 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-OCTA2: Layer Sequence OCTA Segmentation with Fine-tuned Segment Anything Model 2
Sep 14, 2024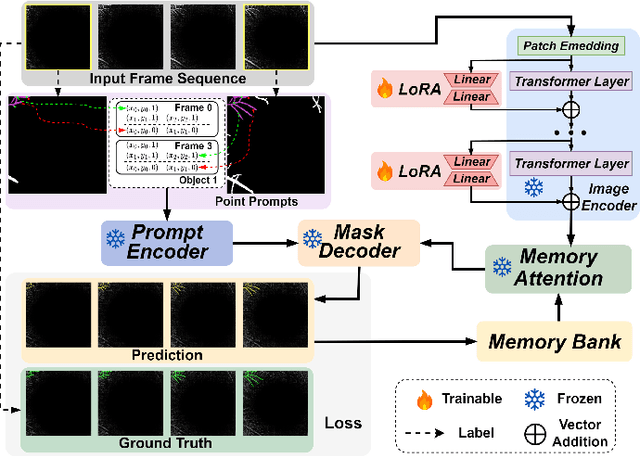
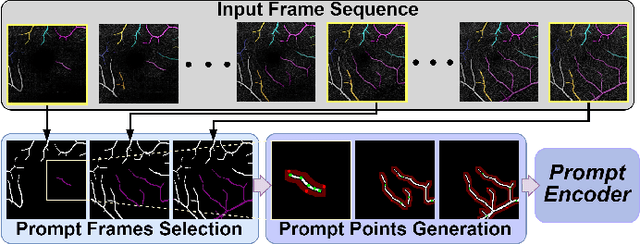
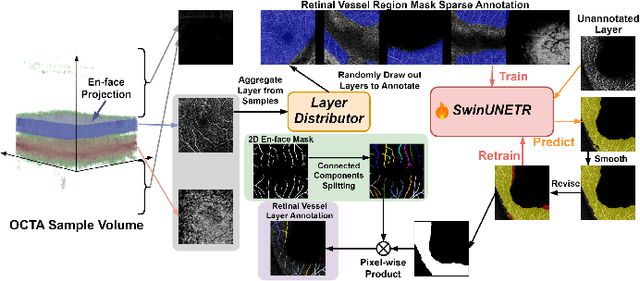
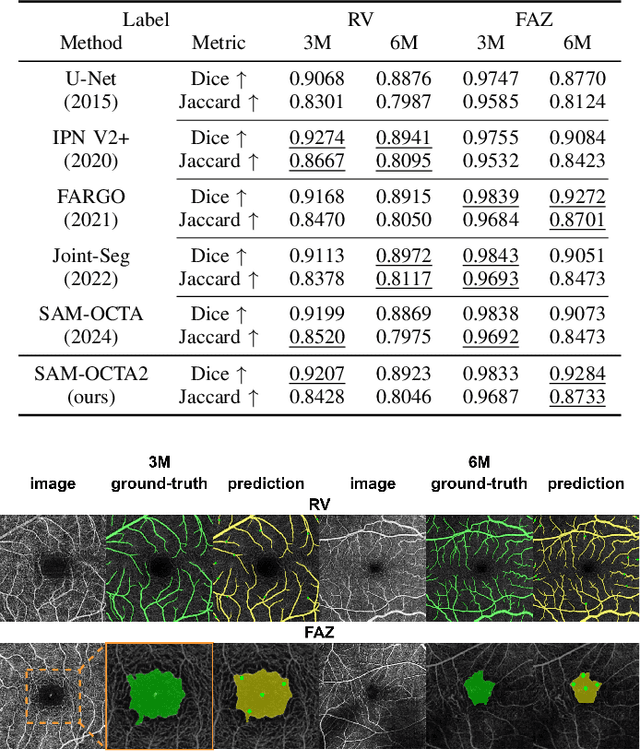
Segmentation of indicated targets aids in the precise analysis of optical coherence tomography angiography (OCTA) samples. Existing segmentation methods typically perform on 2D projection targets, making it challenging to capture the variance of segmented objects through the 3D volume. To address this limitation, the low-rank adaptation technique is adopted to fine-tune the Segment Anything Model (SAM) version 2, enabling the tracking and segmentation of specified objects across the OCTA scanning layer sequence. To further this work, a prompt point generation strategy in frame sequence and a sparse annotation method to acquire retinal vessel (RV) layer masks are proposed. This method is named SAM-OCTA2 and has been experimented on the OCTA-500 dataset. It achieves state-of-the-art performance in segmenting the foveal avascular zone (FAZ) on regular 2D en-face and effectively tracks local vessels across scanning layer sequences. The code is available at: https://github.com/ShellRedia/SAM-OCTA2.
