 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-OCTA2: Layer Sequence OCTA Segmentation with Fine-tuned Segment Anything Model 2
Sep 14, 2024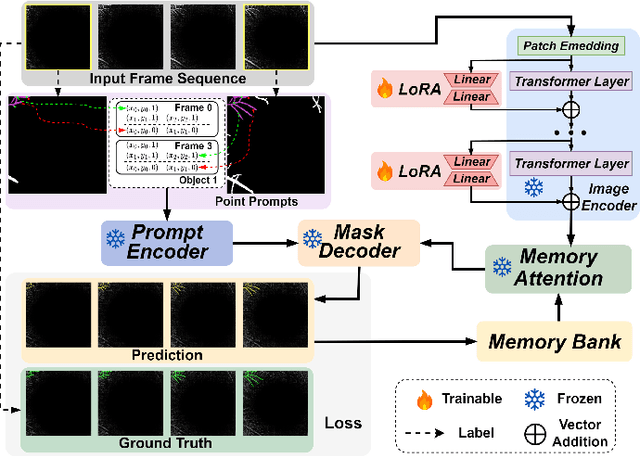
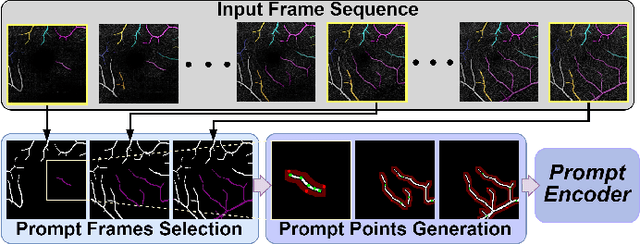
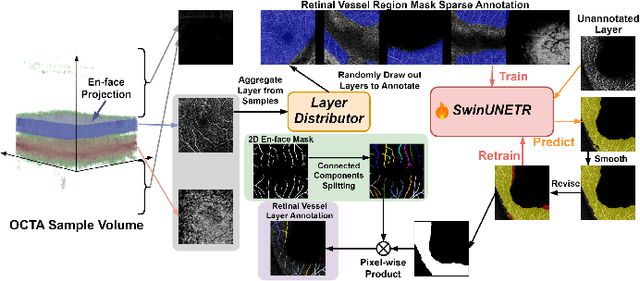
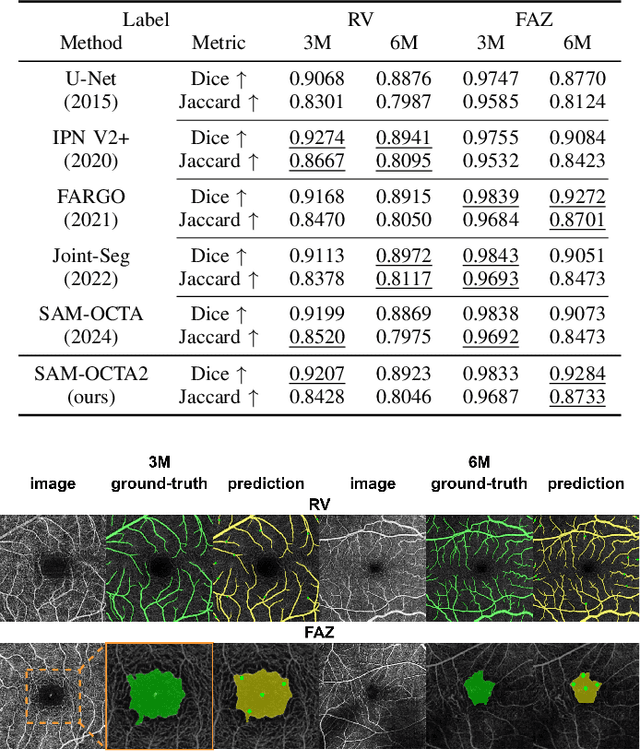
Segmentation of indicated targets aids in the precise analysis of optical coherence tomography angiography (OCTA) samples. Existing segmentation methods typically perform on 2D projection targets, making it challenging to capture the variance of segmented objects through the 3D volume. To address this limitation, the low-rank adaptation technique is adopted to fine-tune the Segment Anything Model (SAM) version 2, enabling the tracking and segmentation of specified objects across the OCTA scanning layer sequence. To further this work, a prompt point generation strategy in frame sequence and a sparse annotation method to acquire retinal vessel (RV) layer masks are proposed. This method is named SAM-OCTA2 and has been experimented on the OCTA-500 dataset. It achieves state-of-the-art performance in segmenting the foveal avascular zone (FAZ) on regular 2D en-face and effectively tracks local vessels across scanning layer sequences. The code is available at: https://github.com/ShellRedia/SAM-OCTA2.
