 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Hospital-Invariant Feature Learning for WSI Patch Classification
Aug 20, 2025

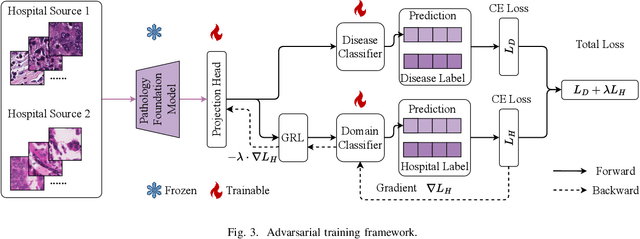

Pathology foundation models (PFMs) have demonstrated remarkable potential in whole-slide image (WSI) diagnosis. However, pathology images from different hospitals often vary due to differences in scanning hardware and preprocessing styles, which may lead PFMs to inadvertently learn hospital-specific features, posing risks for clinical deployment. In this work, we present the first systematic study of domain bias in PFMs arising from hospital source characteristics. Specifically, we (1) construct a pipeline for quantifying domain bias in PFMs, (2) evaluate and compare the performance of multiple models, and (3) propose a lightweight adversarial framework that removes latent hospital-specific features from frozen representations without modifying the encoder itself. By introducing a trainable adapter and a domain classifier connected through a gradient reversal layer (GRL), our method learns task-discriminative yet domain-invariant representations. Experiments on multi-center histopathology datasets demonstrate that our approach substantially reduces domain predictability while maintaining or even improving disease classification performance, particularly in out-of-domain (unseen hospital) scenarios. Further analyses, including hospital detection and feature space visualization, confirm the effectiveness of our method in mitigating hospital bias. We will provide our code based on acceptance.
Expert Uncertainty and Severity Aware Chest X-Ray Classification by Multi-Relationship Graph Learning
Sep 06, 2023Patients undergoing chest X-rays (CXR) often endure multiple lung diseases. When evaluating a patient's condition, due to the complex pathologies, subtle texture changes of different lung lesions in images, and patient condition differences, radiologists may make uncertain even when they have experienced long-term clinical training and professional guidance, which makes much noise in extracting disease labels based on CXR reports. In this paper, we re-extract disease labels from CXR reports to make them more realistic by considering disease severity and uncertainty in classification. Our contributions are as follows: 1. We re-extracted the disease labels with severity and uncertainty by a rule-based approach with keywords discussed with clinical experts. 2. To further improve the explainability of chest X-ray diagnosis, we designed a multi-relationship graph learning method with an expert uncertainty-aware loss function. 3. Our multi-relationship graph learning method can also interpret the disease classification results. Our experimental results show that models considering disease severity and uncertainty outperform previous state-of-the-art methods.
Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
Jul 22, 2023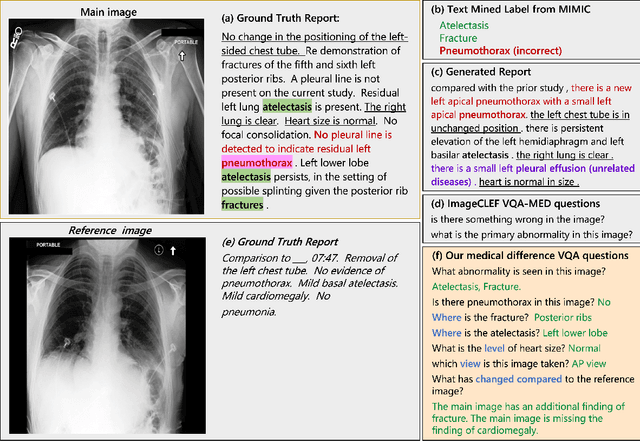

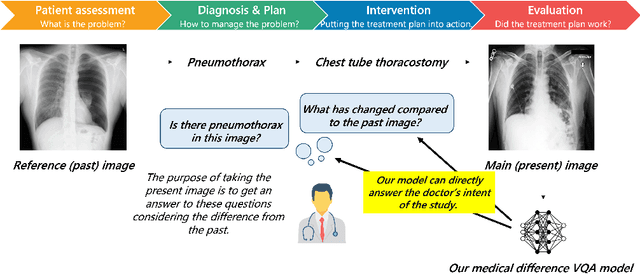
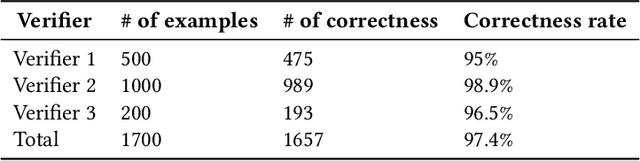
To contribute to automating the medical vision-language model, we propose a novel Chest-Xray Difference Visual Question Answering (VQA) task. Given a pair of main and reference images, this task attempts to answer several questions on both diseases and, more importantly, the differences between them. This is consistent with the radiologist's diagnosis practice that compares the current image with the reference before concluding the report. We collect a new dataset, namely MIMIC-Diff-VQA, including 700,703 QA pairs from 164,324 pairs of main and reference images. Compared to existing medical VQA datasets, our questions are tailored to the Assessment-Diagnosis-Intervention-Evaluation treatment procedure used by clinical professionals. Meanwhile, we also propose a novel expert knowledge-aware graph representation learning model to address this task. The proposed baseline model leverages expert knowledge such as anatomical structure prior, semantic, and spatial knowledge to construct a multi-relationship graph, representing the image differences between two images for the image difference VQA task. The dataset and code can be found at https://github.com/Holipori/MIMIC-Diff-VQA. We believe this work would further push forward the medical vision language model.