PillarNeXt: Improving the 3D detector by introducing Voxel2Pillar feature encoding and extracting multi-scale features
May 16, 2024Multi-line LiDAR is widely used in autonomous vehicles, so point cloud-based 3D detectors are essential for autonomous driving. Extracting rich multi-scale features is crucial for point cloud-based 3D detectors in autonomous driving due to significant differences in the size of different types of objects. However, due to the real-time requirements, large-size convolution kernels are rarely used to extract large-scale features in the backbone. Current 3D detectors commonly use feature pyramid networks to obtain large-scale features; however, some objects containing fewer point clouds are further lost during downsampling, resulting in degraded performance. Since pillar-based schemes require much less computation than voxel-based schemes, they are more suitable for constructing real-time 3D detectors. Hence, we propose PillarNeXt, a pillar-based scheme. We redesigned the feature encoding, the backbone, and the neck of the 3D detector. We propose Voxel2Pillar feature encoding, which uses a sparse convolution constructor to construct pillars with richer point cloud features, especially height features. Moreover, additional learnable parameters are added, which enables the initial pillar to achieve higher performance capabilities. We extract multi-scale and large-scale features in the proposed fully sparse backbone, which does not utilize large-size convolutional kernels; the backbone consists of the proposed multi-scale feature extraction module. The neck consists of the proposed sparse ConvNeXt, whose simple structure significantly improves the performance. The effectiveness of the proposed PillarNeXt is validated on the Waymo Open Dataset, and object detection accuracy for vehicles, pedestrians, and cyclists is improved; we also verify the effectiveness of each proposed module in detail.
Snake with Shifted Window: Learning to Adapt Vessel Pattern for OCTA Segmentation
Apr 28, 2024Segmenting specific targets or structures in optical coherence tomography angiography (OCTA) images is fundamental for conducting further pathological studies. The retinal vascular layers are rich and intricate, and such vascular with complex shapes can be captured by the widely-studied OCTA images. In this paper, we thus study how to use OCTA images with projection vascular layers to segment retinal structures. To this end, we propose the SSW-OCTA model, which integrates the advantages of deformable convolutions suited for tubular structures and the swin-transformer for global feature extraction, adapting to the characteristics of OCTA modality images. Our model underwent testing and comparison on the OCTA-500 dataset, achieving state-of-the-art performance. The code is available at: https://github.com/ShellRedia/Snake-SWin-OCTA.
SAM-OCTA: Prompting Segment-Anything for OCTA Image Segmentation
Oct 11, 2023In the analysis of optical coherence tomography angiography (OCTA) images, the operation of segmenting specific targets is necessary. Existing methods typically train on supervised datasets with limited samples (approximately a few hundred), which can lead to overfitting. To address this, the low-rank adaptation technique is adopted for foundation model fine-tuning and proposed corresponding prompt point generation strategies to process various segmentation tasks on OCTA datasets. This method is named SAM-OCTA and has been experimented on the publicly available OCTA-500 and ROSE datasets. This method achieves or approaches state-of-the-art segmentation performance metrics. The effect and applicability of prompt points are discussed in detail for the retinal vessel, foveal avascular zone, capillary, artery, and vein segmentation tasks. Furthermore, SAM-OCTA accomplishes local vessel segmentation and effective artery-vein segmentation, which was not well-solved in previous works. The code is available at https://github.com/ShellRedia/SAM-OCTA.
