 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedFixer: Mitigating Heterogeneous Label Noise in Federated Learning
Mar 25, 2024Federated Learning (FL) heavily depends on label quality for its performance. However, the label distribution among individual clients is always both noisy and heterogeneous. The high loss incurred by client-specific samples in heterogeneous label noise poses challenges for distinguishing between client-specific and noisy label samples, impacting the effectiveness of existing label noise learning approaches. To tackle this issue, we propose FedFixer, where the personalized model is introduced to cooperate with the global model to effectively select clean client-specific samples. In the dual models, updating the personalized model solely at a local level can lead to overfitting on noisy data due to limited samples, consequently affecting both the local and global models' performance. To mitigate overfitting, we address this concern from two perspectives. Firstly, we employ a confidence regularizer to alleviate the impact of unconfident predictions caused by label noise. Secondly, a distance regularizer is implemented to constrain the disparity between the personalized and global models. We validate the effectiveness of FedFixer through extensive experiments on benchmark datasets. The results demonstrate that FedFixer can perform well in filtering noisy label samples on different clients, especially in highly heterogeneous label noise scenarios.
Meta Generative Flow Networks with Personalization for Task-Specific Adaptation
Jun 16, 2023Multi-task reinforcement learning and meta-reinforcement learning have been developed to quickly adapt to new tasks, but they tend to focus on tasks with higher rewards and more frequent occurrences, leading to poor performance on tasks with sparse rewards. To address this issue, GFlowNets can be integrated into meta-learning algorithms (GFlowMeta) by leveraging the advantages of GFlowNets on tasks with sparse rewards. However, GFlowMeta suffers from performance degradation when encountering heterogeneous transitions from distinct tasks. To overcome this challenge, this paper proposes a personalized approach named pGFlowMeta, which combines task-specific personalized policies with a meta policy. Each personalized policy balances the loss on its personalized task and the difference from the meta policy, while the meta policy aims to minimize the average loss of all tasks. The theoretical analysis shows that the algorithm converges at a sublinear rate. Extensive experiments demonstrate that the proposed algorithm outperforms state-of-the-art reinforcement learning algorithms in discrete environments.
Federated Generalized Category Discovery
May 23, 2023



Generalized category discovery (GCD) aims at grouping unlabeled samples from known and unknown classes, given labeled data of known classes. To meet the recent decentralization trend in the community, we introduce a practical yet challenging task, namely Federated GCD (Fed-GCD), where the training data are distributively stored in local clients and cannot be shared among clients. The goal of Fed-GCD is to train a generic GCD model by client collaboration under the privacy-protected constraint. The Fed-GCD leads to two challenges: 1) representation degradation caused by training each client model with fewer data than centralized GCD learning, and 2) highly heterogeneous label spaces across different clients. To this end, we propose a novel Associated Gaussian Contrastive Learning (AGCL) framework based on learnable GMMs, which consists of a Client Semantics Association (CSA) and a global-local GMM Contrastive Learning (GCL). On the server, CSA aggregates the heterogeneous categories of local-client GMMs to generate a global GMM containing more comprehensive category knowledge. On each client, GCL builds class-level contrastive learning with both local and global GMMs. The local GCL learns robust representation with limited local data. The global GCL encourages the model to produce more discriminative representation with the comprehensive category relationships that may not exist in local data. We build a benchmark based on six visual datasets to facilitate the study of Fed-GCD. Extensive experiments show that our AGCL outperforms the FedAvg-based baseline on all datasets.
