 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Foundation Model of Spatial Transcriptomics and Histology for Biological Discovery and Clinical Prediction
Apr 04, 2026Spatial transcriptomics (ST) enables gene expression mapping within anatomical context but remains costly and low-throughput. Hematoxylin and eosin (H\&E) staining offers rich morphology yet lacks molecular resolution. We present \textbf{\ours} (\textbf{S}patial \textbf{T}ranscriptomics and hist\textbf{O}logy \textbf{R}epresentation \textbf{M}odel), a foundation model trained on 1.2 million spatially resolved transcriptomic profiles with matched histology across 18 organs. Using a hierarchical architecture integrating morphological features, gene expression, and spatial context, STORM bridges imaging and omics through robust molecular--morphological representations. STORM enhances spatial domain discovery, producing biologically coherent tissue maps, and outperforms existing methods in predicting spatial gene expression from H\&E images across 11 tumor types. The model is platform-agnostic, performing consistently across Visium, Xenium, Visium HD, and CosMx. Applied to 23 independent cohorts comprising 7,245 patients, STORM significantly improves immunotherapy response prediction and prognostication over established biomarkers, providing a scalable framework for spatially informed discovery and clinical precision medicine.
A Generative Foundation Model for Multimodal Histopathology
Apr 04, 2026Accurate diagnosis and treatment of complex diseases require integrating histological, molecular, and clinical data, yet in practice these modalities are often incomplete owing to tissue scarcity, assay cost, and workflow constraints. Existing computational approaches attempt to impute missing modalities from available data but rely on task-specific models trained on narrow, single source-target pairs, limiting their generalizability. Here we introduce MuPD (Multimodal Pathology Diffusion), a generative foundation model that embeds hematoxylin and eosin (H&E)-stained histology, molecular RNA profiles, and clinical text into a shared latent space through a diffusion transformer with decoupled cross-modal attention. Pretrained on 100 million histology image patches, 1.6 million text-histology pairs, and 10.8 million RNA-histology pairs spanning 34 human organs, MuPD supports diverse cross-modal synthesis tasks with minimal or no task-specific fine-tuning. For text-conditioned and image-to-image generation, MuPD synthesizes histologically faithful tissue architectures, reducing Fréchet inception distance (FID) scores by 50% relative to domain-specific models and improving few-shot classification accuracy by up to 47% through synthetic data augmentation. For RNA-conditioned histology generation, MuPD reduces FID by 23% compared with the next-best method while preserving cell-type distributions across five cancer types. As a virtual stainer, MuPD translates H&E images to immunohistochemistry and multiplex immunofluorescence, improving average marker correlation by 37% over existing approaches. These results demonstrate that a single, unified generative model pretrained across heterogeneous pathology modalities can substantially outperform specialized alternatives, providing a scalable computational framework for multimodal histopathology.
nnMIL: A generalizable multiple instance learning framework for computational pathology
Nov 18, 2025Computational pathology holds substantial promise for improving diagnosis and guiding treatment decisions. Recent pathology foundation models enable the extraction of rich patch-level representations from large-scale whole-slide images (WSIs), but current approaches for aggregating these features into slide-level predictions remain constrained by design limitations that hinder generalizability and reliability. Here, we developed nnMIL, a simple yet broadly applicable multiple-instance learning framework that connects patch-level foundation models to robust slide-level clinical inference. nnMIL introduces random sampling at both the patch and feature levels, enabling large-batch optimization, task-aware sampling strategies, and efficient and scalable training across datasets and model architectures. A lightweight aggregator performs sliding-window inference to generate ensemble slide-level predictions and supports principled uncertainty estimation. Across 40,000 WSIs encompassing 35 clinical tasks and four pathology foundation models, nnMIL consistently outperformed existing MIL methods for disease diagnosis, histologic subtyping, molecular biomarker detection, and pan- cancer prognosis prediction. It further demonstrated strong cross-model generalization, reliable uncertainty quantification, and robust survival stratification in multiple external cohorts. In conclusion, nnMIL offers a practical and generalizable solution for translating pathology foundation models into clinically meaningful predictions, advancing the development and deployment of reliable AI systems in real-world settings.