SAM-OCTA: A Fine-Tuning Strategy for Applying Foundation Model to OCTA Image Segmentation Tasks
Sep 21, 2023In the analysis of optical coherence tomography angiography (OCTA) images, the operation of segmenting specific targets is necessary. Existing methods typically train on supervised datasets with limited samples (approximately a few hundred), which can lead to overfitting. To address this, the low-rank adaptation technique is adopted for foundation model fine-tuning and proposed corresponding prompt point generation strategies to process various segmentation tasks on OCTA datasets. This method is named SAM-OCTA and has been experimented on the publicly available OCTA-500 dataset. While achieving state-of-the-art performance metrics, this method accomplishes local vessel segmentation as well as effective artery-vein segmentation, which was not well-solved in previous works. The code is available at: https://github.com/ShellRedia/SAM-OCTA.
An Accurate and Efficient Neural Network for OCTA Vessel Segmentation and a New Dataset
Sep 18, 2023



Optical coherence tomography angiography (OCTA) is a noninvasive imaging technique that can reveal high-resolution retinal vessels. In this work, we propose an accurate and efficient neural network for retinal vessel segmentation in OCTA images. The proposed network achieves accuracy comparable to other SOTA methods, while having fewer parameters and faster inference speed (e.g. 110x lighter and 1.3x faster than U-Net), which is very friendly for industrial applications. This is achieved by applying the modified Recurrent ConvNeXt Block to a full resolution convolutional network. In addition, we create a new dataset containing 918 OCTA images and their corresponding vessel annotations. The data set is semi-automatically annotated with the help of Segment Anything Model (SAM), which greatly improves the annotation speed. For the benefit of the community, our code and dataset can be obtained from https://github.com/nhjydywd/OCTA-FRNet.