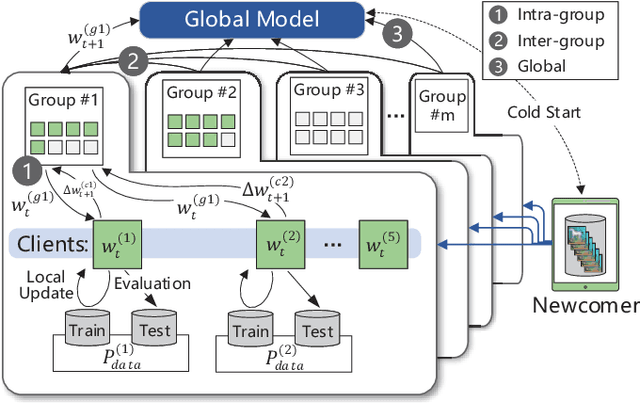
Flexible Clustered Federated Learning for Client-Level Data Distribution Shift
Aug 22, 2021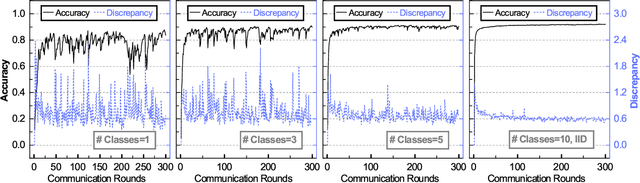
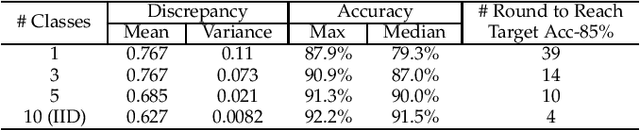
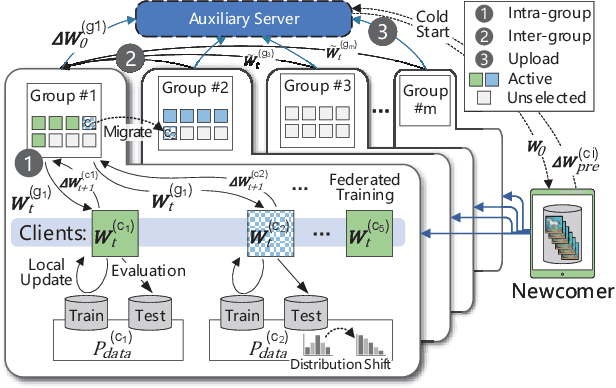
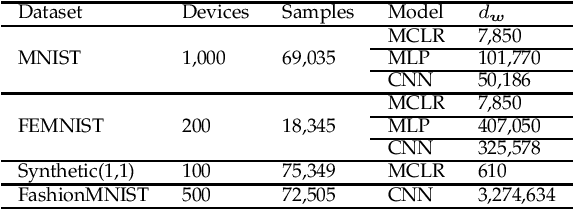
Federated Learning (FL) enables the multiple participating devices to collaboratively contribute to a global neural network model while keeping the training data locally. Unlike the centralized training setting, the non-IID, imbalanced (statistical heterogeneity) and distribution shifted training data of FL is distributed in the federated network, which will increase the divergences between the local models and the global model, further degrading performance. In this paper, we propose a flexible clustered federated learning (CFL) framework named FlexCFL, in which we 1) group the training of clients based on the similarities between the clients' optimization directions for lower training divergence; 2) implement an efficient newcomer device cold start mechanism for framework scalability and practicality; 3) flexibly migrate clients to meet the challenge of client-level data distribution shift. FlexCFL can achieve improvements by dividing joint optimization into groups of sub-optimization and can strike a balance between accuracy and communication efficiency in the distribution shift environment. The convergence and complexity are analyzed to demonstrate the efficiency of FlexCFL. We also evaluate FlexCFL on several open datasets and made comparisons with related CFL frameworks. The results show that FlexCFL can significantly improve absolute test accuracy by +10.6% on FEMNIST compared to FedAvg, +3.5% on FashionMNIST compared to FedProx, +8.4% on MNIST compared to FeSEM. The experiment results show that FlexCFL is also communication efficient in the distribution shift environment.
FedGroup: Ternary Cosine Similarity-based Clustered Federated Learning Framework toward High Accuracy in Heterogeneous Data
Oct 15, 2020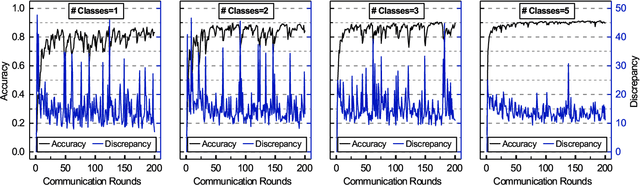
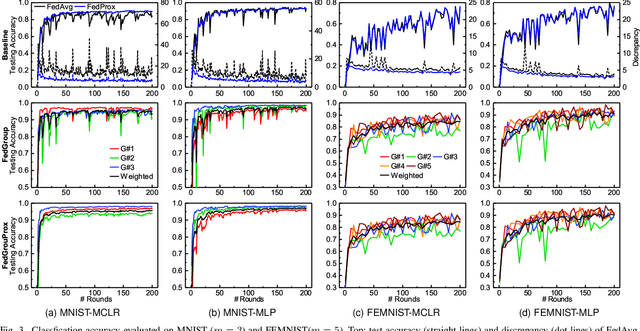
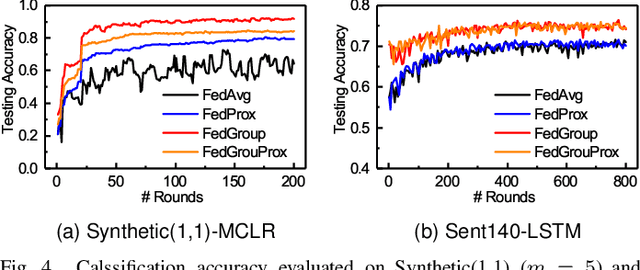
Federated Learning (FL) enables the multiple participating devices to collaboratively contribute to a global neural network model while keeping the training data locally. Unlike the centralized training setting, the non-IID and imbalanced (statistical heterogeneity) training data of FL is distributed in the federated network, which will increase the divergences between the local models and global model and further degrade the performance. In this paper, we propose a novel federated learning framework FedGroup based on a similarity-based clustering strategy, in which we 1) group the training of clients based on the similarities between the clients' optimize directions; 2) reduce the complexity of high-dimension low-sample size (HDLSS) parameter updates data clustering by decomposing the direction vectors to derive the ternary cosine similarity. FedGroup can achieve improvements by dividing joint optimization into groups of sub-optimization, and can be combined with FedProx, the state-of-the-art federated optimization algorithm. We evaluate FedGroup and FedGrouProx (combined with FedProx) on several open datasets. The experimental results show that our proposed frameworks significantly improving absolute test accuracy by +14.7% on FEMNIST compared to FedAvg, +5.4% on Sentiment140 compared to FedProx.