 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering
Apr 26, 2024In customer service technical support, swiftly and accurately retrieving relevant past issues is critical for efficiently resolving customer inquiries. The conventional retrieval methods in retrieval-augmented generation (RAG) for large language models (LLMs) treat a large corpus of past issue tracking tickets as plain text, ignoring the crucial intra-issue structure and inter-issue relations, which limits performance. We introduce a novel customer service question-answering method that amalgamates RAG with a knowledge graph (KG). Our method constructs a KG from historical issues for use in retrieval, retaining the intra-issue structure and inter-issue relations. During the question-answering phase, our method parses consumer queries and retrieves related sub-graphs from the KG to generate answers. This integration of a KG not only improves retrieval accuracy by preserving customer service structure information but also enhances answering quality by mitigating the effects of text segmentation. Empirical assessments on our benchmark datasets, utilizing key retrieval (MRR, Recall@K, NDCG@K) and text generation (BLEU, ROUGE, METEOR) metrics, reveal that our method outperforms the baseline by 77.6% in MRR and by 0.32 in BLEU. Our method has been deployed within LinkedIn's customer service team for approximately six months and has reduced the median per-issue resolution time by 28.6%.
AlerTiger: Deep Learning for AI Model Health Monitoring at LinkedIn
Jun 03, 2023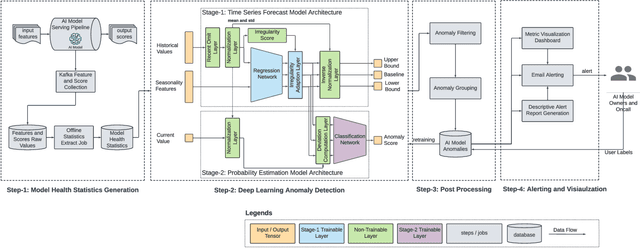
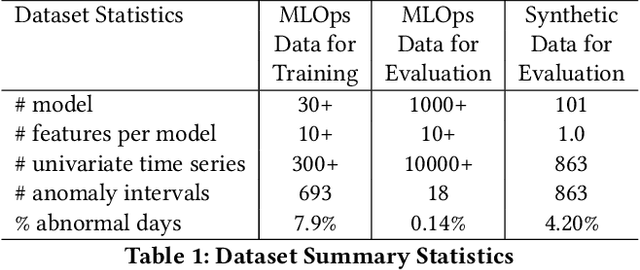
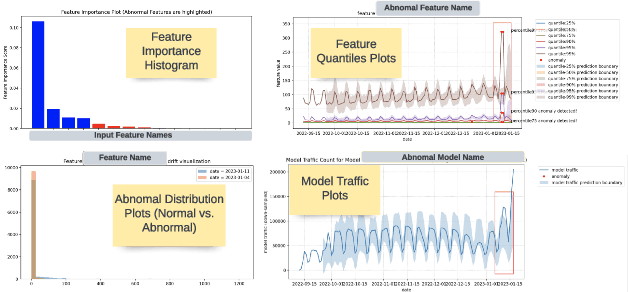
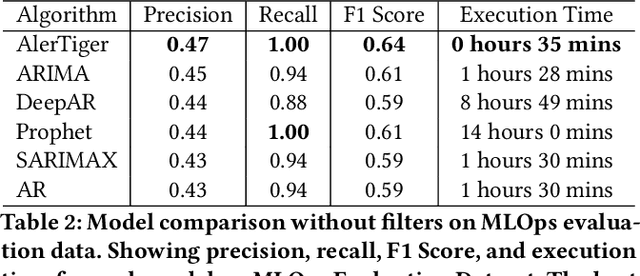
Data-driven companies use AI models extensively to develop products and intelligent business solutions, making the health of these models crucial for business success. Model monitoring and alerting in industries pose unique challenges, including a lack of clear model health metrics definition, label sparsity, and fast model iterations that result in short-lived models and features. As a product, there are also requirements for scalability, generalizability, and explainability. To tackle these challenges, we propose AlerTiger, a deep-learning-based MLOps model monitoring system that helps AI teams across the company monitor their AI models' health by detecting anomalies in models' input features and output score over time. The system consists of four major steps: model statistics generation, deep-learning-based anomaly detection, anomaly post-processing, and user alerting. Our solution generates three categories of statistics to indicate AI model health, offers a two-stage deep anomaly detection solution to address label sparsity and attain the generalizability of monitoring new models, and provides holistic reports for actionable alerts. This approach has been deployed to most of LinkedIn's production AI models for over a year and has identified several model issues that later led to significant business metric gains after fixing.
Simultaneous Relevance and Diversity: A New Recommendation Inference Approach
Sep 27, 2020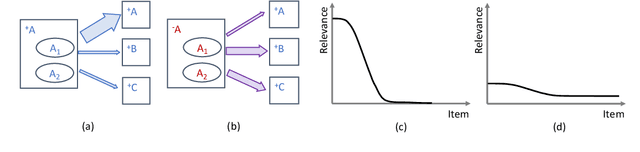
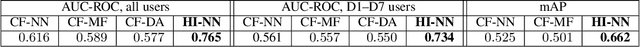
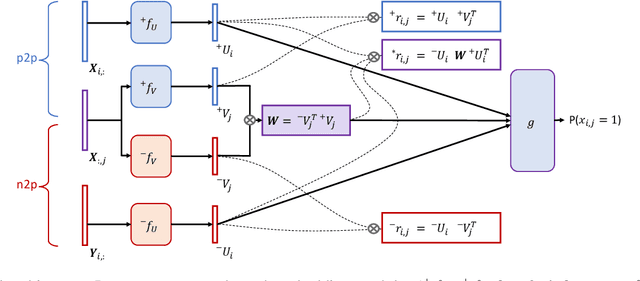
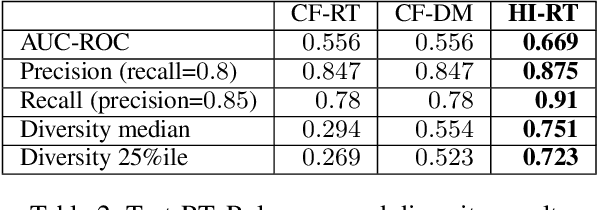
Relevance and diversity are both important to the success of recommender systems, as they help users to discover from a large pool of items a compact set of candidates that are not only interesting but exploratory as well. The challenge is that relevance and diversity usually act as two competing objectives in conventional recommender systems, which necessities the classic trade-off between exploitation and exploration. Traditionally, higher diversity often means sacrifice on relevance and vice versa. We propose a new approach, heterogeneous inference, which extends the general collaborative filtering (CF) by introducing a new way of CF inference, negative-to-positive. Heterogeneous inference achieves divergent relevance, where relevance and diversity support each other as two collaborating objectives in one recommendation model, and where recommendation diversity is an inherent outcome of the relevance inference process. Benefiting from its succinctness and flexibility, our approach is applicable to a wide range of recommendation scenarios/use-cases at various sophistication levels. Our analysis and experiments on public datasets and real-world production data show that our approach outperforms existing methods on relevance and diversity simultaneously.