CSAFL: A Clustered Semi-Asynchronous Federated Learning Framework
Apr 16, 2021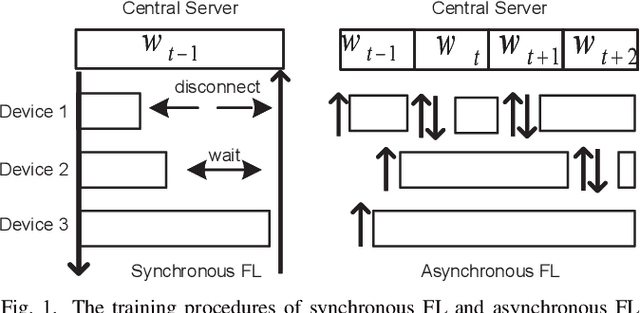
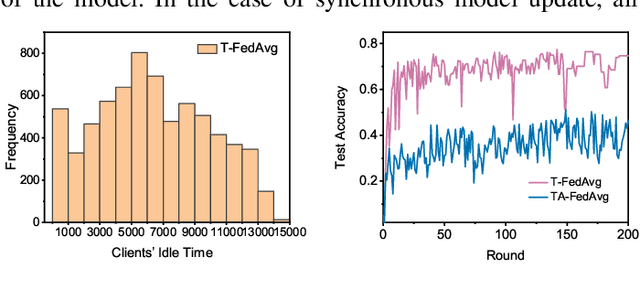
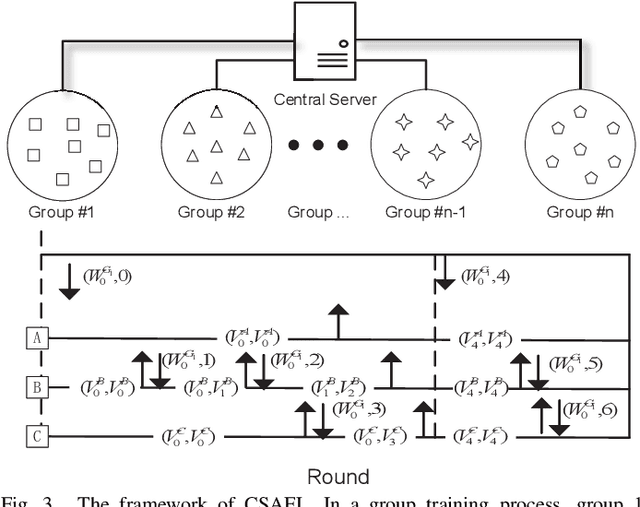
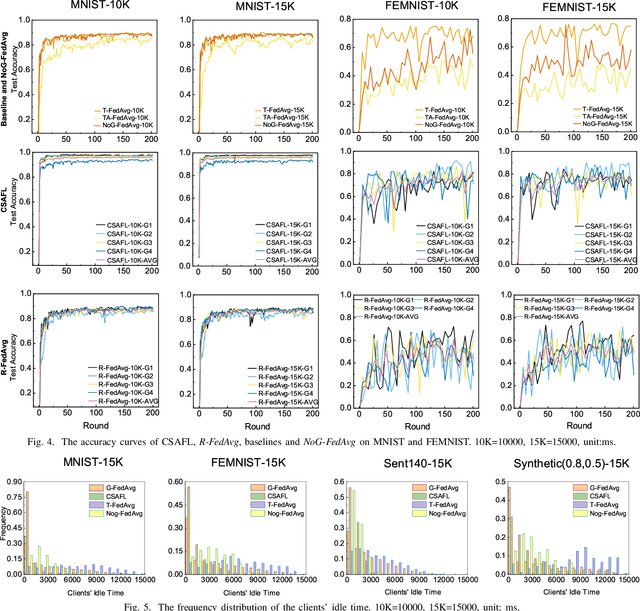
Federated learning (FL) is an emerging distributed machine learning paradigm that protects privacy and tackles the problem of isolated data islands. At present, there are two main communication strategies of FL: synchronous FL and asynchronous FL. The advantages of synchronous FL are that the model has high precision and fast convergence speed. However, this synchronous communication strategy has the risk that the central server waits too long for the devices, namely, the straggler effect which has a negative impact on some time-critical applications. Asynchronous FL has a natural advantage in mitigating the straggler effect, but there are threats of model quality degradation and server crash. Therefore, we combine the advantages of these two strategies to propose a clustered semi-asynchronous federated learning (CSAFL) framework. We evaluate CSAFL based on four imbalanced federated datasets in a non-IID setting and compare CSAFL to the baseline methods. The experimental results show that CSAFL significantly improves test accuracy by more than +5% on the four datasets compared to TA-FedAvg. In particular, CSAFL improves absolute test accuracy by +34.4% on non-IID FEMNIST compared to TA-FedAvg.
FedSAE: A Novel Self-Adaptive Federated Learning Framework in Heterogeneous Systems
