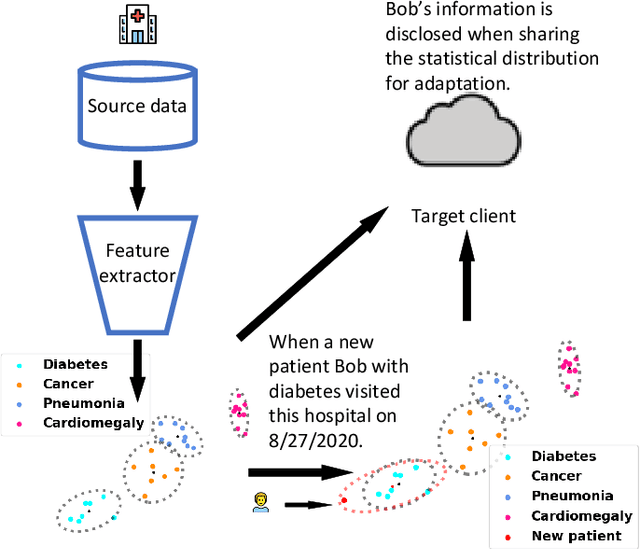
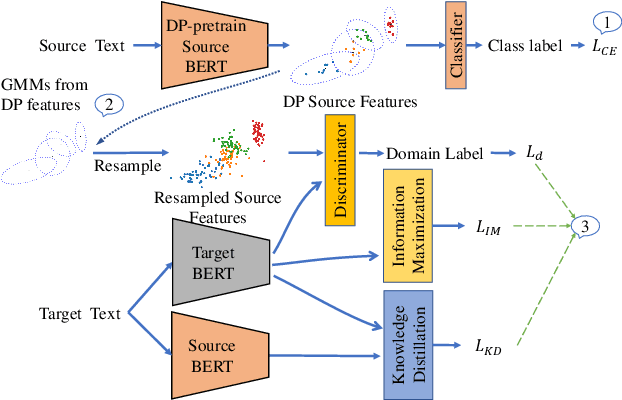
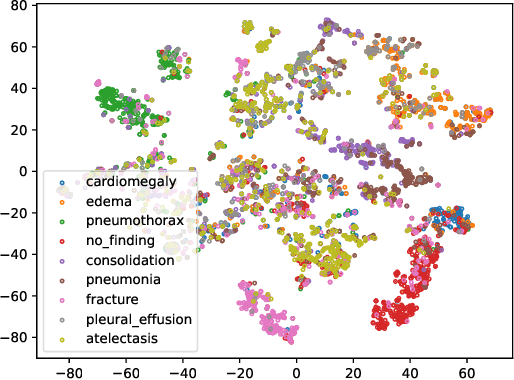
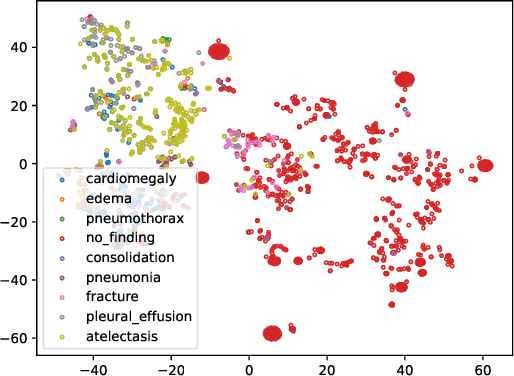
Unsupervised domain adaptation (UDA) generally aligns the unlabeled target domain data to the distribution of the source domain to mitigate the distribution shift problem. The standard UDA requires sharing the source data with the target, having potential data privacy leaking risks. To protect the source data's privacy, we first propose to share the source feature distribution instead of the source data. However, sharing only the source feature distribution may still suffer from the membership inference attack who can infer an individual's membership by the black-box access to the source model. To resolve this privacy issue, we further study the under-explored problem of privacy-preserving domain adaptation and propose a method with a novel differential privacy training strategy to protect the source data privacy. We model the source feature distribution by Gaussian Mixture Models (GMMs) under the differential privacy setting and send it to the target client for adaptation. The target client resamples differentially private source features from GMMs and adapts on target data with several state-of-art UDA backbones. With our proposed method, the source data provider could avoid leaking source data privacy during domain adaptation as well as reserve the utility. To evaluate our proposed method's utility and privacy loss, we apply our model on a medical report disease label classification task using two noisy challenging clinical text datasets. The results show that our proposed method can preserve source data's privacy with a minor performance influence on the text classification task.