Snake with Shifted Window: Learning to Adapt Vessel Pattern for OCTA Segmentation
Apr 28, 2024Segmenting specific targets or structures in optical coherence tomography angiography (OCTA) images is fundamental for conducting further pathological studies. The retinal vascular layers are rich and intricate, and such vascular with complex shapes can be captured by the widely-studied OCTA images. In this paper, we thus study how to use OCTA images with projection vascular layers to segment retinal structures. To this end, we propose the SSW-OCTA model, which integrates the advantages of deformable convolutions suited for tubular structures and the swin-transformer for global feature extraction, adapting to the characteristics of OCTA modality images. Our model underwent testing and comparison on the OCTA-500 dataset, achieving state-of-the-art performance. The code is available at: https://github.com/ShellRedia/Snake-SWin-OCTA.
SAM-OCTA: Prompting Segment-Anything for OCTA Image Segmentation
Oct 11, 2023In the analysis of optical coherence tomography angiography (OCTA) images, the operation of segmenting specific targets is necessary. Existing methods typically train on supervised datasets with limited samples (approximately a few hundred), which can lead to overfitting. To address this, the low-rank adaptation technique is adopted for foundation model fine-tuning and proposed corresponding prompt point generation strategies to process various segmentation tasks on OCTA datasets. This method is named SAM-OCTA and has been experimented on the publicly available OCTA-500 and ROSE datasets. This method achieves or approaches state-of-the-art segmentation performance metrics. The effect and applicability of prompt points are discussed in detail for the retinal vessel, foveal avascular zone, capillary, artery, and vein segmentation tasks. Furthermore, SAM-OCTA accomplishes local vessel segmentation and effective artery-vein segmentation, which was not well-solved in previous works. The code is available at https://github.com/ShellRedia/SAM-OCTA.
SAM-OCTA: A Fine-Tuning Strategy for Applying Foundation Model to OCTA Image Segmentation Tasks
Sep 21, 2023In the analysis of optical coherence tomography angiography (OCTA) images, the operation of segmenting specific targets is necessary. Existing methods typically train on supervised datasets with limited samples (approximately a few hundred), which can lead to overfitting. To address this, the low-rank adaptation technique is adopted for foundation model fine-tuning and proposed corresponding prompt point generation strategies to process various segmentation tasks on OCTA datasets. This method is named SAM-OCTA and has been experimented on the publicly available OCTA-500 dataset. While achieving state-of-the-art performance metrics, this method accomplishes local vessel segmentation as well as effective artery-vein segmentation, which was not well-solved in previous works. The code is available at: https://github.com/ShellRedia/SAM-OCTA.
An Accurate and Efficient Neural Network for OCTA Vessel Segmentation and a New Dataset
Sep 18, 2023



Optical coherence tomography angiography (OCTA) is a noninvasive imaging technique that can reveal high-resolution retinal vessels. In this work, we propose an accurate and efficient neural network for retinal vessel segmentation in OCTA images. The proposed network achieves accuracy comparable to other SOTA methods, while having fewer parameters and faster inference speed (e.g. 110x lighter and 1.3x faster than U-Net), which is very friendly for industrial applications. This is achieved by applying the modified Recurrent ConvNeXt Block to a full resolution convolutional network. In addition, we create a new dataset containing 918 OCTA images and their corresponding vessel annotations. The data set is semi-automatically annotated with the help of Segment Anything Model (SAM), which greatly improves the annotation speed. For the benefit of the community, our code and dataset can be obtained from https://github.com/nhjydywd/OCTA-FRNet.