A Generative Foundation Model for Chest Radiography
Sep 04, 2025The scarcity of well-annotated diverse medical images is a major hurdle for developing reliable AI models in healthcare. Substantial technical advances have been made in generative foundation models for natural images. Here we develop `ChexGen', a generative vision-language foundation model that introduces a unified framework for text-, mask-, and bounding box-guided synthesis of chest radiographs. Built upon the latent diffusion transformer architecture, ChexGen was pretrained on the largest curated chest X-ray dataset to date, consisting of 960,000 radiograph-report pairs. ChexGen achieves accurate synthesis of radiographs through expert evaluations and quantitative metrics. We demonstrate the utility of ChexGen for training data augmentation and supervised pretraining, which led to performance improvements across disease classification, detection, and segmentation tasks using a small fraction of training data. Further, our model enables the creation of diverse patient cohorts that enhance model fairness by detecting and mitigating demographic biases. Our study supports the transformative role of generative foundation models in building more accurate, data-efficient, and equitable medical AI systems.
Memory Efficient Temporal & Visual Graph Model for Unsupervised Video Domain Adaptation
Aug 13, 2022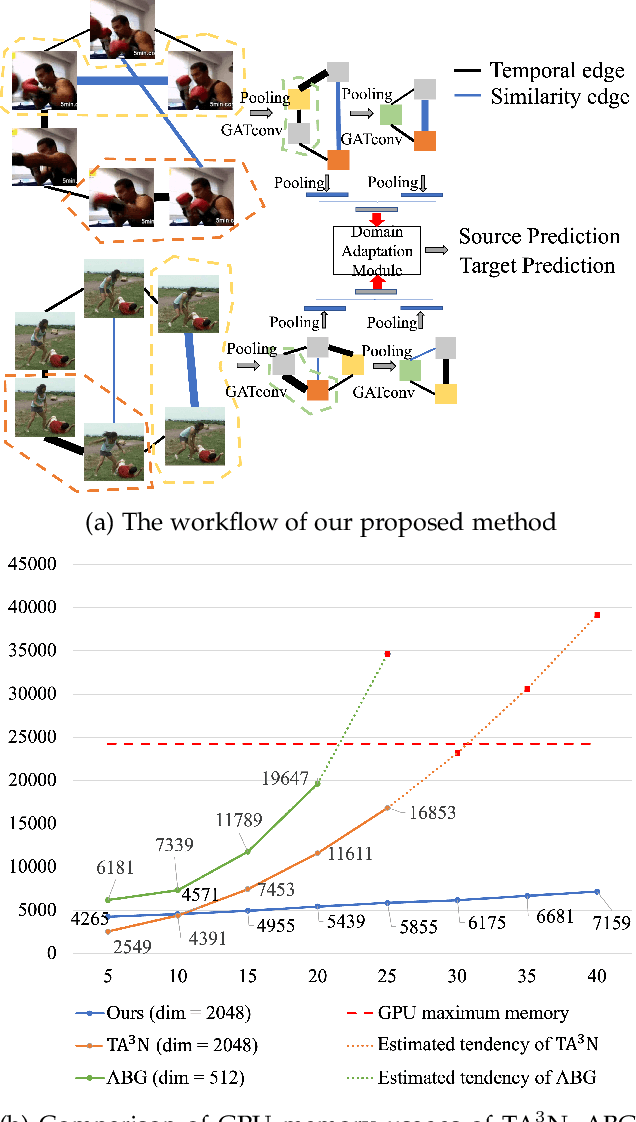
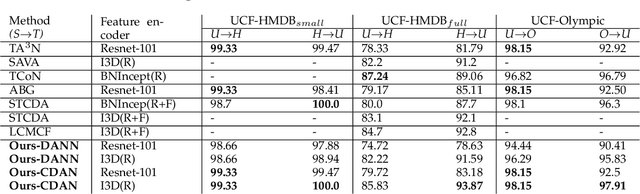
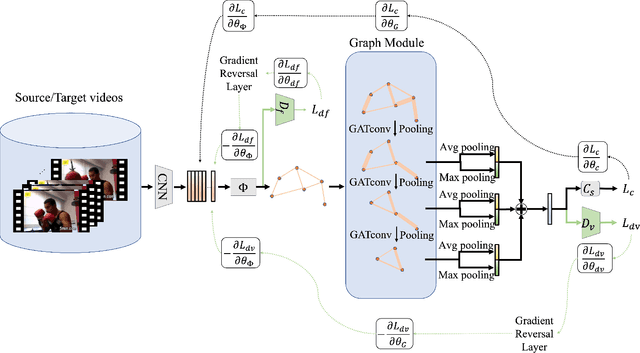
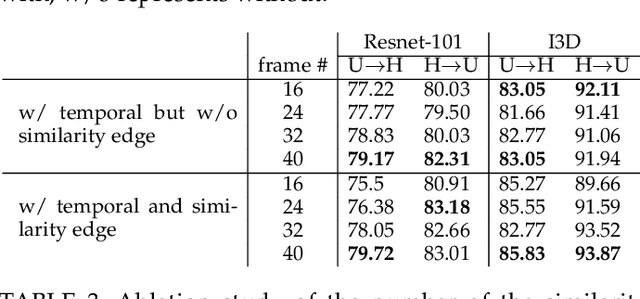
Existing video domain adaption (DA) methods need to store all temporal combinations of video frames or pair the source and target videos, which are memory cost expensive and can't scale up to long videos. To address these limitations, we propose a memory-efficient graph-based video DA approach as follows. At first our method