 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-OCTA2: Layer Sequence OCTA Segmentation with Fine-tuned Segment Anything Model 2
Sep 14, 2024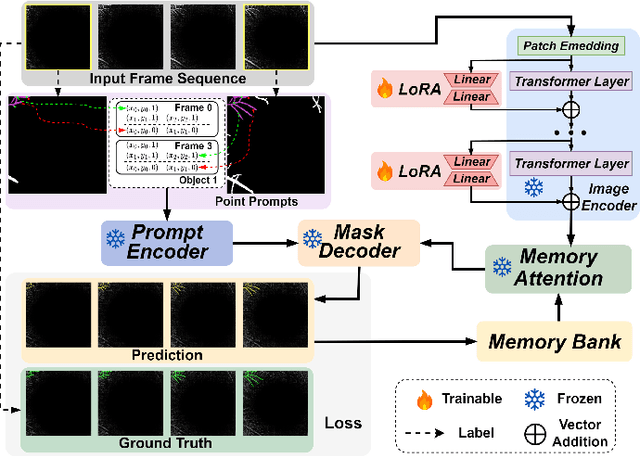
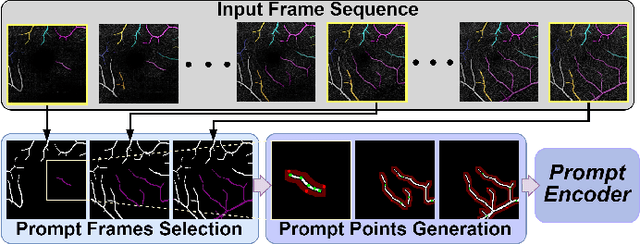
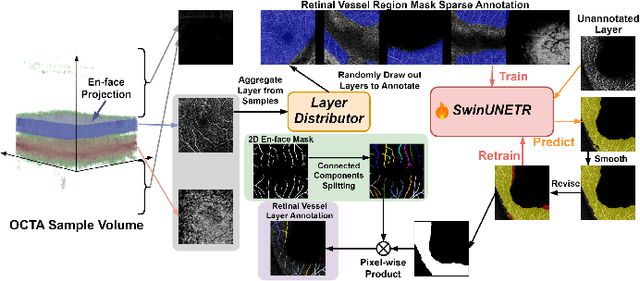
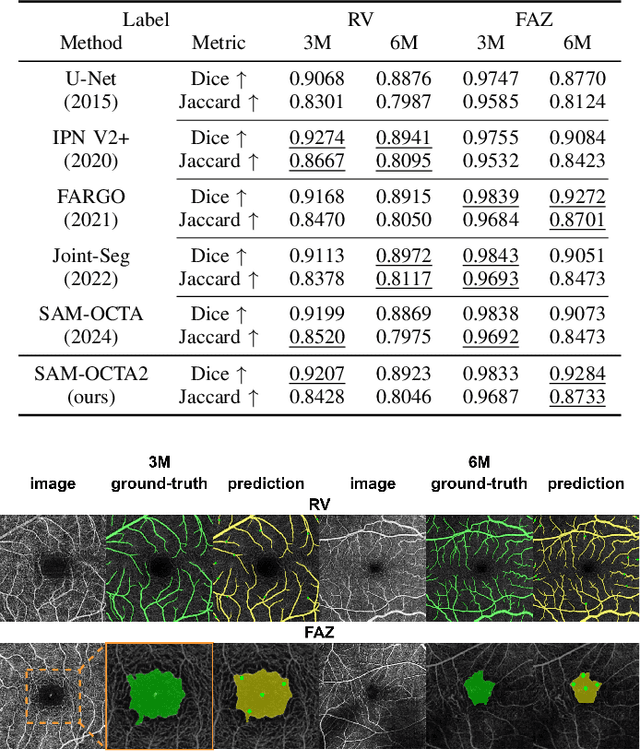
Segmentation of indicated targets aids in the precise analysis of optical coherence tomography angiography (OCTA) samples. Existing segmentation methods typically perform on 2D projection targets, making it challenging to capture the variance of segmented objects through the 3D volume. To address this limitation, the low-rank adaptation technique is adopted to fine-tune the Segment Anything Model (SAM) version 2, enabling the tracking and segmentation of specified objects across the OCTA scanning layer sequence. To further this work, a prompt point generation strategy in frame sequence and a sparse annotation method to acquire retinal vessel (RV) layer masks are proposed. This method is named SAM-OCTA2 and has been experimented on the OCTA-500 dataset. It achieves state-of-the-art performance in segmenting the foveal avascular zone (FAZ) on regular 2D en-face and effectively tracks local vessels across scanning layer sequences. The code is available at: https://github.com/ShellRedia/SAM-OCTA2.
Snake with Shifted Window: Learning to Adapt Vessel Pattern for OCTA Segmentation
Apr 28, 2024Segmenting specific targets or structures in optical coherence tomography angiography (OCTA) images is fundamental for conducting further pathological studies. The retinal vascular layers are rich and intricate, and such vascular with complex shapes can be captured by the widely-studied OCTA images. In this paper, we thus study how to use OCTA images with projection vascular layers to segment retinal structures. To this end, we propose the SSW-OCTA model, which integrates the advantages of deformable convolutions suited for tubular structures and the swin-transformer for global feature extraction, adapting to the characteristics of OCTA modality images. Our model underwent testing and comparison on the OCTA-500 dataset, achieving state-of-the-art performance. The code is available at: https://github.com/ShellRedia/Snake-SWin-OCTA.