Apr 15, 2021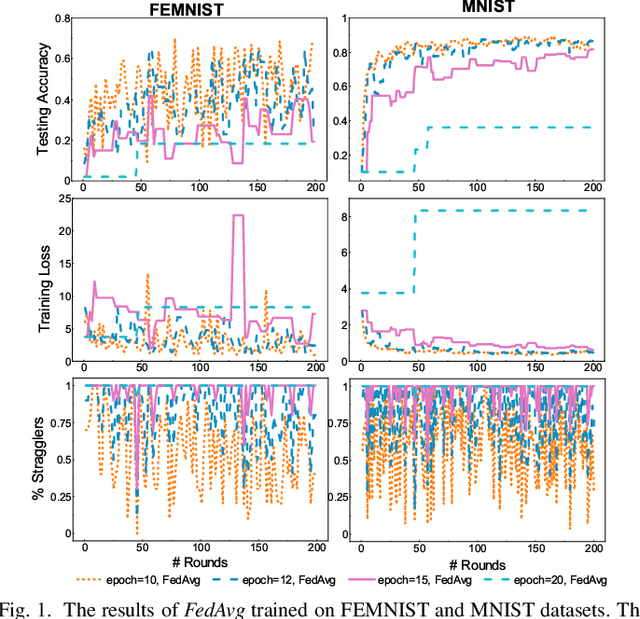
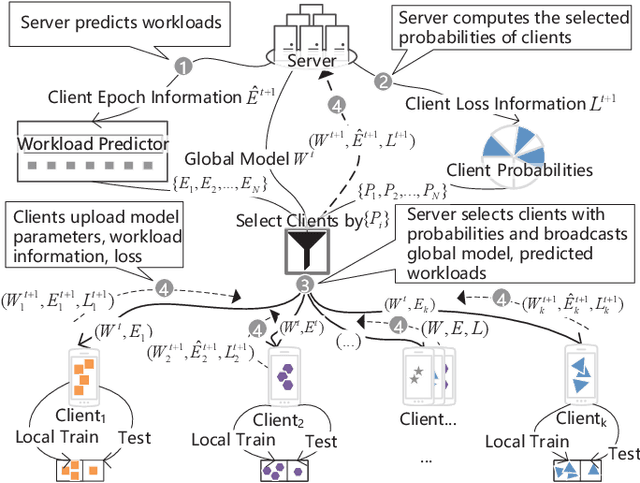
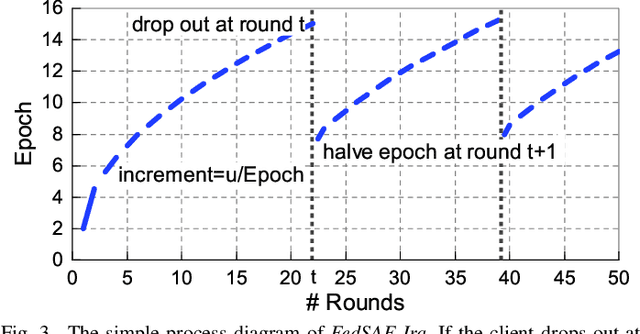
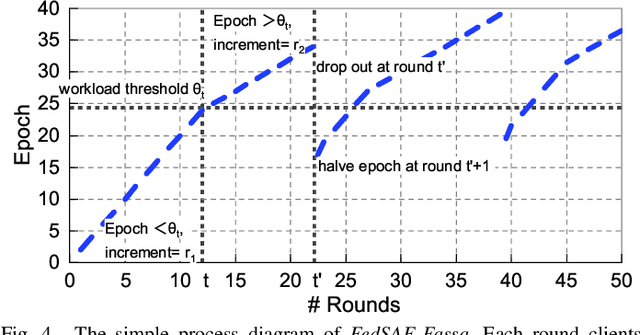
Federated Learning (FL) is a novel distributed machine learning which allows thousands of edge devices to train model locally without uploading data concentrically to the server. But since real federated settings are resource-constrained, FL is encountered with systems heterogeneity which causes a lot of stragglers directly and then leads to significantly accuracy reduction indirectly. To solve the problems caused by systems heterogeneity, we introduce a novel self-adaptive federated framework FedSAE which adjusts the training task of devices automatically and selects participants actively to alleviate the performance degradation. In this work, we 1) propose FedSAE which leverages the complete information of devices' historical training tasks to predict the affordable training workloads for each device. In this way, FedSAE can estimate the reliability of each device and self-adaptively adjust the amount of training load per client in each round. 2) combine our framework with Active Learning to self-adaptively select participants. Then the framework accelerates the convergence of the global model. In our framework, the server evaluates devices' value of training based on their training loss. Then the server selects those clients with bigger value for the global model to reduce communication overhead. The experimental result indicates that in a highly heterogeneous system, FedSAE converges faster than FedAvg, the vanilla FL framework. Furthermore, FedSAE outperforms than FedAvg on several federated datasets - FedSAE improves test accuracy by 26.7% and reduces stragglers by 90.3% on average.