models each source or target video by a graph: nodes represent video frames and edges represent the temporal or visual similarity relationship between frames. We use a graph attention network to learn the weight of individual frames and simultaneously align the source and target video into a domain-invariant graph feature space. Instead of storing a large number of sub-videos, our method only constructs one graph with a graph attention mechanism for one video, reducing the memory cost substantially. The extensive experiments show that, compared with the state-of-art methods, we achieved superior performance while reducing the memory cost significantly.
A Privacy-Preserving Unsupervised Domain Adaptation Framework for Clinical Text Analysis
Jan 18, 2022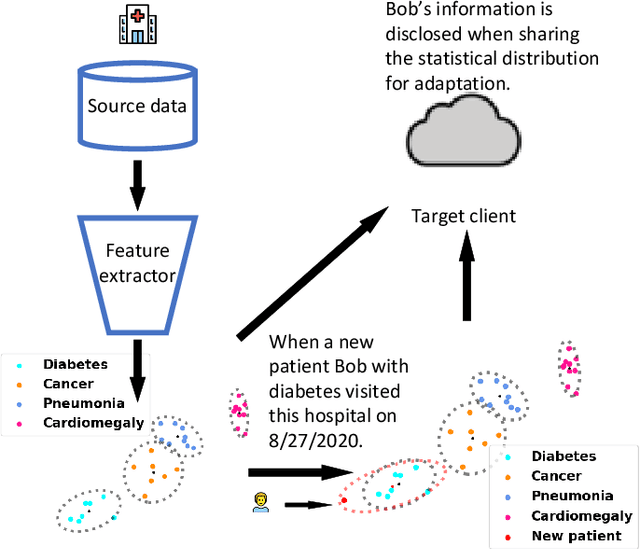
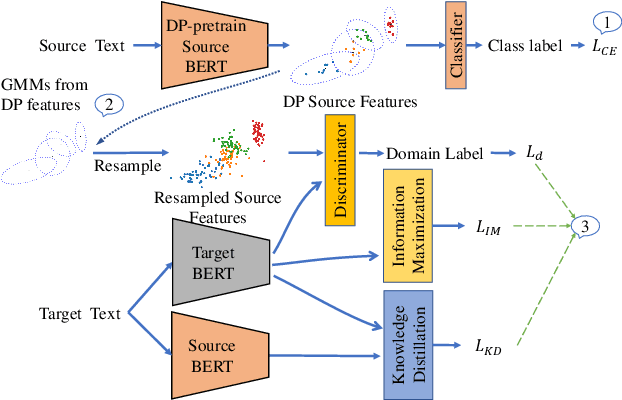
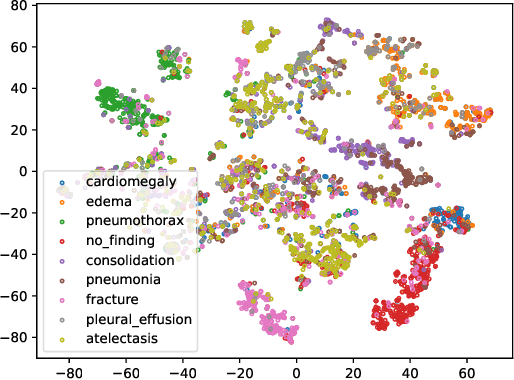
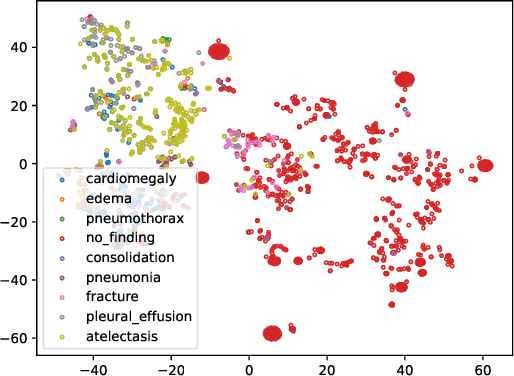
Unsupervised domain adaptation (UDA) generally aligns the unlabeled target domain data to the distribution of the source domain to mitigate the distribution shift problem. The standard UDA requires sharing the source data with the target, having potential data privacy leaking risks. To protect the source data's privacy, we first propose to share the source feature distribution instead of the source data. However, sharing only the source feature distribution may still suffer from the membership inference attack who can infer an individual's membership by the black-box access to the source model. To resolve this privacy issue, we further study the under-explored problem of privacy-preserving domain adaptation and propose a method with a novel differential privacy training strategy to protect the source data privacy. We model the source feature distribution by Gaussian Mixture Models (GMMs) under the differential privacy setting and send it to the