Simultaneous Relevance and Diversity: A New Recommendation Inference Approach
Sep 27, 2020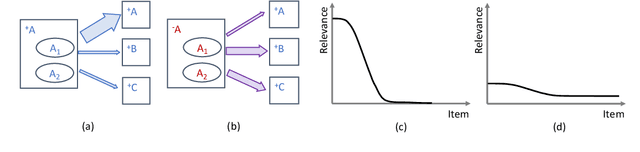
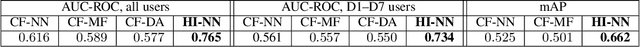
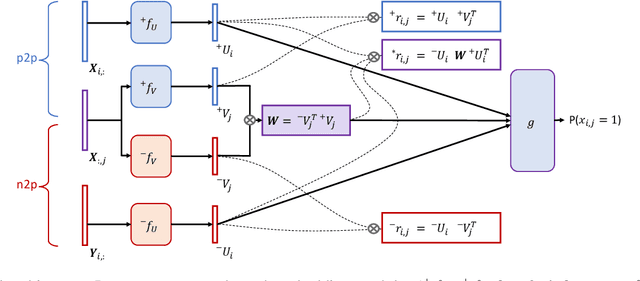
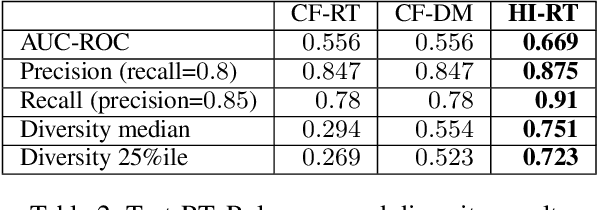
Relevance and diversity are both important to the success of recommender systems, as they help users to discover from a large pool of items a compact set of candidates that are not only interesting but exploratory as well. The challenge is that relevance and diversity usually act as two competing objectives in conventional recommender systems, which necessities the classic trade-off between exploitation and exploration. Traditionally, higher diversity often means sacrifice on relevance and vice versa. We propose a new approach, heterogeneous inference, which extends the general collaborative filtering (CF) by introducing a new way of CF inference, negative-to-positive. Heterogeneous inference achieves divergent relevance, where relevance and diversity support each other as two collaborating objectives in one recommendation model, and where recommendation diversity is an inherent outcome of the relevance inference process. Benefiting from its succinctness and flexibility, our approach is applicable to a wide range of recommendation scenarios/use-cases at various sophistication levels. Our analysis and experiments on public datasets and real-world production data show that our approach outperforms existing methods on relevance and diversity simultaneously.
C3PO: Database and Benchmark for Early-stage Malicious Activity Detection in 3D Printing
Aug 02, 2018
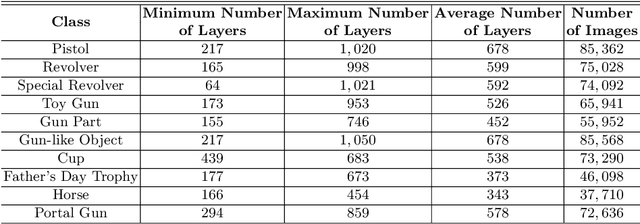

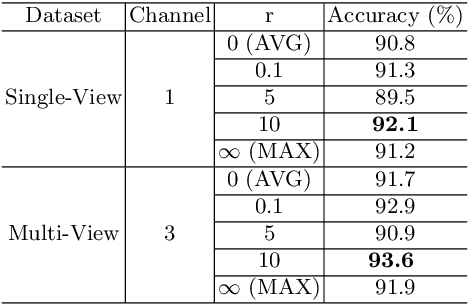
Increasing malicious users have sought practices to leverage 3D printing technology to produce unlawful tools in criminal activities. Current regulations are inadequate to deal with the rapid growth of 3D printers. It is of vital importance to enable 3D printers to identify the objects to be printed, so that the manufacturing procedure of an illegal weapon can be terminated at the early stage. Deep learning yields significant rises in performance in the object recognition tasks. However, the lack of large-scale databases in 3D printing domain stalls the advancement of automatic illegal weapon recognition. This paper presents a new 3D printing image database, namely C3PO, which compromises two subsets for the different system working scenarios. We extract images from the numerical control programming code files of 22 3D models, and then categorize the images into 10 distinct labels. The first set consists of 62,200 images which represent the object projections on the three planes in a Cartesian coordinate system. And the second sets consists of sequences of total 671,677 images to simulate the cameras' captures of the printed objects. Importantly, we demonstrate that the weapons can be recognized in either scenario using deep learning based approaches using our proposed database. % We also use the trained deep models to build a prototype of object-aware 3D printer. The quantitative results are promising, and the future exploration of the database and the crime prevention in 3D printing are demanding tasks.
Image Dataset for Visual Objects Classification in 3D Printing
Mar 22, 2018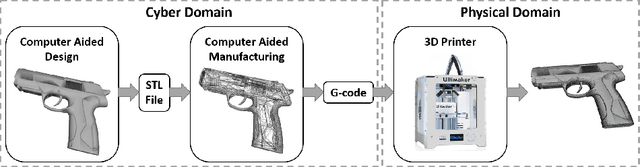

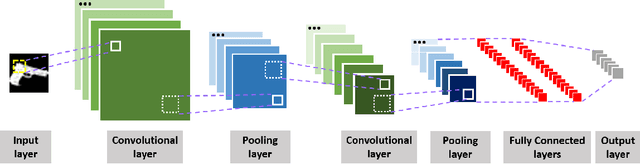
The rapid development in additive manufacturing (AM), also known as 3D printing, has brought about potential risk and security issues along with significant benefits. In order to enhance the security level of the 3D printing process, the present research aims to detect and recognize illegal components using deep learning. In this work, we collected a dataset of 61,340 2D images (28x28 for each image) of 10 classes including guns and other non-gun objects, corresponding to the projection results of the original 3D models. To validate the dataset, we train a convolutional neural network (CNN) model for gun classification which can achieve 98.16% classification accuracy.