PoTrojan: powerful neural-level trojan designs in deep learning models
Feb 08, 2018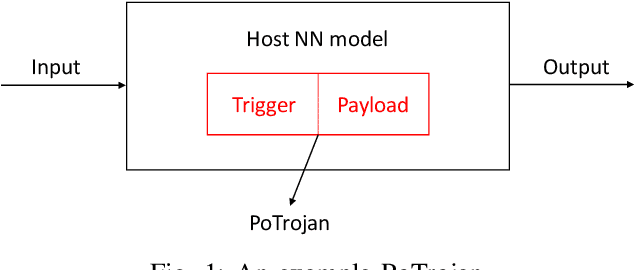
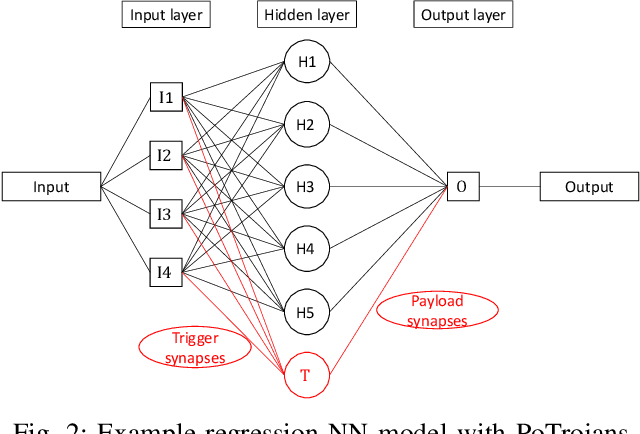
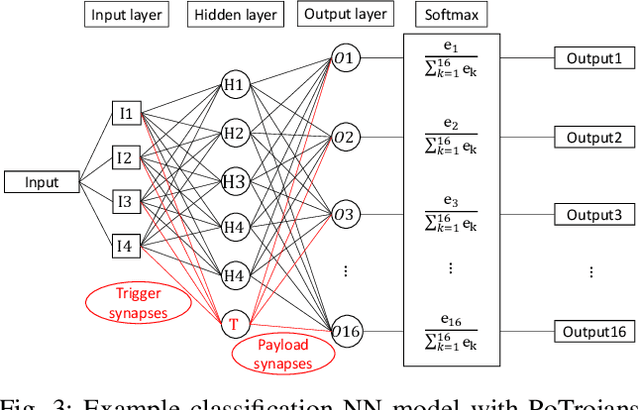
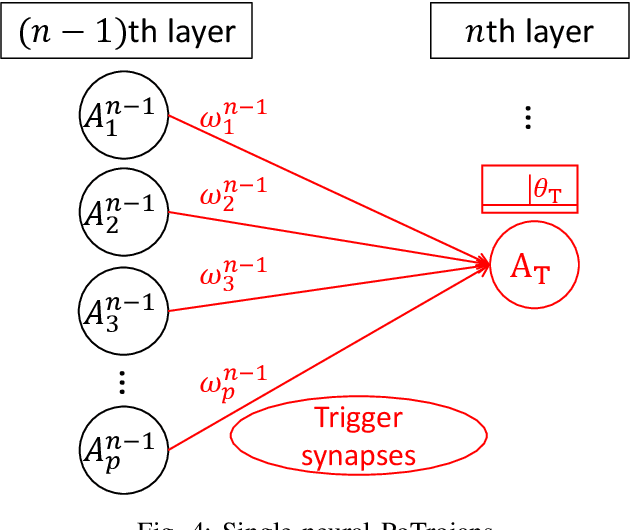
With the popularity of deep learning (DL), artificial intelligence (AI) has been applied in many areas of human life. Neural network or artificial neural network (NN), the main technique behind DL, has been extensively studied to facilitate computer vision and natural language recognition. However, the more we rely on information technology, the more vulnerable we are. That is, malicious NNs could bring huge threat in the so-called coming AI era. In this paper, for the first time in the literature, we propose a novel approach to design and insert powerful neural-level trojans or PoTrojan in pre-trained NN models. Most of the time, PoTrojans remain inactive, not affecting the normal functions of their host NN models. PoTrojans could only be triggered in very rare conditions. Once activated, however, the PoTrojans could cause the host NN models to malfunction, either falsely predicting or classifying, which is a significant threat to human society of the AI era. We would explain the principles of PoTrojans and the easiness of designing and inserting them in pre-trained deep learning models. PoTrojans doesn't modify the existing architecture or parameters of the pre-trained models, without re-training. Hence, the proposed method is very efficient.