target client for adaptation. The target client resamples differentially private source features from GMMs and adapts on target data with several state-of-art UDA backbones. With our proposed method, the source data provider could avoid leaking source data privacy during domain adaptation as well as reserve the utility. To evaluate our proposed method's utility and privacy loss, we apply our model on a medical report disease label classification task using two noisy challenging clinical text datasets. The results show that our proposed method can preserve source data's privacy with a minor performance influence on the text classification task.
Relation Embedding with Dihedral Group in Knowledge Graph
Jun 03, 2019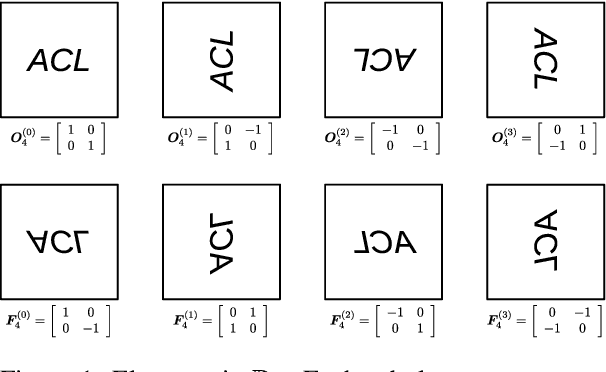

Link prediction is critical for the application of incomplete knowledge graph (KG) in the downstream tasks. As a family of effective approaches for link predictions, embedding methods try to learn low-rank representations for both entities and relations such that the bilinear form defined therein is a well-behaved scoring function. Despite of their successful performances, existing bilinear forms overlook the modeling of relation compositions, resulting in lacks of interpretability for reasoning on KG. To fulfill this gap, we propose a new model called DihEdral, named after dihedral symmetry group. This new model learns knowledge graph embeddings that can capture relation compositions by nature. Furthermore, our approach models the relation embeddings parametrized by discrete values, thereby decrease the solution space drastically. Our experiments show that DihEdral is able to capture all desired properties such as (skew-) symmetry, inversion and (non-) Abelian composition, and outperforms existing bilinear form based approach and is comparable to or better than deep learning models such as ConvE.
Groupwise Constrained Reconstruction for Subspace Clustering
Jun 18, 2012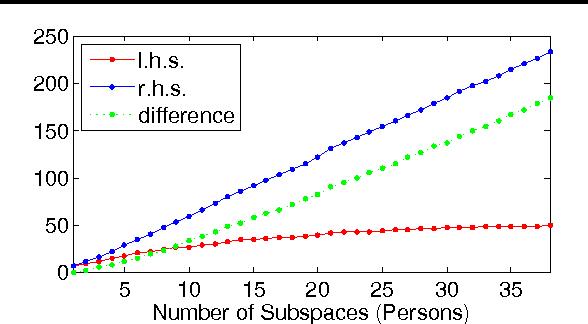
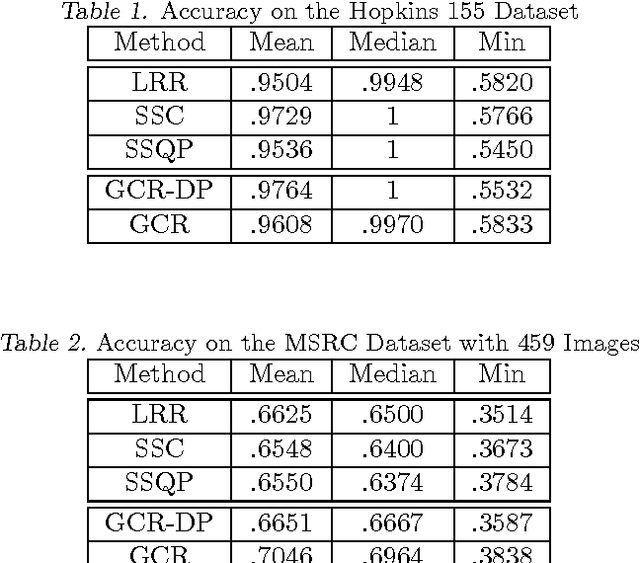
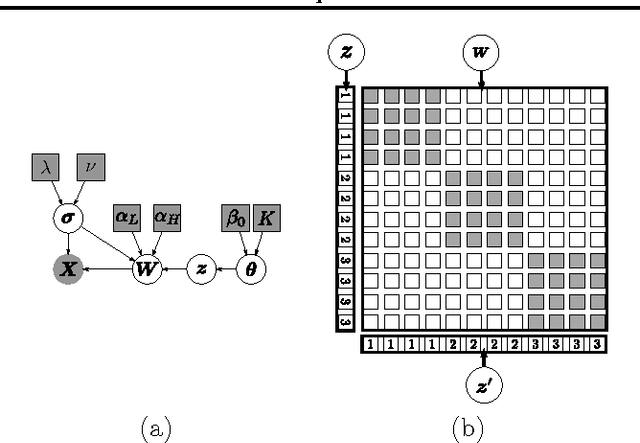
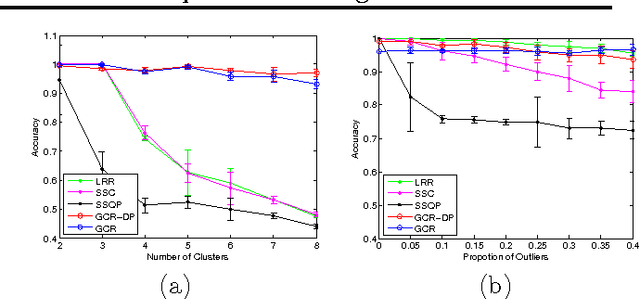
Reconstruction based subspace clustering methods compute a self reconstruction matrix over the samples and use it for spectral clustering to obtain the final clustering result. Their success largely relies on the assumption that the underlying subspaces are independent, which, however, does not always hold in the applications with increasing number of subspaces. In this paper, we propose a novel reconstruction based subspace clustering model without making the subspace independence assumption. In our model, certain properties of the reconstruction matrix are explicitly characterized using the latent cluster indicators, and the affinity matrix used for spectral clustering can be directly built from the posterior of the latent cluster indicators instead of the reconstruction matrix. Experimental results on both synthetic and real-world datasets show that the proposed model can outperform the state-of-the-art methods.